 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNever Too Rigid to Reach: Adaptive Virtual Model Control with LLM- and Lyapunov-Based Reinforcement Learning
Oct 27, 2025Robotic arms are increasingly deployed in uncertain environments, yet conventional control pipelines often become rigid and brittle when exposed to perturbations or incomplete information. Virtual Model Control (VMC) enables compliant behaviors by embedding virtual forces and mapping them into joint torques, but its reliance on fixed parameters and limited coordination among virtual components constrains adaptability and may undermine stability as task objectives evolve. To address these limitations, we propose Adaptive VMC with Large Language Model (LLM)- and Lyapunov-Based Reinforcement Learning (RL), which preserves the physical interpretability of VMC while supporting stability-guaranteed online adaptation. The LLM provides structured priors and high-level reasoning that enhance coordination among virtual components, improve sample efficiency, and facilitate flexible adjustment to varying task requirements. Complementarily, Lyapunov-based RL enforces theoretical stability constraints, ensuring safe and reliable adaptation under uncertainty. Extensive simulations on a 7-DoF Panda arm demonstrate that our approach effectively balances competing objectives in dynamic tasks, achieving superior performance while highlighting the synergistic benefits of LLM guidance and Lyapunov-constrained adaptation.
ViP$^2$-CLIP: Visual-Perception Prompting with Unified Alignment for Zero-Shot Anomaly Detection
May 23, 2025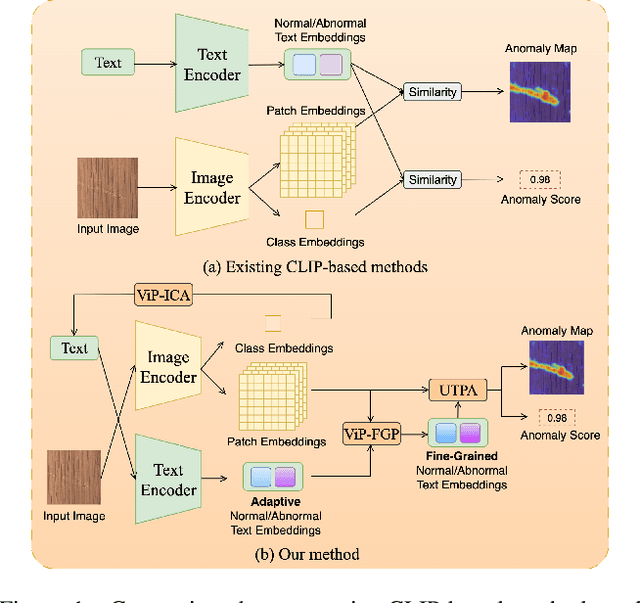
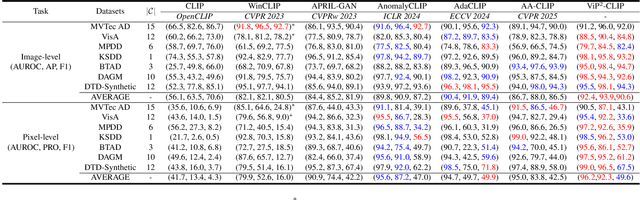
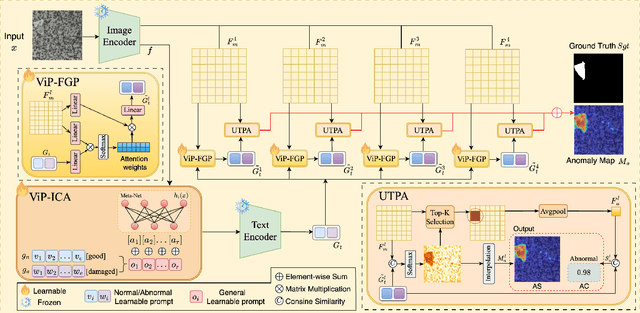
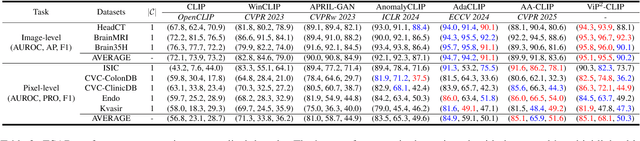
Zero-shot anomaly detection (ZSAD) aims to detect anomalies without any target domain training samples, relying solely on external auxiliary data. Existing CLIP-based methods attempt to activate the model's ZSAD potential via handcrafted or static learnable prompts. The former incur high engineering costs and limited semantic coverage, whereas the latter apply identical descriptions across diverse anomaly types, thus fail to adapt to complex variations. Furthermore, since CLIP is originally pretrained on large-scale classification tasks, its anomaly segmentation quality is highly sensitive to the exact wording of class names, severely constraining prompting strategies that depend on class labels. To address these challenges, we introduce ViP$^{2}$-CLIP. The key insight of ViP$^{2}$-CLIP is a Visual-Perception Prompting (ViP-Prompt) mechanism, which fuses global and multi-scale local visual context to adaptively generate fine-grained textual prompts, eliminating manual templates and class-name priors. This design enables our model to focus on precise abnormal regions, making it particularly valuable when category labels are ambiguous or privacy-constrained. Extensive experiments on 15 industrial and medical benchmarks demonstrate that ViP$^{2}$-CLIP achieves state-of-the-art performance and robust cross-domain generalization.
