 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorld-Value-Action Model: Implicit Planning for Vision-Language-Action Systems
Apr 16, 2026Vision-Language-Action (VLA) models have emerged as a promising paradigm for building embodied agents that ground perception and language into action. However, most existing approaches rely on direct action prediction, lacking the ability to reason over long-horizon trajectories and evaluate their consequences, which limits performance in complex decision-making tasks. In this work, we introduce World-Value-Action (WAV) model, a unified framework that enables implicit planning in VLA systems. Rather than performing explicit trajectory optimization, WAV model learn a structured latent representation of future trajectories conditioned on visual observations and language instructions. A learned world model predicts future states, while a trajectory value function evaluates their long-horizon utility. Action generation is then formulated as inference in this latent space, where the model progressively concentrates probability mass on high-value and dynamically feasible trajectories. We provide a theoretical perspective showing that planning directly in action space suffers from an exponential decay in the probability of feasible trajectories as the horizon increases. In contrast, latent-space inference reshapes the search distribution toward feasible regions, enabling efficient long-horizon decision making. Extensive simulations and real-world experiments demonstrate that the WAV model consistently outperforms state-of-the-art methods, achieving significant improvements in task success rate, generalization ability, and robustness, especially in long-horizon and compositional scenarios.
MMaDA-VLA: Large Diffusion Vision-Language-Action Model with Unified Multi-Modal Instruction and Generation
Mar 27, 2026Vision-Language-Action (VLA) models aim to control robots for manipulation from visual observations and natural-language instructions. However, existing hierarchical and autoregressive paradigms often introduce architectural overhead, suffer from temporal inconsistency and long-horizon error accumulation, and lack a mechanism to capture environment dynamics without extra modules. To this end, we present MMaDA-VLA, a fully native pre-trained large diffusion VLA model that unifies multi-modal understanding and generation in a single framework. Our key idea is a native discrete diffusion formulation that embeds language, images, and continuous robot controls into one discrete token space and trains a single backbone with masked token denoising to jointly generate a future goal observation and an action chunk in parallel. Iterative denoising enables global, order-free refinement, improving long-horizon consistency while grounding actions in predicted future visual outcomes without auxiliary world models. Experiments across simulation benchmarks and real-world tasks show state-of-the-art performance, achieving 98.0% average success on LIBERO and 4.78 average length on CALVIN.
CMR: Contractive Mapping Embeddings for Robust Humanoid Locomotion on Unstructured Terrains
Feb 03, 2026Robust disturbance rejection remains a longstanding challenge in humanoid locomotion, particularly on unstructured terrains where sensing is unreliable and model mismatch is pronounced. While perception information, such as height map, enhances terrain awareness, sensor noise and sim-to-real gaps can destabilize policies in practice. In this work, we provide theoretical analysis that bounds the return gap under observation noise, when the induced latent dynamics are contractive. Furthermore, we present Contractive Mapping for Robustness (CMR) framework that maps high-dimensional, disturbance-prone observations into a latent space, where local perturbations are attenuated over time. Specifically, this approach couples contrastive representation learning with Lipschitz regularization to preserve task-relevant geometry while explicitly controlling sensitivity. Notably, the formulation can be incorporated into modern deep reinforcement learning pipelines as an auxiliary loss term with minimal additional technical effort required. Further, our extensive humanoid experiments show that CMR potently outperforms other locomotion algorithms under increased noise.
CRL-VLA: Continual Vision-Language-Action Learning
Feb 03, 2026Lifelong learning is critical for embodied agents in open-world environments, where reinforcement learning fine-tuning has emerged as an important paradigm to enable Vision-Language-Action (VLA) models to master dexterous manipulation through environmental interaction. Thus, Continual Reinforcement Learning (CRL) is a promising pathway for deploying VLA models in lifelong robotic scenarios, yet balancing stability (retaining old skills) and plasticity (learning new ones) remains a formidable challenge for existing methods. We introduce CRL-VLA, a framework for continual post-training of VLA models with rigorous theoretical bounds. We derive a unified performance bound linking the stability-plasticity trade-off to goal-conditioned advantage magnitude, scaled by policy divergence. CRL-VLA resolves this dilemma via asymmetric regulation: constraining advantage magnitudes on prior tasks while enabling controlled growth on new tasks. This is realized through a simple but effective dual-critic architecture with novel Goal-Conditioned Value Formulation (GCVF), where a frozen critic anchors semantic consistency and a trainable estimator drives adaptation. Experiments on the LIBERO benchmark demonstrate that CRL-VLA effectively harmonizes these conflicting objectives, outperforming baselines in both anti-forgetting and forward adaptation.
