 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-Former: Stitching via Latent Conditioned Sequence Modeling
Paper and Code
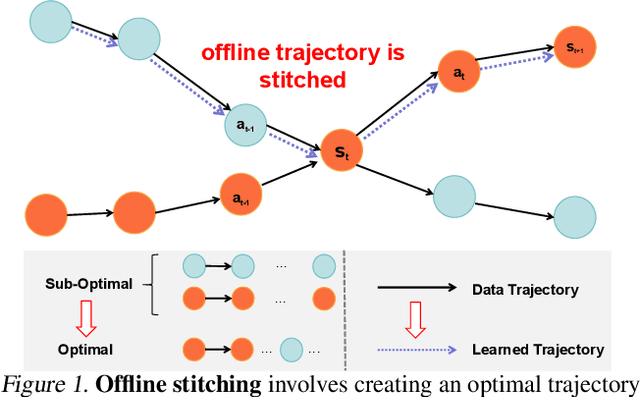
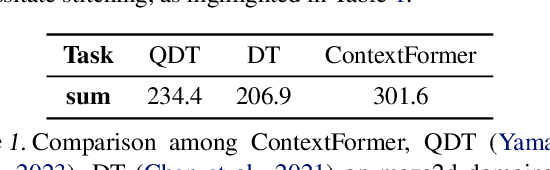
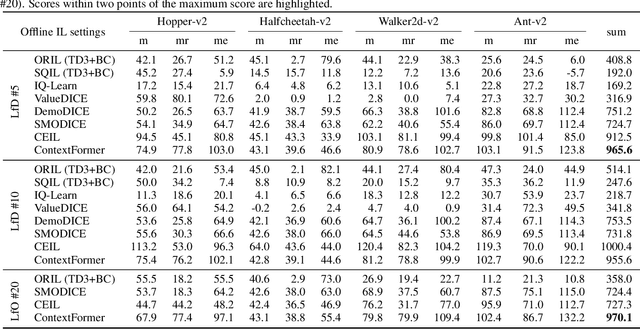
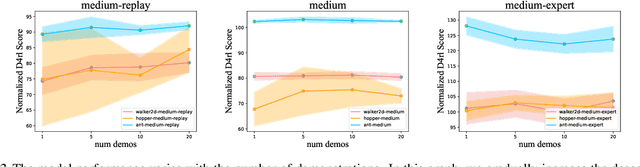
Offline reinforcement learning (RL) algorithms can improve the decision making via stitching sub-optimal trajectories to obtain more optimal ones. This capability is a crucial factor in enabling RL to learn policies that are superior to the behavioral policy. On the other hand, Decision Transformer (DT) abstracts the decision-making as sequence modeling, showcasing competitive performance on offline RL benchmarks, however, recent studies demonstrate that DT lacks of stitching capability, thus exploit stitching capability for DT is vital to further improve its performance. In order to endow stitching capability to DT, we abstract trajectory stitching as expert matching and introduce our approach, ContextFormer, which integrates contextual information-based imitation learning (IL) and sequence modeling to stitch sub-optimal trajectory fragments by emulating the representations of a limited number of expert trajectories. To validate our claim, we conduct experiments from two perspectives: 1) We conduct extensive experiments on D4RL benchmarks under the settings of IL, and experimental results demonstrate ContextFormer can achieve competitive performance in multi-IL settings. 2) More importantly, we conduct a comparison of ContextFormer with diverse competitive DT variants using identical training datasets. The experimental results unveiled ContextFormer's superiority, as it outperformed all other variants, showcasing its remarkable performance.