 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMaDA-VLA: Large Diffusion Vision-Language-Action Model with Unified Multi-Modal Instruction and Generation
Mar 27, 2026Vision-Language-Action (VLA) models aim to control robots for manipulation from visual observations and natural-language instructions. However, existing hierarchical and autoregressive paradigms often introduce architectural overhead, suffer from temporal inconsistency and long-horizon error accumulation, and lack a mechanism to capture environment dynamics without extra modules. To this end, we present MMaDA-VLA, a fully native pre-trained large diffusion VLA model that unifies multi-modal understanding and generation in a single framework. Our key idea is a native discrete diffusion formulation that embeds language, images, and continuous robot controls into one discrete token space and trains a single backbone with masked token denoising to jointly generate a future goal observation and an action chunk in parallel. Iterative denoising enables global, order-free refinement, improving long-horizon consistency while grounding actions in predicted future visual outcomes without auxiliary world models. Experiments across simulation benchmarks and real-world tasks show state-of-the-art performance, achieving 98.0% average success on LIBERO and 4.78 average length on CALVIN.
NFPO: Stabilized Policy Optimization of Normalizing Flow for Robotic Policy Learning
Mar 12, 2026Deep Reinforcement Learning (DRL) has experienced significant advancements in recent years and has been widely used in many fields. In DRL-based robotic policy learning, however, current de facto policy parameterization is still multivariate Gaussian (with diagonal covariance matrix), which lacks the ability to model multi-modal distribution. In this work, we explore the adoption of a modern network architecture, i.e. Normalizing Flow (NF) as the policy parameterization for its ability of multi-modal modeling, closed form of log probability and low computation and memory overhead. However, naively training NF in online Reinforcement Learning (RL) usually leads to training instability. We provide a detailed analysis for this phenomenon and successfully address it via simple but effective technique. With extensive experiments in multiple simulation environments, we show our method, NFPO could obtain robust and strong performance in widely used robotic learning tasks and successfully transfer into real-world robots.
HiF-VLA: Hindsight, Insight and Foresight through Motion Representation for Vision-Language-Action Models
Dec 10, 2025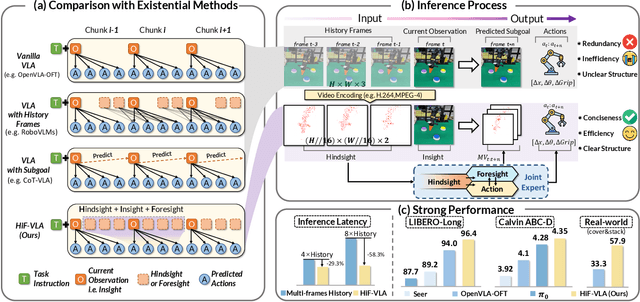
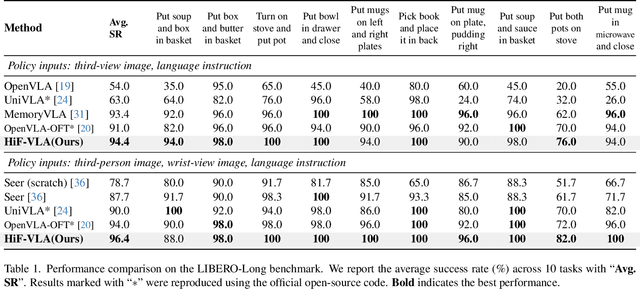
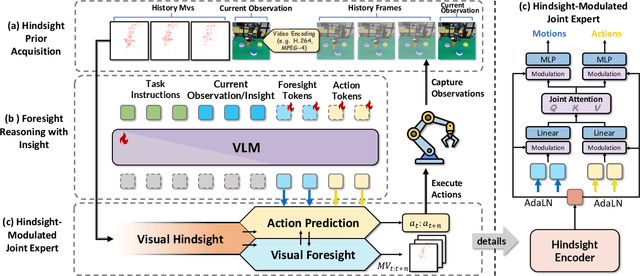
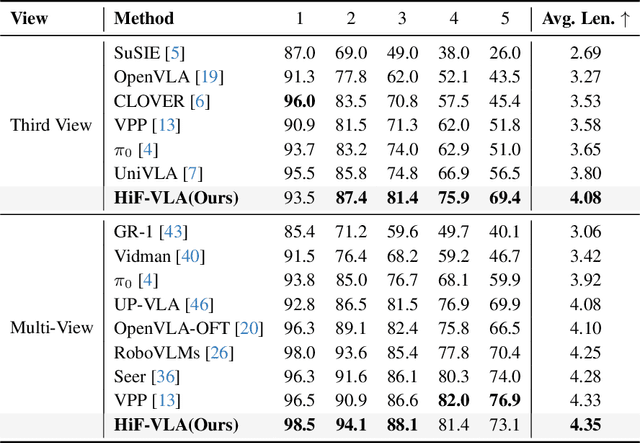
Vision-Language-Action (VLA) models have recently enabled robotic manipulation by grounding visual and linguistic cues into actions. However, most VLAs assume the Markov property, relying only on the current observation and thus suffering from temporal myopia that degrades long-horizon coherence. In this work, we view motion as a more compact and informative representation of temporal context and world dynamics, capturing inter-state changes while filtering static pixel-level noise. Building on this idea, we propose HiF-VLA (Hindsight, Insight, and Foresight for VLAs), a unified framework that leverages motion for