 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReX-MLE: The Autonomous Agent Benchmark for Medical Imaging Challenges
Dec 19, 2025
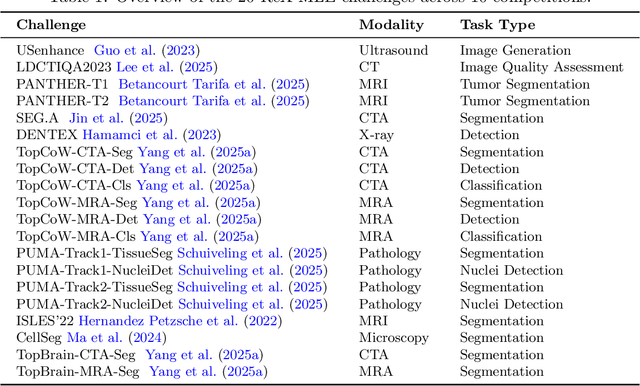


Autonomous coding agents built on large language models (LLMs) can now solve many general software and machine learning tasks, but they remain ineffective on complex, domain-specific scientific problems. Medical imaging is a particularly demanding domain, requiring long training cycles, high-dimensional data handling, and specialized preprocessing and validation pipelines, capabilities not fully measured in existing agent benchmarks. To address this gap, we introduce ReX-MLE, a benchmark of 20 challenges derived from high-impact medical imaging competitions spanning diverse modalities and task types. Unlike prior ML-agent benchmarks, ReX-MLE evaluates full end-to-end workflows, requiring agents to independently manage data preprocessing, model training, and submission under realistic compute and time constraints. Evaluating state-of-the-art agents (AIDE, ML-Master, R&D-Agent) with different LLM backends (GPT-5, Gemini, Claude), we observe a severe performance gap: most submissions rank in the 0th percentile compared to human experts. Failures stem from domain-knowledge and engineering limitations. ReX-MLE exposes these bottlenecks and provides a foundation for developing domain-aware autonomous AI systems.
ReXGroundingCT: A 3D Chest CT Dataset for Segmentation of Findings from Free-Text Reports
Jul 29, 2025We present ReXGroundingCT, the first publicly available dataset to link free-text radiology findings with pixel-level segmentations in 3D chest CT scans that is manually annotated. While prior datasets have relied on structured labels or predefined categories, ReXGroundingCT captures the full expressiveness of clinical language represented in free text and grounds it to spatially localized 3D segmentation annotations in volumetric imaging. This addresses a critical gap in medical AI: the ability to connect complex, descriptive text, such as "3 mm nodule in the left lower lobe", to its precise anatomical location in three-dimensional space, a capability essential for grounded radiology report generation systems. The dataset comprises 3,142 non-contrast chest CT scans paired with standardized radiology reports from the CT-RATE dataset. Using a systematic three-stage pipeline, GPT-4 was used to extract positive lung and pleural findings, which were then manually segmented by expert annotators. A total of 8,028 findings across 16,301 entities were annotated, with quality control performed by board-certified radiologists. Approximately 79% of findings are focal abnormalities, while 21% are non-focal. The training set includes up to three representative segmentations per finding, while the validation and test sets contain exhaustive labels for each finding entity. ReXGroundingCT establishes a new benchmark for developing and evaluating sentence-level grounding and free-text medical segmentation models in chest CT. The dataset can be accessed at https://huggingface.co/datasets/rajpurkarlab/ReXGroundingCT.
