 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoK: Security and Privacy of Foundation-Model-Powered Robots
Jun 15, 2026Foundation models are reshaping robotics by enabling robots to interpret open-ended instructions, reason over multimodal contexts, and operate in complex, open-world environments. However, their integration also introduces security and privacy (S&P) risks that extend beyond the FMs themselves to embodied execution pipelines, supporting ecosystems, and broader governance impacts. Existing literature reviews provide valuable insights but often focus on specific FM types, risk categories, mitigation strategies, or trust boundaries. Consequently, the field lacks a unified structure for analyzing where risks originate, how they propagate across robotic systems, and where mitigations should intervene. To address this gap, we propose a progressive F-E-S-G structural boundary framework for analyzing the S&P of FM-powered robots. The framework comprises four layers: the Foundation model layer (F), Embodied system layer (E), Supporting ecosystem layer (S), and Governance impact layer (G). Building on this structure, we develop a multi-level taxonomy that organizes prior studies along three levels: F-E-S-G trust boundary, security-privacy concerns, and risk-mitigation perspectives. We further annotate each study using fine-grained coding attributes, including target, lifecycle stage, mechanism, system access, and effect. Guided by this framework and taxonomy, we systematize 96 papers. Our analysis uncovers multiple threat patterns, defense mismatches, and evaluation gaps that are difficult to identify from a single-boundary perspective. Based on these findings, we identify open challenges and future directions to provide a research agenda for developing secure, privacy-preserving, and responsibly governed FM-powered robotic systems.
Distributionally Robust Physical-Layer Security for Satellite Communication via Aerial Reconfigurable Intelligent Surface
May 29, 2026Satellite communications are envisioned as a key enabler for ubiquitous coverage in future 6G networks, yet the broadcast nature renders them vulnerable to eavesdropping, especially given the long-distance transmissions and associated high uncertainties. In this paper, we propose the physical layer security enhancement for multi-beam satellite communications with the assistance of an aerial reconfigurable intelligent surface (ARIS). Considering the high dynamics and uncertainties of channels, we characterize the channel distribution with moment-based ambiguity sets. Accordingly, a distributionally robust secrecy rate optimization is formulated through joint design of transmit and reflection beamforming. We then introduce a conditional value-at-risk-based reformulation to convert the probabilistic constraints into deterministic forms. An alternating optimization framework is subsequently employed to iteratively update the transmit and reflective beamforming vectors until convergence. Simulation results demonstrate that the proposed distributionally robust scheme significantly enhances secrecy performance, and maintains reliable performance across various channel error distributions.
Energy-Efficient Hybrid Data Computation via Coordinated AirComp and Edge Offloading
Apr 11, 2026The development of 6G networks brings an increasing variety of data services, which motivates the hybrid computation paradigm that coordinates the over-the-air computation (AirComp) and edge computing for diverse and effective data processing. In this paper, we address this emerging issue of hybrid data computation from an energy-efficiency perspective, where the coexistence of both types induces resource competition and interference, and thus complicates the network management. Accordingly, we formulate the problem to minimize the overall energy consumption including the data transmission and computation, subject to the offloading capacity and aggregation accuracy. We then propose a block coordinate descent framework that decomposes and solves the subproblems including the user scheduling, power control, and transceiver scaling, which are then iterated towards a coordinated hybrid computation solution. Simulation results confirm that our coordinated approach achieves significant energy savings compared to baseline strategies, demonstrating its effectiveness in creating a well-coordinated and sustainable hybrid computing environment.
GLM-5: from Vibe Coding to Agentic Engineering
Feb 17, 2026We present GLM-5, a next-generation foundation model designed to transition the paradigm of vibe coding to agentic engineering. Building upon the agentic, reasoning, and coding (ARC) capabilities of its predecessor, GLM-5 adopts DSA to significantly reduce training and inference costs while maintaining long-context fidelity. To advance model alignment and autonomy, we implement a new asynchronous reinforcement learning infrastructure that drastically improves post-training efficiency by decoupling generation from training. Furthermore, we propose novel asynchronous agent RL algorithms that further improve RL quality, enabling the model to learn from complex, long-horizon interactions more effectively. Through these innovations, GLM-5 achieves state-of-the-art performance on major open benchmarks. Most critically, GLM-5 demonstrates unprecedented capability in real-world coding tasks, surpassing previous baselines in handling end-to-end software engineering challenges. Code, models, and more information are available at https://github.com/zai-org/GLM-5.