Never too Cocky to Cooperate: An FIM and RL-based USV-AUV Collaborative System for Underwater Tasks in Extreme Sea Conditions
Apr 21, 2025



This paper develops a novel unmanned surface vehicle (USV)-autonomous underwater vehicle (AUV) collaborative system designed to enhance underwater task performance in extreme sea conditions. The system integrates a dual strategy: (1) high-precision multi-AUV localization enabled by Fisher information matrix-optimized USV path planning, and (2) reinforcement learning-based cooperative planning and control method for multi-AUV task execution. Extensive experimental evaluations in the underwater data collection task demonstrate the system's operational feasibility, with quantitative results showing significant performance improvements over baseline methods. The proposed system exhibits robust coordination capabilities between USV and AUVs while maintaining stability in extreme sea conditions. To facilitate reproducibility and community advancement, we provide an open-source simulation toolkit available at: https://github.com/360ZMEM/USV-AUV-colab .
Is FISHER All You Need in The Multi-AUV Underwater Target Tracking Task?
Dec 05, 2024



It is significant to employ multiple autonomous underwater vehicles (AUVs) to execute the underwater target tracking task collaboratively. However, it's pretty challenging to meet various prerequisites utilizing traditional control methods. Therefore, we propose an effective two-stage learning from demonstrations training framework, FISHER, to highlight the adaptability of reinforcement learning (RL) methods in the multi-AUV underwater target tracking task, while addressing its limitations such as extensive requirements for environmental interactions and the challenges in designing reward functions. The first stage utilizes imitation learning (IL) to realize policy improvement and generate offline datasets. To be specific, we introduce multi-agent discriminator-actor-critic based on improvements of the generative adversarial IL algorithm and multi-agent IL optimization objective derived from the Nash equilibrium condition. Then in the second stage, we develop multi-agent independent generalized decision transformer, which analyzes the latent representation to match the future states of high-quality samples rather than reward function, attaining further enhanced policies capable of handling various scenarios. Besides, we propose a simulation to simulation demonstration generation procedure to facilitate the generation of expert demonstrations in underwater environments, which capitalizes on traditional control methods and can easily accomplish the domain transfer to obtain demonstrations. Extensive simulation experiments from multiple scenarios showcase that FISHER possesses strong stability, multi-task performance and capability of generalization.
CausalVE: Face Video Privacy Encryption via Causal Video Prediction
Sep 28, 2024



Advanced facial recognition technologies and recommender systems with inadequate privacy technologies and policies for facial interactions increase concerns about bioprivacy violations. With the proliferation of video and live-streaming websites, public-face video distribution and interactions pose greater privacy risks. Existing techniques typically address the risk of sensitive biometric information leakage through various privacy enhancement methods but pose a higher security risk by corrupting the information to be conveyed by the interaction data, or by leaving certain biometric features intact that allow an attacker to infer sensitive biometric information from them. To address these shortcomings, in this paper, we propose a neural network framework, CausalVE. We obtain cover images by adopting a diffusion model to achieve face swapping with face guidance and use the speech sequence features and spatiotemporal sequence features of the secret video for dynamic video inference and prediction to obtain a cover video with the same number of frames as the secret video. In addition, we hide the secret video by using reversible neural networks for video hiding so that the video can also disseminate secret data. Numerous experiments prove that our CausalVE has good security in public video dissemination and outperforms state-of-the-art methods from a qualitative, quantitative, and visual point of view.