ReXVQA: A Large-scale Visual Question Answering Benchmark for Generalist Chest X-ray Understanding
Jun 04, 2025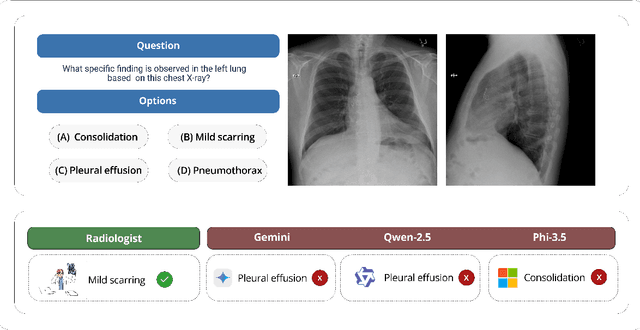
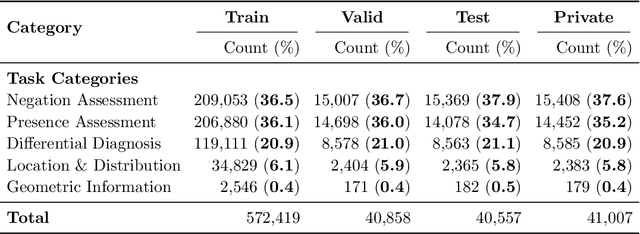
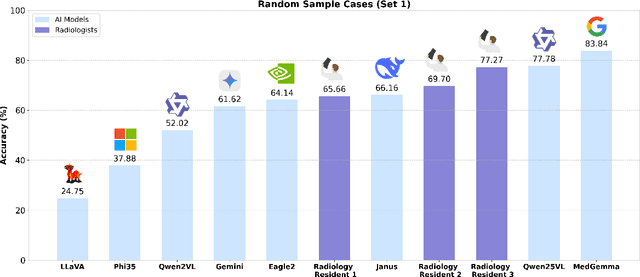
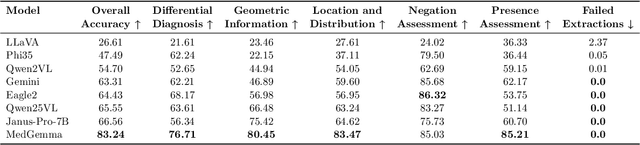
We present ReXVQA, the largest and most comprehensive benchmark for visual question answering (VQA) in chest radiology, comprising approximately 696,000 questions paired with 160,000 chest X-rays studies across training, validation, and test sets. Unlike prior efforts that rely heavily on template based queries, ReXVQA introduces a diverse and clinically authentic task suite reflecting five core radiological reasoning skills: presence assessment, location analysis, negation detection, differential diagnosis, and geometric reasoning. We evaluate eight state-of-the-art multimodal large language models, including MedGemma-4B-it, Qwen2.5-VL, Janus-Pro-7B, and Eagle2-9B. The best-performing model (MedGemma) achieves 83.24% overall accuracy. To bridge the gap between AI performance and clinical expertise, we conducted a comprehensive human reader study involving 3 radiology residents on 200 randomly sampled cases. Our evaluation demonstrates that MedGemma achieved superior performance (83.84% accuracy) compared to human readers (best radiology resident: 77.27%), representing a significant milestone where AI performance exceeds expert human evaluation on chest X-ray interpretation. The reader study reveals distinct performance patterns between AI models and human experts, with strong inter-reader agreement among radiologists while showing more variable agreement patterns between human readers and AI models. ReXVQA establishes a new standard for evaluating generalist radiological AI systems, offering public leaderboards, fine-grained evaluation splits, structured explanations, and category-level breakdowns. This benchmark lays the foundation for next-generation AI systems capable of mimicking expert-level clinical reasoning beyond narrow pathology classification. Our dataset will be open-sourced at https://huggingface.co/datasets/rajpurkarlab/ReXVQA
ReXGradient-160K: A Large-Scale Publicly Available Dataset of Chest Radiographs with Free-text Reports
May 01, 2025We present ReXGradient-160K, representing the largest publicly available chest X-ray dataset to date in terms of the number of patients. This dataset contains 160,000 chest X-ray studies with paired radiological reports from 109,487 unique patients across 3 U.S. health systems (79 medical sites). This comprehensive dataset includes multiple images per study and detailed radiology reports, making it particularly valuable for the development and evaluation of AI systems for medical imaging and automated report generation models. The dataset is divided into training (140,000 studies), validation (10,000 studies), and public test (10,000 studies) sets, with an additional private test set (10,000 studies) reserved for model evaluation on the ReXrank benchmark. By providing this extensive dataset, we aim to accelerate research in medical imaging AI and advance the state-of-the-art in automated radiological analysis. Our dataset will be open-sourced at https://huggingface.co/datasets/rajpurkarlab/ReXGradient-160K.
FactCheXcker: Mitigating Measurement Hallucinations in Chest X-ray Report Generation Models
Nov 27, 2024



Medical vision-language model models often struggle with generating accurate quantitative measurements in radiology reports, leading to hallucinations that undermine clinical reliability. We introduce FactCheXcker, a modular framework that de-hallucinates radiology report measurements by leveraging an improved query-code-update paradigm. Specifically, FactCheXcker employs specialized modules and the code generation capabilities of large language models to solve measurement queries generated based on the original report. After extracting measurable findings, the results are incorporated into an updated report. We evaluate FactCheXcker on endotracheal tube placement, which accounts for an average of 78% of report measurements, using the MIMIC-CXR dataset and 11 medical report-generation models. Our results show that FactCheXcker significantly reduces hallucinations, improves measurement precision, and maintains the quality of the original reports. Specifically, FactCheXcker improves the performance of all 11 models and achieves an average improvement of 94.0% in reducing measurement hallucinations measured by mean absolute error.