MM-THEBench: Do Reasoning MLLMs Think Reasonably?
Jan 30, 2026Recent advances in multimodal large language models (MLLMs) mark a shift from non-thinking models to post-trained reasoning models capable of solving complex problems through thinking. However, whether such thinking mitigates hallucinations in multimodal perception and reasoning remains unclear. Self-reflective reasoning enhances robustness but introduces additional hallucinations, and subtle perceptual errors still result in incorrect or coincidentally correct answers. Existing benchmarks primarily focus on models before the emergence of reasoning MLLMs, neglecting the internal thinking process and failing to measure the hallucinations that occur during thinking. To address these challenges, we introduce MM-THEBench, a comprehensive benchmark for assessing hallucinations of intermediate CoTs in reasoning MLLMs. MM-THEBench features a fine-grained taxonomy grounded in cognitive dimensions, diverse data with verified reasoning annotations, and a multi-level automated evaluation framework. Extensive experiments on mainstream reasoning MLLMs reveal insights into how thinking affects hallucination and reasoning capability in various multimodal tasks.
WebSeer: Training Deeper Search Agents through Reinforcement Learning with Self-Reflection
Oct 21, 2025Search agents have achieved significant advancements in enabling intelligent information retrieval and decision-making within interactive environments. Although reinforcement learning has been employed to train agentic models capable of more dynamic interactive retrieval, existing methods are limited by shallow tool-use depth and the accumulation of errors over multiple iterative interactions. In this paper, we present WebSeer, a more intelligent search agent trained via reinforcement learning enhanced with a self-reflection mechanism. Specifically, we construct a large dataset annotated with reflection patterns and design a two-stage training framework that unifies cold start and reinforcement learning within the self-reflection paradigm for real-world web-based environments, which enables the model to generate longer and more reflective tool-use trajectories. Our approach substantially extends tool-use chains and improves answer accuracy. Using a single 14B model, we achieve state-of-the-art results on HotpotQA and SimpleQA, with accuracies of 72.3% and 90.0%, respectively, and demonstrate strong generalization to out-of-distribution datasets. The code is available at https://github.com/99hgz/WebSeer
GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
Aug 08, 2025We present GLM-4.5, an open-source Mixture-of-Experts (MoE) large language model with 355B total parameters and 32B activated parameters, featuring a hybrid reasoning method that supports both thinking and direct response modes. Through multi-stage training on 23T tokens and comprehensive post-training with expert model iteration and reinforcement learning, GLM-4.5 achieves strong performance across agentic, reasoning, and coding (ARC) tasks, scoring 70.1% on TAU-Bench, 91.0% on AIME 24, and 64.2% on SWE-bench Verified. With much fewer parameters than several competitors, GLM-4.5 ranks 3rd overall among all evaluated models and 2nd on agentic benchmarks. We release both GLM-4.5 (355B parameters) and a compact version, GLM-4.5-Air (106B parameters), to advance research in reasoning and agentic AI systems. Code, models, and more information are available at https://github.com/zai-org/GLM-4.5.
How does Transformer Learn Implicit Reasoning?
May 29, 2025

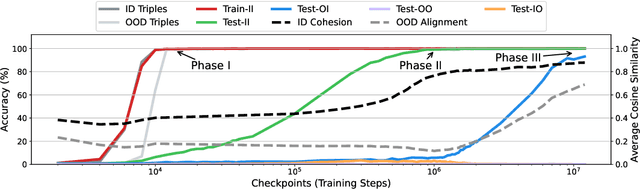

Recent work suggests that large language models (LLMs) can perform multi-hop reasoning implicitly -- producing correct answers without explicitly verbalizing intermediate steps -- but the underlying mechanisms remain poorly understood. In this paper, we study how such implicit reasoning emerges by training transformers from scratch in a controlled symbolic environment. Our analysis reveals a three-stage developmental trajectory: early memorization, followed by in-distribution generalization, and eventually cross-distribution generalization. We find that training with atomic triples is not necessary but accelerates learning, and that second-hop generalization relies on query-level exposure to specific compositional structures. To interpret these behaviors, we introduce two diagnostic tools: cross-query semantic patching, which identifies semantically reusable intermediate representations, and a cosine-based representational lens, which reveals that successful reasoning correlates with the cosine-base clustering in hidden space. This clustering phenomenon in turn provides a coherent explanation for the behavioral dynamics observed across training, linking representational structure to reasoning capability. These findings provide new insights into the interpretability of implicit multi-hop reasoning in LLMs, helping to clarify how complex reasoning processes unfold internally and offering pathways to enhance the transparency of such models.
