 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Vision-language Framework for Comparative Reasoning in Radiology
Jun 04, 2026Medical imaging artificial intelligence has achieved strong performance in isolated image interpretation, but remains poorly aligned with radiological practice, where diagnosis and follow-up rely on comparison across prior studies and analogous reference cases. Here we formulate radiological comparison as an entity-aware cross-image reasoning problem and introduce a framework that supports both reference-case retrieval and temporal comparative interpretation. We construct MedReCo-DB, a large-scale comparative imaging resource derived from routine image-report pairs, comprising more than 690,000 images from over 160,000 patients across eight institutions, four countries and seven imaging modalities. Reports are decomposed into anatomical structures, abnormal findings and pathological conditions to provide supervision for entity-conditioned retrieval and comparative visual question answering. Using this resource, we develop MedReCo, an entity-aware visual encoder for controllable retrieval of clinically analogous cases, and MedReCo-VLM, a vision--language extension for generative interpretation of interval change. Across internal, external and cross-center evaluations, MedReCo achieved the highest Recall@1 in all 12 internal retrieval settings and improved external retrieval by a mean of 6.0 percentage points. In clinically confusable differential groups, it consistently outperformed the strongest baselines. MedReCo-VLM achieved the best performance across all comparative generation evaluations and improved longitudinal follow-up accuracy by 14.5-46.5 percentage points on chest radiographs and 13.0-27.9 percentage points on CT. These findings suggest that entity-aware comparative reasoning can be learned from routine clinical data at scale and may provide a more clinically aligned foundation for medical imaging AI.
Evaluating Large Language Models in Dynamic Clinical Decision-Making with Standardized Patient Cases
Jun 03, 2026Large language models (LLMs) are increasingly proposed as clinical agents, yet static, single-turn benchmarks cannot capture how a model dynamically delivers care across an encounter: gathering information, planning treatment, and adapting longitudinal management across successive patient states. Medical education has long addressed an analogous challenge through standardized patients (SPs): trained actors who consistently portray clinical cases, enabling realistic practice and objective, scripted assessment. Here we introduce MedSP1000, an SP-derived interactive benchmark for clinical-agent evaluation, including 1,638 SP cases with 24,602 trajectory-level peer-reviewed rubrics. MedSP1000 converts peer-reviewed SP teaching cases into executable scenarios with defined SP case scripts, clinical environment contexts, and human-validated structured rubric. In each simulation evaluation run, a clinical agent interacts in closed loop with a patient agent and an environment controller, and its behaviour is scored throughout the encounter against expert criteria specified in the original materials. Applying MedSP1000 to a range of general-purpose and medically specialized LLMs, we find that performance on static benchmarks does not reliably translate to such educational scenarios. The best-performing model, GPT-5.5, completes only 60.4% of expert-defined rubric items, whereas the strongest medically specialized model reaches 40.0%; increasing test-time compute produces no measurable gain. These results suggest that current LLMs, including agentic systems tuned for medicine, are not yet reliable enough to be safely integrated into actual clinical practice. More broadly, MedSP1000 shows how process-level, SP-style evaluation can reveal clinically relevant failure modes that single-turn benchmarks miss.
Quantifying the Reasoning Abilities of LLMs on Real-world Clinical Cases
Mar 06, 2025

The latest reasoning-enhanced large language models (reasoning LLMs), such as DeepSeek-R1 and OpenAI-o3, have demonstrated remarkable success. However, the application of such reasoning enhancements to the highly professional medical domain has not been clearly evaluated, particularly regarding with not only assessing the final generation but also examining the quality of their reasoning processes. In this study, we present MedR-Bench, a reasoning-focused medical evaluation benchmark comprising 1,453 structured patient cases with reasoning references mined from case reports. Our benchmark spans 13 body systems and 10 specialty disorders, encompassing both common and rare diseases. In our evaluation, we introduce a versatile framework consisting of three critical clinical stages: assessment recommendation, diagnostic decision-making, and treatment planning, comprehensively capturing the LLMs' performance across the entire patient journey in healthcare. For metrics, we propose a novel agentic system, Reasoning Evaluator, designed to automate and objectively quantify free-text reasoning responses in a scalable manner from the perspectives of efficiency, factuality, and completeness by dynamically searching and performing cross-referencing checks. As a result, we assess five state-of-the-art reasoning LLMs, including DeepSeek-R1, OpenAI-o3-mini, and others. Our results reveal that current LLMs can handle relatively simple diagnostic tasks with sufficient critical assessment results, achieving accuracy generally over 85%. However, they still struggle with more complex tasks, such as assessment recommendation and treatment planning. In reasoning, their reasoning processes are generally reliable, with factuality scores exceeding 90%, though they often omit critical reasoning steps. Our study clearly reveals further development directions for current clinical LLMs.
Can Modern LLMs Act as Agent Cores in Radiology~Environments?
Dec 12, 2024