ReXrank: A Public Leaderboard for AI-Powered Radiology Report Generation
Nov 22, 2024



AI-driven models have demonstrated significant potential in automating radiology report generation for chest X-rays. However, there is no standardized benchmark for objectively evaluating their performance. To address this, we present ReXrank, https://rexrank.ai, a public leaderboard and challenge for assessing AI-powered radiology report generation. Our framework incorporates ReXGradient, the largest test dataset consisting of 10,000 studies, and three public datasets (MIMIC-CXR, IU-Xray, CheXpert Plus) for report generation assessment. ReXrank employs 8 evaluation metrics and separately assesses models capable of generating only findings sections and those providing both findings and impressions sections. By providing this standardized evaluation framework, ReXrank enables meaningful comparisons of model performance and offers crucial insights into their robustness across diverse clinical settings. Beyond its current focus on chest X-rays, ReXrank's framework sets the stage for comprehensive evaluation of automated reporting across the full spectrum of medical imaging.
ReXplain: Translating Radiology into Patient-Friendly Video Reports
Oct 01, 2024



Radiology reports often remain incomprehensible to patients, undermining patient-centered care. We present ReXplain (Radiology eXplanation), an innovative AI-driven system that generates patient-friendly video reports for radiology findings. ReXplain uniquely integrates a large language model for text simplification, an image segmentation model for anatomical region identification, and an avatar generation tool, producing comprehensive explanations with plain language, highlighted imagery, and 3D organ renderings. Our proof-of-concept study with five board-certified radiologists indicates that ReXplain could accurately deliver radiological information and effectively simulate one-on-one consultations. This work demonstrates a new paradigm in AI-assisted medical communication, potentially improving patient engagement and satisfaction in radiology care, and opens new avenues for research in multimodal medical communication.
Uncovering Knowledge Gaps in Radiology Report Generation Models through Knowledge Graphs
Aug 26, 2024



Recent advancements in artificial intelligence have significantly improved the automatic generation of radiology reports. However, existing evaluation methods fail to reveal the models' understanding of radiological images and their capacity to achieve human-level granularity in descriptions. To bridge this gap, we introduce a system, named ReXKG, which extracts structured information from processed reports to construct a comprehensive radiology knowledge graph. We then propose three metrics to evaluate the similarity of nodes (ReXKG-NSC), distribution of edges (ReXKG-AMS), and coverage of subgraphs (ReXKG-SCS) across various knowledge graphs. We conduct an in-depth comparative analysis of AI-generated and human-written radiology reports, assessing the performance of both specialist and generalist models. Our study provides a deeper understanding of the capabilities and limitations of current AI models in radiology report generation, offering valuable insights for improving model performance and clinical applicability.