bidirectional temporal reasoning. HiF-VLA encodes past dynamics through hindsight priors, anticipates future motion via foresight reasoning, and integrates both through a hindsight-modulated joint expert to enable a ''think-while-acting'' paradigm for long-horizon manipulation. As a result, HiF-VLA surpasses strong baselines on LIBERO-Long and CALVIN ABC-D benchmarks, while incurring negligible additional inference latency. Furthermore, HiF-VLA achieves substantial improvements in real-world long-horizon manipulation tasks, demonstrating its broad effectiveness in practical robotic settings.
Efficient Online RL Fine Tuning with Offline Pre-trained Policy Only
May 22, 2025Improving the performance of pre-trained policies through online reinforcement learning (RL) is a critical yet challenging topic. Existing online RL fine-tuning methods require continued training with offline pretrained Q-functions for stability and performance. However, these offline pretrained Q-functions commonly underestimate state-action pairs beyond the offline dataset due to the conservatism in most offline RL methods, which hinders further exploration when transitioning from the offline to the online setting. Additionally, this requirement limits their applicability in scenarios where only pre-trained policies are available but pre-trained Q-functions are absent, such as in imitation learning (IL) pre-training. To address these challenges, we propose a method for efficient online RL fine-tuning using solely the offline pre-trained policy, eliminating reliance on pre-trained Q-functions. We introduce PORL (Policy-Only Reinforcement Learning Fine-Tuning), which rapidly initializes the Q-function from scratch during the online phase to avoid detrimental pessimism. Our method not only achieves competitive performance with advanced offline-to-online RL algorithms and online RL approaches that leverage data or policies prior, but also pioneers a new path for directly fine-tuning behavior cloning (BC) policies.
VARD: Efficient and Dense Fine-Tuning for Diffusion Models with Value-based RL
May 21, 2025



Diffusion models have emerged as powerful generative tools across various domains, yet tailoring pre-trained models to exhibit specific desirable properties remains challenging. While reinforcement learning (RL) offers a promising solution,current methods struggle to simultaneously achieve stable, efficient fine-tuning and support non-differentiable rewards. Furthermore, their reliance on sparse rewards provides inadequate supervision during intermediate steps, often resulting in suboptimal generation quality. To address these limitations, dense and differentiable signals are required throughout the diffusion process. Hence, we propose VAlue-based Reinforced Diffusion (VARD): a novel approach that first learns a value function predicting expection of rewards from intermediate states, and subsequently uses this value function with KL regularization to provide dense supervision throughout the generation process. Our method maintains proximity to the pretrained model while enabling effective and stable training via backpropagation. Experimental results demonstrate that our approach facilitates better trajectory guidance, improves training efficiency and extends the applicability of RL to diffusion models optimized for complex, non-differentiable reward functions.