Balancing Signal and Variance: Adaptive Offline RL Post-Training for VLA Flow Models
Sep 04, 2025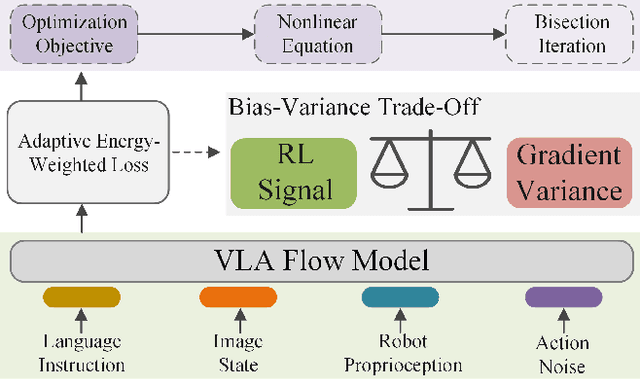
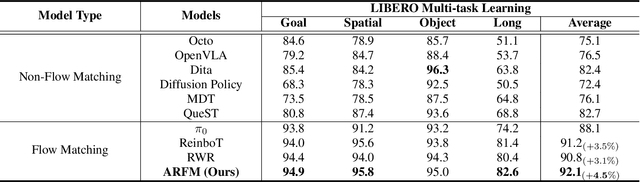

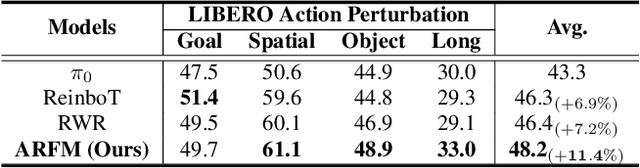
Vision-Language-Action (VLA) models based on flow matching have shown excellent performance in general-purpose robotic manipulation tasks. However, the action accuracy of these models on complex downstream tasks is unsatisfactory. One important reason is that these models rely solely on the post-training paradigm of imitation learning, which makes it difficult to have a deeper understanding of the distribution properties of data quality, which is exactly what Reinforcement Learning (RL) excels at. In this paper, we theoretically propose an offline RL post-training objective for VLA flow models and induce an efficient and feasible offline RL fine-tuning algorithm -- Adaptive Reinforced Flow Matching (ARFM). By introducing an adaptively adjusted scaling factor in the VLA flow model loss, we construct a principled bias-variance trade-off objective function to optimally control the impact of RL signal on flow loss. ARFM adaptively balances RL advantage preservation and flow loss gradient variance control, resulting in a more stable and efficient fine-tuning process. Extensive simulation and real-world experimental results show that ARFM exhibits excellent generalization, robustness, few-shot learning, and continuous learning performance.
Multi-Task Multi-Agent Reinforcement Learning via Skill Graphs
Jul 09, 2025Multi-task multi-agent reinforcement learning (MT-MARL) has recently gained attention for its potential to enhance MARL's adaptability across multiple tasks. However, it is challenging for existing multi-task learning methods to handle complex problems, as they are unable to handle unrelated tasks and possess limited knowledge transfer capabilities. In this paper, we propose a hierarchical approach that efficiently addresses these challenges. The high-level module utilizes a skill graph, while the low-level module employs a standard MARL algorithm. Our approach offers two contributions. First, we consider the MT-MARL problem in the context of unrelated tasks, expanding the scope of MTRL. Second, the skill graph is used as the upper layer of the standard hierarchical approach, with training independent of the lower layer, effectively handling unrelated tasks and enhancing knowledge transfer capabilities. Extensive experiments are conducted to validate these advantages and demonstrate that the proposed method outperforms the latest hierarchical MAPPO algorithms. Videos and code are available at https://github.com/WindyLab/MT-MARL-SG
ReinboT: Amplifying Robot Visual-Language Manipulation with Reinforcement Learning
May 12, 2025
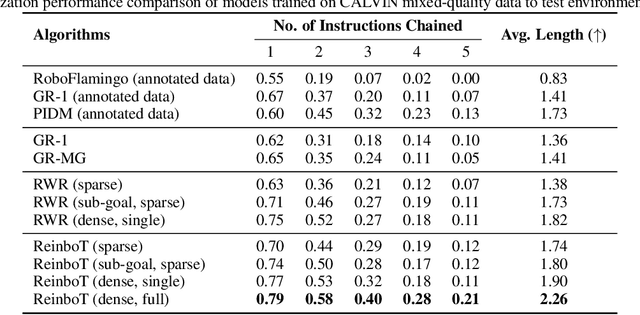


Vision-Language-Action (VLA) models have shown great potential in general robotic decision-making tasks via imitation learning. However, the variable quality of training data often constrains the performance of these models. On the other hand, offline Reinforcement Learning (RL) excels at learning robust policy models from mixed-quality data. In this paper, we introduce Reinforced robot GPT (ReinboT), a novel end-to-end VLA model that integrates the RL principle of maximizing cumulative reward. ReinboT achieves a deeper understanding of the data quality distribution by predicting dense returns that capture the nuances of manipulation tasks. The dense return prediction capability enables the robot to generate more robust decision-making actions, oriented towards maximizing future benefits. Extensive experiments show that ReinboT achieves state-of-the-art performance on the CALVIN mixed-quality dataset and exhibits superior few-shot learning and out-of-distribution generalization capabilities in real-world tasks.