AutoRG-Brain: Grounded Report Generation for Brain MRI
Jul 26, 2024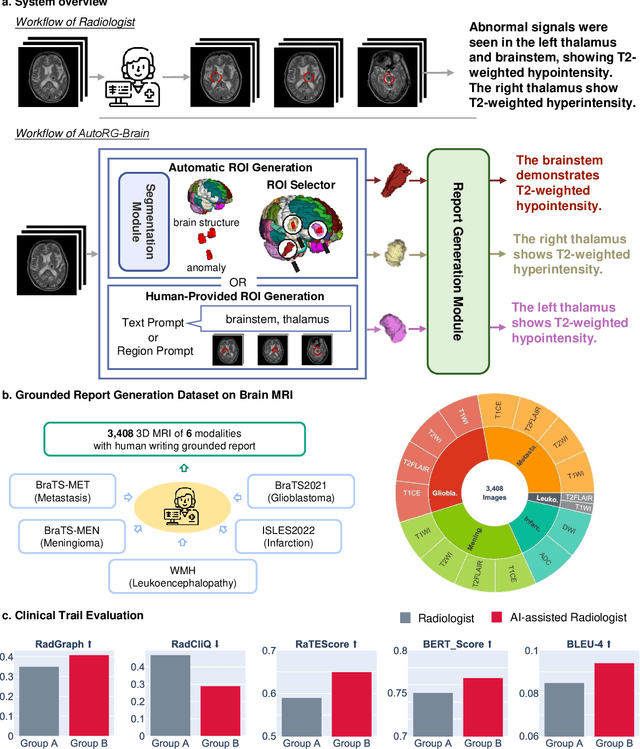
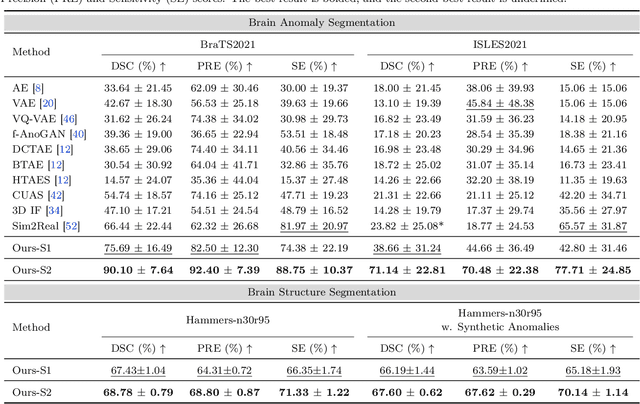
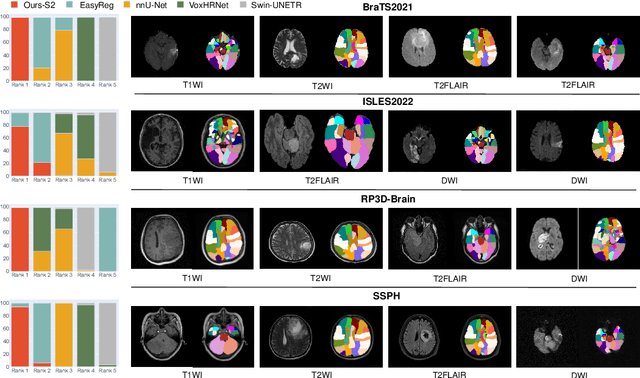
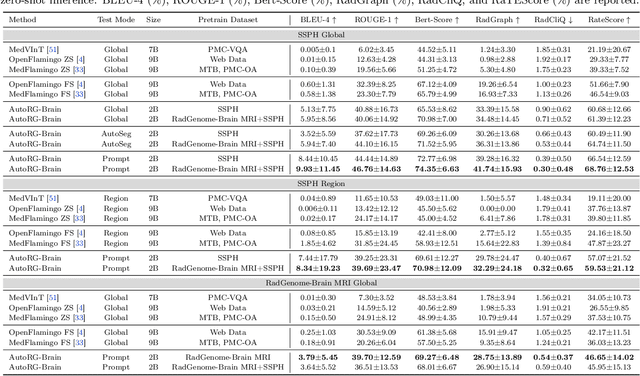
Radiologists are tasked with interpreting a large number of images in a daily base, with the responsibility of generating corresponding reports. This demanding workload elevates the risk of human error, potentially leading to treatment delays, increased healthcare costs, revenue loss, and operational inefficiencies. To address these challenges, we initiate a series of work on grounded Automatic Report Generation (AutoRG), starting from the brain MRI interpretation system, which supports the delineation of brain structures, the localization of anomalies, and the generation of well-organized findings. We make contributions from the following aspects, first, on dataset construction, we release a comprehensive dataset encompassing segmentation masks of anomaly regions and manually authored reports, termed as RadGenome-Brain MRI. This data resource is intended to catalyze ongoing research and development in the field of AI-assisted report generation systems. Second, on system design, we propose AutoRG-Brain, the first brain MRI report generation system with pixel-level grounded visual clues. Third, for evaluation, we conduct quantitative assessments and human evaluations of brain structure segmentation, anomaly localization, and report generation tasks to provide evidence of its reliability and accuracy. This system has been integrated into real clinical scenarios, where radiologists were instructed to write reports based on our generated findings and anomaly segmentation masks. The results demonstrate that our system enhances the report-writing skills of junior doctors, aligning their performance more closely with senior doctors, thereby boosting overall productivity.
RaTEScore: A Metric for Radiology Report Generation
Jun 24, 2024This paper introduces a novel, entity-aware metric, termed as Radiological Report (Text) Evaluation (RaTEScore), to assess the quality of medical reports generated by AI models. RaTEScore emphasizes crucial medical entities such as diagnostic outcomes and anatomical details, and is robust against complex medical synonyms and sensitive to negation expressions. Technically, we developed a comprehensive medical NER dataset, RaTE-NER, and trained an NER model specifically for this purpose. This model enables the decomposition of complex radiological reports into constituent medical entities. The metric itself is derived by comparing the similarity of entity embeddings, obtained from a language model, based on their types and relevance to clinical significance. Our evaluations demonstrate that RaTEScore aligns more closely with human preference than existing metrics, validated both on established public benchmarks and our newly proposed RaTE-Eval benchmark.