ReinboT: Amplifying Robot Visual-Language Manipulation with Reinforcement Learning
May 12, 2025
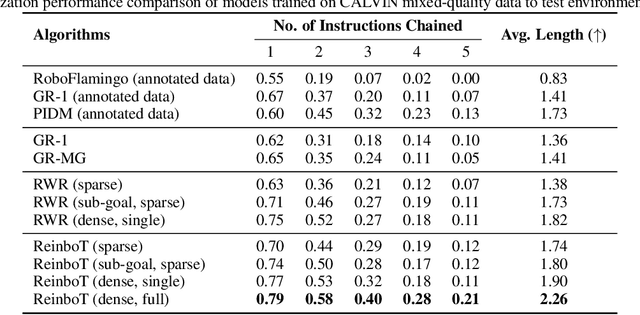


Vision-Language-Action (VLA) models have shown great potential in general robotic decision-making tasks via imitation learning. However, the variable quality of training data often constrains the performance of these models. On the other hand, offline Reinforcement Learning (RL) excels at learning robust policy models from mixed-quality data. In this paper, we introduce Reinforced robot GPT (ReinboT), a novel end-to-end VLA model that integrates the RL principle of maximizing cumulative reward. ReinboT achieves a deeper understanding of the data quality distribution by predicting dense returns that capture the nuances of manipulation tasks. The dense return prediction capability enables the robot to generate more robust decision-making actions, oriented towards maximizing future benefits. Extensive experiments show that ReinboT achieves state-of-the-art performance on the CALVIN mixed-quality dataset and exhibits superior few-shot learning and out-of-distribution generalization capabilities in real-world tasks.
TDMPBC: Self-Imitative Reinforcement Learning for Humanoid Robot Control
Feb 24, 2025Complex high-dimensional spaces with high Degree-of-Freedom and complicated action spaces, such as humanoid robots equipped with dexterous hands, pose significant challenges for reinforcement learning (RL) algorithms, which need to wisely balance exploration and exploitation under limited sample budgets. In general, feasible regions for accomplishing tasks within complex high-dimensional spaces are exceedingly narrow. For instance, in the context of humanoid robot motion control, the vast majority of space corresponds to falling, while only a minuscule fraction corresponds to standing upright, which is conducive to the completion of downstream tasks. Once the robot explores into a potentially task-relevant region, it should place greater emphasis on the data within that region. Building on this insight, we propose the $\textbf{S}$elf-$\textbf{I}$mitative $\textbf{R}$einforcement $\textbf{L}$earning ($\textbf{SIRL}$) framework, where the RL algorithm also imitates potentially task-relevant trajectories. Specifically, trajectory return is utilized to determine its relevance to the task and an additional behavior cloning is adopted whose weight is dynamically adjusted based on the trajectory return. As a result, our proposed algorithm achieves 120% performance improvement on the challenging HumanoidBench with 5% extra computation overhead. With further visualization, we find the significant performance gain does lead to meaningful behavior improvement that several tasks are solved successfully.
Q-WSL:Leveraging Dynamic Programming for Weighted Supervised Learning in Goal-conditioned RL
Oct 10, 2024

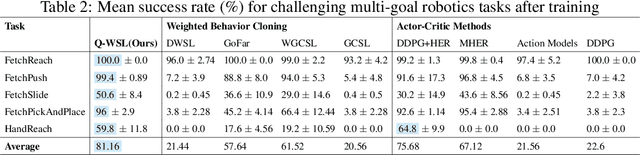
A novel class of advanced algorithms, termed Goal-Conditioned Weighted Supervised Learning (GCWSL), has recently emerged to tackle the challenges posed by sparse rewards in goal-conditioned reinforcement learning (RL). GCWSL consistently delivers strong performance across a diverse set of goal-reaching tasks due to its simplicity, effectiveness, and stability. However, GCWSL methods lack a crucial capability known as trajectory stitching, which is essential for learning optimal policies when faced with unseen skills during testing. This limitation becomes particularly pronounced when the replay buffer is predominantly filled with sub-optimal trajectories. In contrast, traditional TD-based RL methods, such as Q-learning, which utilize Dynamic Programming, do not face this issue but often experience instability due to the inherent difficulties in value function approximation. In this paper, we propose Q-learning Weighted Supervised Learning (Q-WSL), a novel framework designed to overcome the limitations of GCWSL by incorporating the strengths of Dynamic Programming found in Q-learning. Q-WSL leverages Dynamic Programming results to output the optimal action of (state, goal) pairs across different trajectories within the replay buffer. This approach synergizes the strengths of both Q-learning and GCWSL, effectively mitigating their respective weaknesses and enhancing overall performance. Empirical evaluations on challenging goal-reaching tasks demonstrate that Q-WSL surpasses other goal-conditioned approaches in terms of both performance and sample efficiency. Additionally, Q-WSL exhibits notable robustness in environments characterized by binary reward structures and environmental stochasticity.