TDMPBC: Self-Imitative Reinforcement Learning for Humanoid Robot Control
Feb 24, 2025Complex high-dimensional spaces with high Degree-of-Freedom and complicated action spaces, such as humanoid robots equipped with dexterous hands, pose significant challenges for reinforcement learning (RL) algorithms, which need to wisely balance exploration and exploitation under limited sample budgets. In general, feasible regions for accomplishing tasks within complex high-dimensional spaces are exceedingly narrow. For instance, in the context of humanoid robot motion control, the vast majority of space corresponds to falling, while only a minuscule fraction corresponds to standing upright, which is conducive to the completion of downstream tasks. Once the robot explores into a potentially task-relevant region, it should place greater emphasis on the data within that region. Building on this insight, we propose the $\textbf{S}$elf-$\textbf{I}$mitative $\textbf{R}$einforcement $\textbf{L}$earning ($\textbf{SIRL}$) framework, where the RL algorithm also imitates potentially task-relevant trajectories. Specifically, trajectory return is utilized to determine its relevance to the task and an additional behavior cloning is adopted whose weight is dynamically adjusted based on the trajectory return. As a result, our proposed algorithm achieves 120% performance improvement on the challenging HumanoidBench with 5% extra computation overhead. With further visualization, we find the significant performance gain does lead to meaningful behavior improvement that several tasks are solved successfully.
GEVRM: Goal-Expressive Video Generation Model For Robust Visual Manipulation
Feb 13, 2025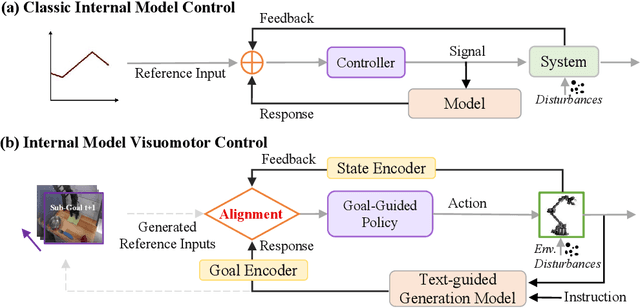
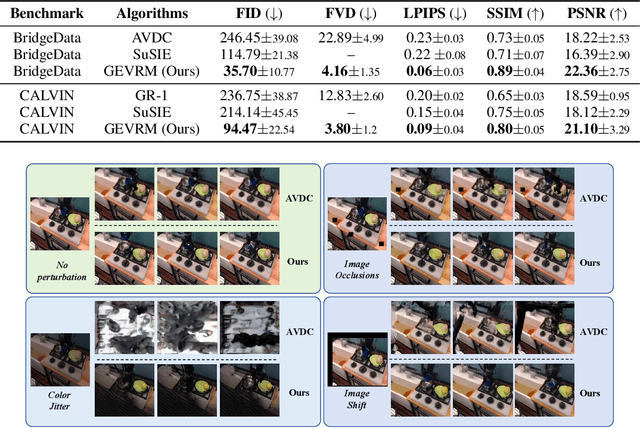
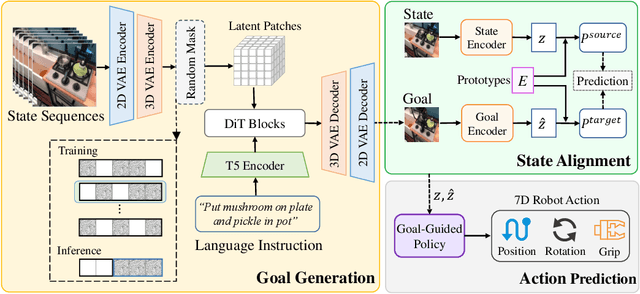

With the rapid development of embodied artificial intelligence, significant progress has been made in vision-language-action (VLA) models for general robot decision-making. However, the majority of existing VLAs fail to account for the inevitable external perturbations encountered during deployment. These perturbations introduce unforeseen state information to the VLA, resulting in inaccurate actions and consequently, a significant decline in generalization performance. The classic internal model control (IMC) principle demonstrates that a closed-loop system with an internal model that includes external input signals can accurately track the reference input and effectively offset the disturbance. We propose a novel closed-loop VLA method GEVRM that integrates the IMC principle to enhance the robustness of robot visual manipulation. The text-guided video generation model in GEVRM can generate highly expressive future visual planning goals. Simultaneously, we evaluate perturbations by simulating responses, which are called internal embeddings and optimized through prototype contrastive learning. This allows the model to implicitly infer and distinguish perturbations from the external environment. The proposed GEVRM achieves state-of-the-art performance on both standard and perturbed CALVIN benchmarks and shows significant improvements in realistic robot tasks.
