 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMEDMKG: Benchmarking Medical Knowledge Exploitation with Multimodal Knowledge Graph
May 22, 2025Medical deep learning models depend heavily on domain-specific knowledge to perform well on knowledge-intensive clinical tasks. Prior work has primarily leveraged unimodal knowledge graphs, such as the Unified Medical Language System (UMLS), to enhance model performance. However, integrating multimodal medical knowledge graphs remains largely underexplored, mainly due to the lack of resources linking imaging data with clinical concepts. To address this gap, we propose MEDMKG, a Medical Multimodal Knowledge Graph that unifies visual and textual medical information through a multi-stage construction pipeline. MEDMKG fuses the rich multimodal data from MIMIC-CXR with the structured clinical knowledge from UMLS, utilizing both rule-based tools and large language models for accurate concept extraction and relationship modeling. To ensure graph quality and compactness, we introduce Neighbor-aware Filtering (NaF), a novel filtering algorithm tailored for multimodal knowledge graphs. We evaluate MEDMKG across three tasks under two experimental settings, benchmarking twenty-four baseline methods and four state-of-the-art vision-language backbones on six datasets. Results show that MEDMKG not only improves performance in downstream medical tasks but also offers a strong foundation for developing adaptive and robust strategies for multimodal knowledge integration in medical artificial intelligence.
Can Modern LLMs Act as Agent Cores in Radiology~Environments?
Dec 12, 2024Advancements in large language models (LLMs) have paved the way for LLM-based agent systems that offer enhanced accuracy and interpretability across various domains. Radiology, with its complex analytical requirements, is an ideal field for the application of these agents. This paper aims to investigate the pre-requisite question for building concrete radiology agents which is, `Can modern LLMs act as agent cores in radiology environments?' To investigate it, we introduce RadABench with three-fold contributions: First, we present RadABench-Data, a comprehensive synthetic evaluation dataset for LLM-based agents, generated from an extensive taxonomy encompassing 6 anatomies, 5 imaging modalities, 10 tool categories, and 11 radiology tasks. Second, we propose RadABench-EvalPlat, a novel evaluation platform for agents featuring a prompt-driven workflow and the capability to simulate a wide range of radiology