ADR-BC: Adversarial Density Weighted Regression Behavior Cloning
May 28, 2024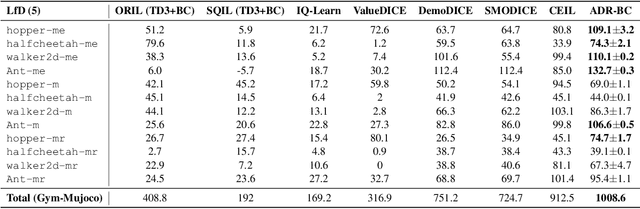
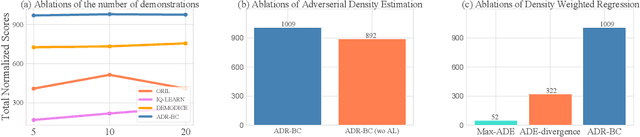
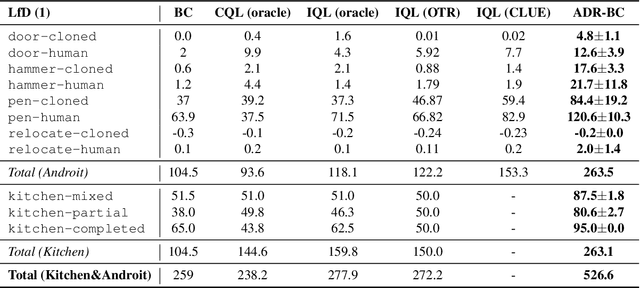
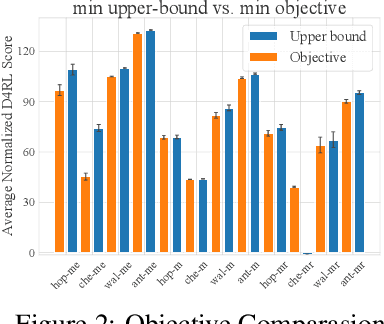
Typically, traditional Imitation Learning (IL) methods first shape a reward or Q function and then use this shaped function within a reinforcement learning (RL) framework to optimize the empirical policy. However, if the shaped reward/Q function does not adequately represent the ground truth reward/Q function, updating the policy within a multi-step RL framework may result in cumulative bias, further impacting policy learning. Although utilizing behavior cloning (BC) to learn a policy by directly mimicking a few demonstrations in a single-step updating manner can avoid cumulative bias, BC tends to greedily imitate demonstrated actions, limiting its capacity to generalize to unseen state action pairs. To address these challenges, we propose ADR-BC, which aims to enhance behavior cloning through augmented density-based action support, optimizing the policy with this augmented support. Specifically, the objective of ADR-BC shares the similar physical meanings that matching expert distribution while diverging the sub-optimal distribution. Therefore, ADR-BC can achieve more robust expert distribution matching. Meanwhile, as a one-step behavior cloning framework, ADR-BC avoids the cumulative bias associated with multi-step RL frameworks. To validate the performance of ADR-BC, we conduct extensive experiments. Specifically, ADR-BC showcases a 10.5% improvement over the previous state-of-the-art (SOTA) generalized IL baseline, CEIL, across all tasks in the Gym-Mujoco domain. Additionally, it achieves an 89.5% improvement over Implicit Q Learning (IQL) using real rewards across all tasks in the Adroit and Kitchen domains. On the other hand, we conduct extensive ablations to further demonstrate the effectiveness of ADR-BC.
DIDI: Diffusion-Guided Diversity for Offline Behavioral Generation
May 23, 2024In this paper, we propose a novel approach called DIffusion-guided DIversity (DIDI) for offline behavioral generation. The goal of DIDI is to learn a diverse set of skills from a mixture of label-free offline data. We achieve this by leveraging diffusion probabilistic models as priors to guide the learning process and regularize the policy. By optimizing a joint objective that incorporates diversity and diffusion-guided regularization, we encourage the emergence of diverse behaviors while maintaining the similarity to the offline data. Experimental results in four decision-making domains (Push, Kitchen, Humanoid, and D4RL tasks) show that DIDI is effective in discovering diverse and discriminative skills. We also introduce skill stitching and skill interpolation, which highlight the generalist nature of the learned skill space. Further, by incorporating an extrinsic reward function, DIDI enables reward-guided behavior generation, facilitating the learning of diverse and optimal behaviors from sub-optimal data.