LHQ-SVC: Lightweight and High Quality Singing Voice Conversion Modeling
Sep 13, 2024


Singing Voice Conversion (SVC) has emerged as a significant subfield of Voice Conversion (VC), enabling the transformation of one singer's voice into another while preserving musical elements such as melody, rhythm, and timbre. Traditional SVC methods have limitations in terms of audio quality, data requirements, and computational complexity. In this paper, we propose LHQ-SVC, a lightweight, CPU-compatible model based on the SVC framework and diffusion model, designed to reduce model size and computational demand without sacrificing performance. We incorporate features to improve inference quality, and optimize for CPU execution by using performance tuning tools and parallel computing frameworks. Our experiments demonstrate that LHQ-SVC maintains competitive performance, with significant improvements in processing speed and efficiency across different devices. The results suggest that LHQ-SVC can meet
USV-AUV Collaboration Framework for Underwater Tasks under Extreme Sea Conditions
Sep 04, 2024



Autonomous underwater vehicles (AUVs) are valuable for ocean exploration due to their flexibility and ability to carry communication and detection units. Nevertheless, AUVs alone often face challenges in harsh and extreme sea conditions. This study introduces a unmanned surface vehicle (USV)-AUV collaboration framework, which includes high-precision multi-AUV positioning using USV path planning via Fisher information matrix optimization and reinforcement learning for multi-AUV cooperative tasks. Applied to a multi-AUV underwater data collection task scenario, extensive simulations validate the framework's feasibility and superior performance, highlighting exceptional coordination and robustness under extreme sea conditions. The simulation code will be made available as open-source to foster future research in this area.
Large Language Models as Efficient Reward Function Searchers for Custom-Environment Multi-Objective Reinforcement Learning
Sep 04, 2024



Leveraging large language models (LLMs) for designing reward functions demonstrates significant potential. However, achieving effective design and improvement of reward functions in reinforcement learning (RL) tasks with complex custom environments and multiple requirements presents considerable challenges. In this paper, we enable LLMs to be effective white-box searchers, highlighting their advanced semantic understanding capabilities. Specifically, we generate reward components for each explicit user requirement and employ the reward critic to identify the correct code form. Then, LLMs assign weights to the reward components to balance their values and iteratively search and optimize these weights based on the context provided by the training log analyzer, while adaptively determining the search step size. We applied the framework to an underwater information collection RL task without direct human feedback or reward examples (zero-shot). The reward critic successfully correct the reward code with only one feedback for each requirement, effectively preventing irreparable errors that can occur when reward function feedback is provided in aggregate. The effective initialization of weights enables the acquisition of different reward functions within the Pareto solution set without weight search. Even in the case where a weight is 100 times off, fewer than four iterations are needed to obtain solutions that meet user requirements. The framework also works well with most prompts utilizing GPT-3.5 Turbo, since it does not require advanced numerical understanding or calculation.
ADR-BC: Adversarial Density Weighted Regression Behavior Cloning
May 28, 2024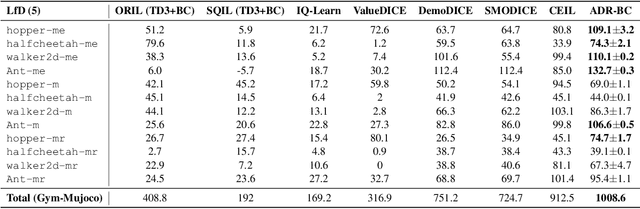
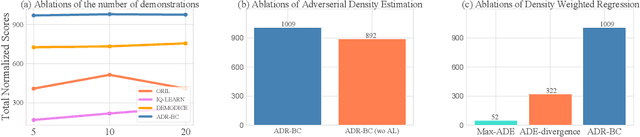
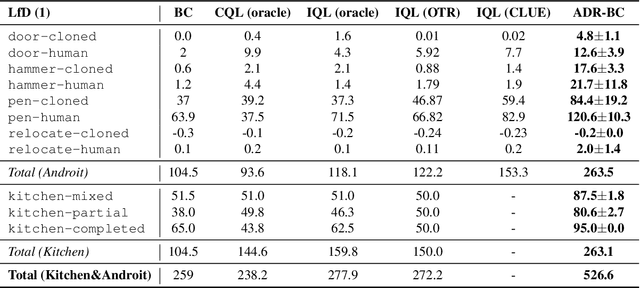
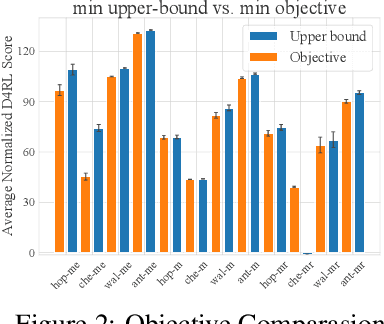
Typically, traditional Imitation Learning (IL) methods first shape a reward or Q function and then use this shaped function within a reinforcement learning (RL) framework to optimize the empirical policy. However, if the shaped reward/Q function does not adequately represent the ground truth reward/Q function, updating the policy within a multi-step RL framework may result in cumulative bias, further impacting policy learning. Although utilizing behavior cloning (BC) to learn a policy by directly mimicking a few demonstrations in a single-step updating manner can avoid cumulative bias, BC tends to greedily imitate demonstrated actions, limiting its capacity to generalize to unseen state action pairs. To address these challenges, we propose ADR-BC, which aims to enhance behavior cloning through augmented density-based action support, optimizing the policy with this augmented support. Specifically, the objective of ADR-BC shares the similar physical meanings that matching expert distribution while diverging the sub-optimal distribution. Therefore, ADR-BC can achieve more robust expert distribution matching. Meanwhile, as a one-step behavior cloning framework, ADR-BC avoids the cumulative bias associated with multi-step RL frameworks. To validate the performance of ADR-BC, we conduct extensive experiments. Specifically, ADR-BC showcases a 10.5% improvement over the previous state-of-the-art (SOTA) generalized IL baseline, CEIL, across all tasks in the Gym-Mujoco domain. Additionally, it achieves an 89.5% improvement over Implicit Q Learning (IQL) using real rewards across all tasks in the Adroit and Kitchen domains. On the other hand, we conduct extensive ablations to further demonstrate the effectiveness of ADR-BC.