toolsets. Third, we assess the performance of 7 leading LLMs on our benchmark from 5 perspectives with multiple metrics. Our findings indicate that while current LLMs demonstrate strong capabilities in many areas, they are still not sufficiently advanced to serve as the central agent core in a fully operational radiology agent system. Additionally, we identify key factors influencing the performance of LLM-based agent cores, offering insights for clinicians on how to apply agent systems in real-world radiology practices effectively. All of our code and data are open-sourced in https://github.com/MAGIC-AI4Med/RadABench.
AutoRG-Brain: Grounded Report Generation for Brain MRI
Jul 26, 2024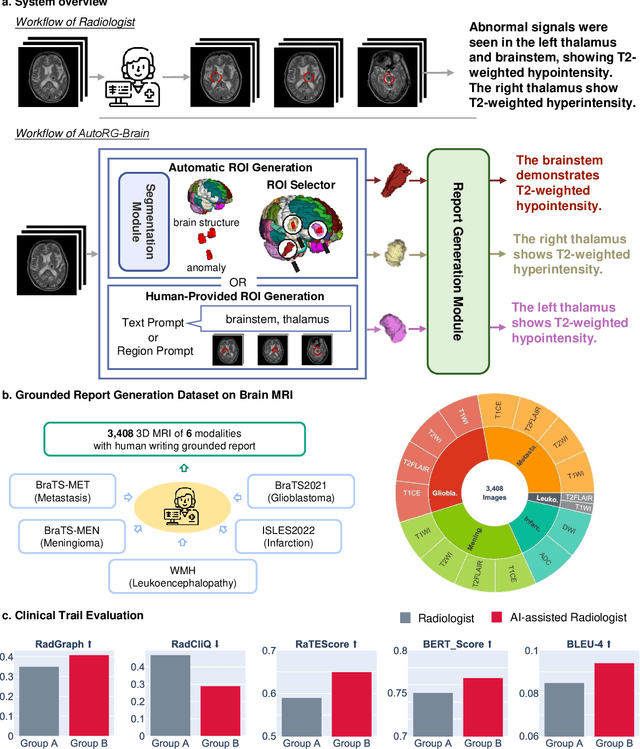
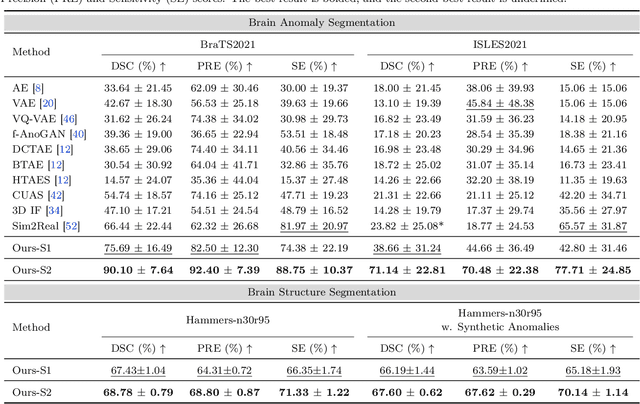
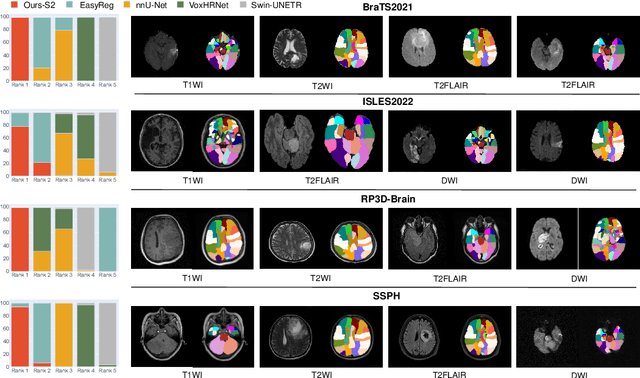
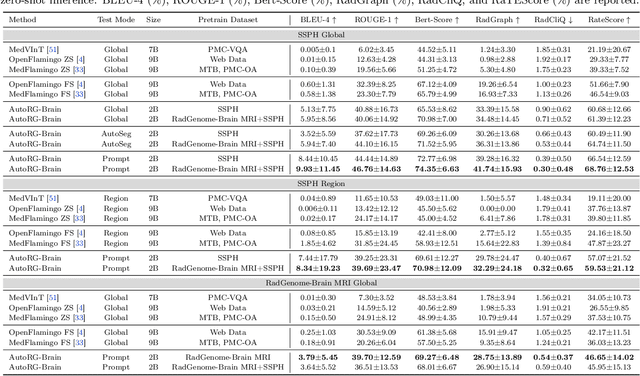
Radiologists are tasked with interpreting a large number of images in a daily base, with the responsibility of generating corresponding reports. This demanding workload elevates the risk of human error, potentially leading to treatment delays, increased healthcare costs, revenue loss, and operational inefficiencies. To address these challenges, we initiate a series of work on grounded Automatic Report Generation (AutoRG), starting from the brain MRI interpretation system, which supports the delineation of brain structures, the localization of anomalies, and the generation of well-organized findings. We make contributions from the following aspects, first, on dataset construction, we release a comprehensive dataset encompassing segmentation masks of anomaly regions and manually authored reports, termed as RadGenome-Brain MRI. This data resource is intended to catalyze ongoing research and development in the field of AI-assisted report generation systems. Second, on system design, we propose AutoRG-Brain, the first brain MRI report generation system with pixel-level grounded visual clues. Third, for evaluation, we conduct quantitative assessments and human evaluations of brain structure segmentation, anomaly localization, and report generation tasks to provide evidence of its reliability and accuracy. This system has been integrated into real clinical scenarios, where radiologists were instructed to write reports based on our generated findings and anomaly segmentation masks. The results demonstrate that our system enhances the report-writing skills of junior doctors, aligning their performance more closely with senior doctors, thereby boosting overall productivity.