QUART-Online: Latency-Free Large Multimodal Language Model for Quadruped Robot Learning
Dec 23, 2024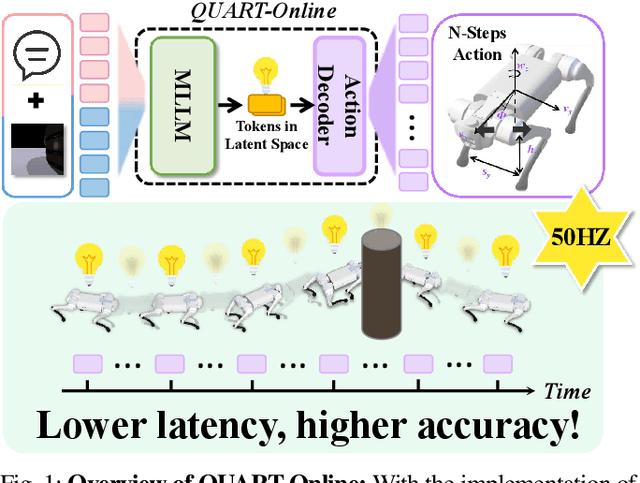
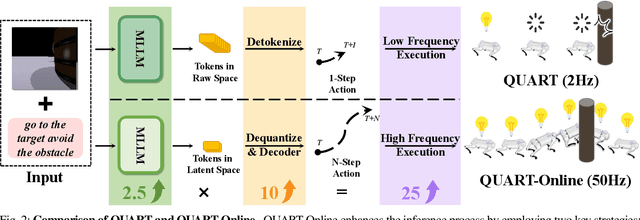
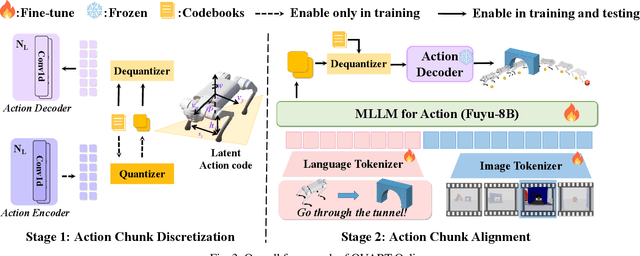
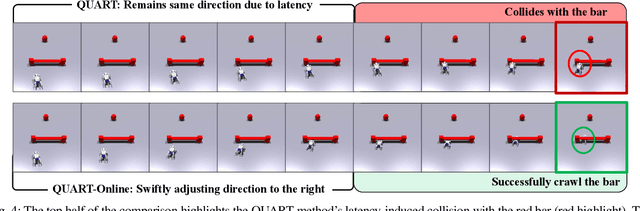
This paper addresses the inherent inference latency challenges associated with deploying multimodal large language models (MLLM) in quadruped vision-language-action (QUAR-VLA) tasks. Our investigation reveals that conventional parameter reduction techniques ultimately impair the performance of the language foundation model during the action instruction tuning phase, making them unsuitable for this purpose. We introduce a novel latency-free quadruped MLLM model, dubbed QUART-Online, designed to enhance inference efficiency without degrading the performance of the language foundation model. By incorporating Action Chunk Discretization (ACD), we compress the original action representation space, mapping continuous action values onto a smaller set of discrete representative vectors while preserving critical information. Subsequently, we fine-tune the MLLM to integrate vision, language, and compressed actions into a unified semantic space. Experimental results demonstrate that QUART-Online operates in tandem with the existing MLLM system, achieving real-time inference in sync with the underlying controller frequency, significantly boosting the success rate across various tasks by 65%. Our project page is https://quart-online.github.io.