ReaRAG: Knowledge-guided Reasoning Enhances Factuality of Large Reasoning Models with Iterative Retrieval Augmented Generation
Mar 27, 2025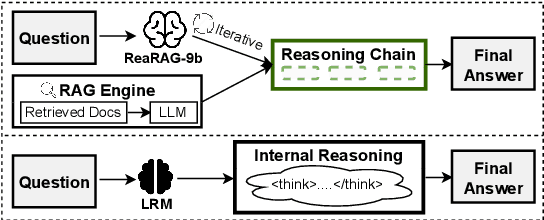
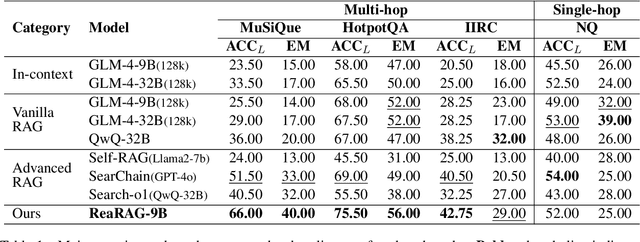
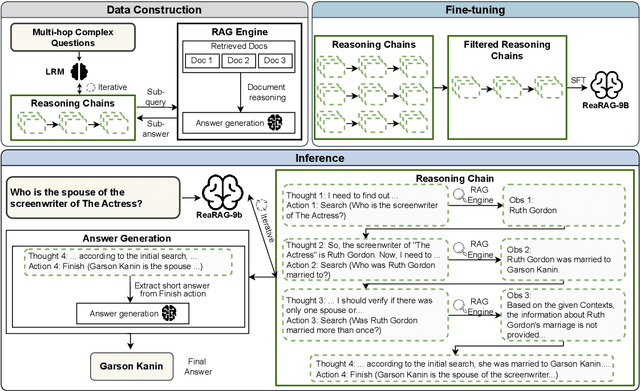

Large Reasoning Models (LRMs) exhibit remarkable reasoning abilities but rely primarily on parametric knowledge, limiting factual accuracy. While recent works equip reinforcement learning (RL)-based LRMs with retrieval capabilities, they suffer from overthinking and lack robustness in reasoning, reducing their effectiveness in question answering (QA) tasks. To address this, we propose ReaRAG, a factuality-enhanced reasoning model that explores diverse queries without excessive iterations. Our solution includes a novel data construction framework with an upper bound on the reasoning chain length. Specifically, we first leverage an LRM to generate deliberate thinking, then select an action from a predefined action space (Search and Finish). For Search action, a query is executed against the RAG engine, where the result is returned as observation to guide reasoning steps later. This process iterates until a Finish action is chosen. Benefiting from ReaRAG's strong reasoning capabilities, our approach outperforms existing baselines on multi-hop QA. Further analysis highlights its strong reflective ability to recognize errors and refine its reasoning trajectory. Our study enhances LRMs' factuality while effectively integrating robust reasoning for Retrieval-Augmented Generation (RAG).
Humanoid-VLA: Towards Universal Humanoid Control with Visual Integration
Feb 21, 2025This paper addresses the limitations of current humanoid robot control frameworks, which primarily rely on reactive mechanisms and lack autonomous interaction capabilities due to data scarcity. We propose Humanoid-VLA, a novel framework that integrates language understanding, egocentric scene perception, and motion control, enabling universal humanoid control. Humanoid-VLA begins with language-motion pre-alignment using non-egocentric human motion datasets paired with textual descriptions, allowing the model to learn universal motion patterns and action semantics. We then incorporate egocentric visual context through a parameter efficient video-conditioned fine-tuning, enabling context-aware motion generation. Furthermore, we introduce a self-supervised data augmentation strategy that automatically generates pseudoannotations directly derived from motion data. This process converts raw motion sequences into informative question-answer pairs, facilitating the effective use of large-scale unlabeled video data. Built upon whole-body control architectures, extensive experiments show that Humanoid-VLA achieves object interaction and environment exploration tasks with enhanced contextual awareness, demonstrating a more human-like capacity for adaptive and intelligent engagement.