Context-Former: Stitching via Latent Conditioned Sequence Modeling
Feb 03, 2024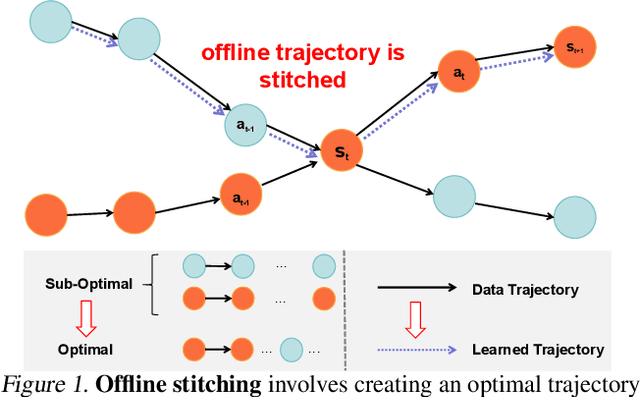
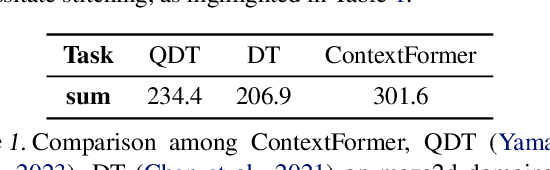
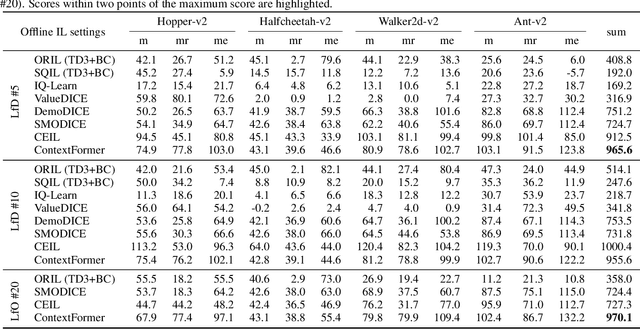
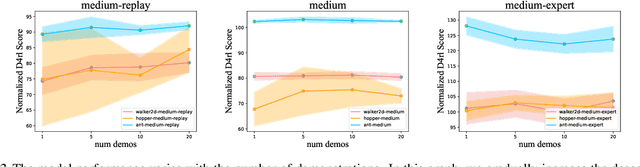
Offline reinforcement learning (RL) algorithms can improve the decision making via stitching sub-optimal trajectories to obtain more optimal ones. This capability is a crucial factor in enabling RL to learn policies that are superior to the behavioral policy. On the other hand, Decision Transformer (DT) abstracts the decision-making as sequence modeling, showcasing competitive performance on offline RL benchmarks, however, recent studies demonstrate that DT lacks of stitching capability, thus exploit stitching capability for DT is vital to further improve its performance. In order to endow stitching capability to DT, we abstract trajectory stitching as expert matching and introduce our approach, ContextFormer, which integrates contextual information-based imitation learning (IL) and sequence modeling to stitch sub-optimal trajectory fragments by emulating the representations of a limited number of expert trajectories. To validate our claim, we conduct experiments from two perspectives: 1) We conduct extensive experiments on D4RL benchmarks under the settings of IL, and experimental results demonstrate ContextFormer can achieve competitive performance in multi-IL settings. 2) More importantly, we conduct a comparison of ContextFormer with diverse competitive DT variants using identical training datasets. The experimental results unveiled ContextFormer's superiority, as it outperformed all other variants, showcasing its remarkable performance.