MD-IQA: Learning Multi-scale Distributed Image Quality Assessment with Semi Supervised Learning for Low Dose CT
Nov 14, 2023Image quality assessment (IQA) plays a critical role in optimizing radiation dose and developing novel medical imaging techniques in computed tomography (CT). Traditional IQA methods relying on hand-crafted features have limitations in summarizing the subjective perceptual experience of image quality. Recent deep learning-based approaches have demonstrated strong modeling capabilities and potential for medical IQA, but challenges remain regarding model generalization and perceptual accuracy. In this work, we propose a multi-scale distributions regression approach to predict quality scores by constraining the output distribution, thereby improving model generalization. Furthermore, we design a dual-branch alignment network to enhance feature extraction capabilities. Additionally, semi-supervised learning is introduced by utilizing pseudo-labels for unlabeled data to guide model training. Extensive qualitative experiments demonstrate the effectiveness of our proposed method for advancing the state-of-the-art in deep learning-based medical IQA. Code is available at: https://github.com/zunzhumu/MD-IQA.
UniBrain: Universal Brain MRI Diagnosis with Hierarchical Knowledge-enhanced Pre-training
Sep 13, 2023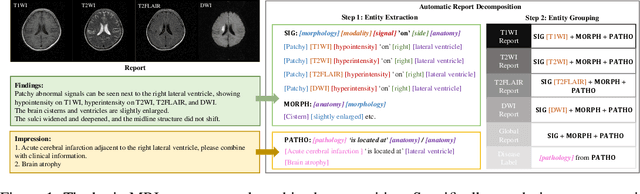
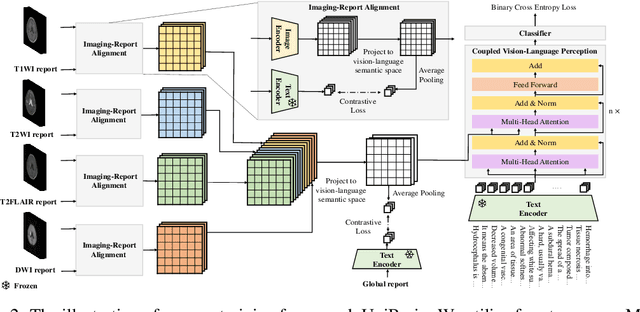

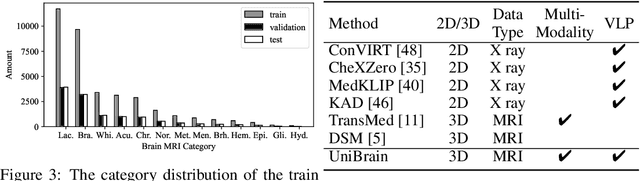
Magnetic resonance imaging~(MRI) have played a crucial role in brain disease diagnosis, with which a range of computer-aided artificial intelligence methods have been proposed. However, the early explorations usually focus on the limited types of brain diseases in one study and train the model on the data in a small scale, yielding the bottleneck of generalization. Towards a more effective and scalable paradigm, we propose a hierarchical knowledge-enhanced pre-training framework for the universal brain MRI diagnosis, termed as UniBrain. Specifically, UniBrain leverages a large-scale dataset of 24,770 imaging-report pairs from routine diagnostics. Different from previous pre-training techniques for the unitary vision or textual feature, or with the brute-force alignment between vision and language information, we leverage the unique characteristic of report information in different granularity to build a hierarchical alignment mechanism, which strengthens the efficiency in feature learning. Our UniBrain is validated on three real world datasets with severe class imbalance and the public BraTS2019 dataset. It not only consistently outperforms all state-of-the-art diagnostic methods by a large margin and provides a superior grounding performance but also shows comparable performance compared to expert radiologists on certain disease types.