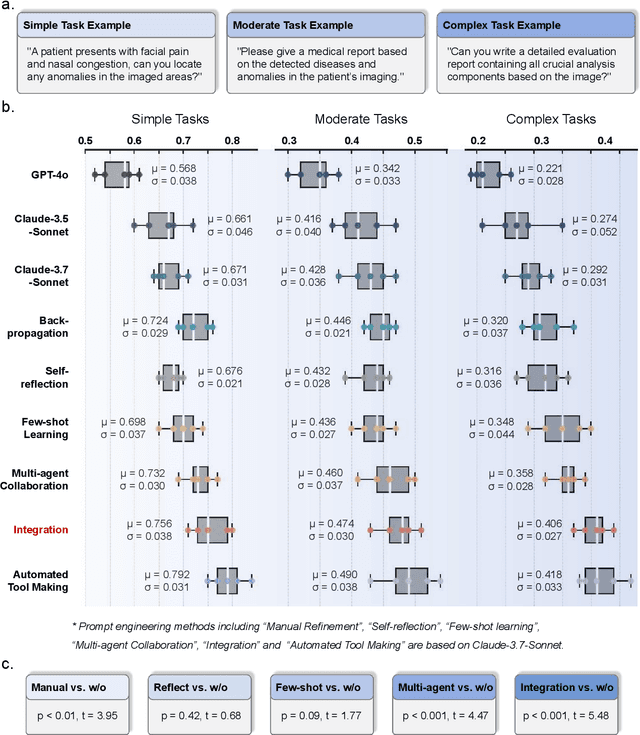

Advancements in large language models (LLMs) have paved the way for LLM-based agent systems that offer enhanced accuracy and interpretability across various domains. Radiology, with its complex analytical requirements, is an ideal field for the application of these agents. This paper aims to investigate the pre-requisite question for building concrete radiology agents which is, `Can modern LLMs act as agent cores in radiology environments?' To investigate it, we introduce RadABench with three-fold contributions: First, we present RadABench-Data, a comprehensive synthetic evaluation dataset for LLM-based agents, generated from an extensive taxonomy encompassing 6 anatomies, 5 imaging modalities, 10 tool categories, and 11 radiology tasks. Second, we propose RadABench-EvalPlat, a novel evaluation platform for agents featuring a prompt-driven workflow and the capability to simulate a wide range of radiology toolsets. Third, we assess the performance of 7 leading LLMs on our benchmark from 5 perspectives with multiple metrics. Our findings indicate that while current LLMs demonstrate strong capabilities in many areas, they are still not sufficiently advanced to serve as the central agent core in a fully operational radiology agent system. Additionally, we identify key factors influencing the performance of LLM-based agent cores, offering insights for clinicians on how to apply agent systems in real-world radiology practices effectively. All of our code and data are open-sourced in https://github.com/MAGIC-AI4Med/RadABench.
Towards Evaluating and Building Versatile Large Language Models for Medicine
Aug 22, 2024In this study, we present MedS-Bench, a comprehensive benchmark designed to evaluate the performance of large language models (LLMs) in clinical contexts. Unlike existing benchmarks that focus on multiple-choice question answering, MedS-Bench spans 11 high-level clinical tasks, including clinical report summarization, treatment recommendations, diagnosis, named entity recognition, and medical concept explanation, among others. We evaluated six leading LLMs, e.g., MEDITRON, Mistral, InternLM 2, Llama 3, GPT-4, and Claude-3.5 using few-shot prompting, and found that even the most sophisticated models struggle with these complex tasks. To address these limitations, we developed MedS-Ins, a large-scale instruction tuning dataset for medicine. MedS-Ins comprises 58 medically oriented language corpora, totaling 13.5 million samples across 122 tasks. To demonstrate the dataset's utility, we conducted a proof-of-concept experiment by performing instruction tuning on a lightweight, open-source medical language model. The resulting model, MMedIns-Llama 3, significantly outperformed existing models across nearly all clinical tasks. To promote further advancements in the application of LLMs to clinical challenges, we have made the MedS-Ins dataset fully accessible and invite the research community to contribute to its expansion.Additionally, we have launched a dynamic leaderboard for MedS-Bench, which we plan to regularly update the test set to track progress and enhance the adaptation of general LLMs to the medical domain. Leaderboard: https://henrychur.github.io/MedS-Bench/. Github: https://github.com/MAGIC-AI4Med/MedS-Ins.
Towards Building Multilingual Language Model for Medicine
Feb 26, 2024



In this paper, we aim to develop an open-source, multilingual language model for medicine, that the benefits a wider, linguistically diverse audience from different regions. In general, we present the contribution from the following aspects: first, for multilingual medical-specific adaptation, we construct a new multilingual medical corpus, that contains approximately 25.5B tokens encompassing 6 main languages, termed as MMedC, that enables auto-regressive training for existing general LLMs. second, to monitor the development of multilingual LLMs in medicine, we propose a new multilingual medical multi-choice question-answering benchmark with rationale, termed as MMedBench; third, we have assessed a number of popular, opensource large language models (LLMs) on our benchmark, along with those further auto-regressive trained on MMedC, as a result, our final model, termed as MMedLM 2, with only 7B parameters, achieves superior performance compared to all other open-source models, even rivaling GPT-4 on MMedBench. We will make the resources publicly available, including code, model weights, and datasets.