 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTriSpec: Ternary Speculative Decoding via Lightweight Proxy Verification
Jan 30, 2026Inference efficiency in Large Language Models (LLMs) is fundamentally limited by their serial, autoregressive generation, especially as reasoning becomes a key capability and response sequences grow longer. Speculative decoding (SD) offers a powerful solution, providing significant speed-ups through its lightweight drafting and parallel verification mechanism. While existing work has nearly saturated improvements in draft effectiveness and efficiency, this paper advances SD from a new yet critical perspective: the verification cost. We propose TriSpec, a novel ternary SD framework that, at its core, introduces a lightweight proxy to significantly reduce computational cost by approving easily verifiable draft sequences and engaging the full target model only when encountering uncertain tokens. TriSpec can be integrated with state-of-the-art SD methods like EAGLE-3 to further reduce verification costs, achieving greater acceleration. Extensive experiments on the Qwen3 and DeepSeek-R1-Distill-Qwen/LLaMA families show that TriSpec achieves up to 35\% speedup over standard SD, with up to 50\% fewer target model invocations while maintaining comparable accuracy.
UniBrain: Universal Brain MRI Diagnosis with Hierarchical Knowledge-enhanced Pre-training
Sep 13, 2023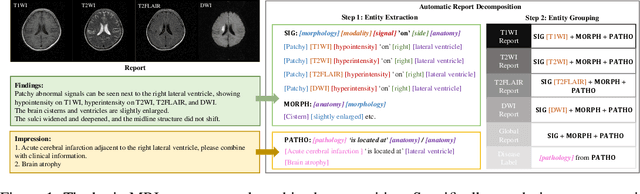
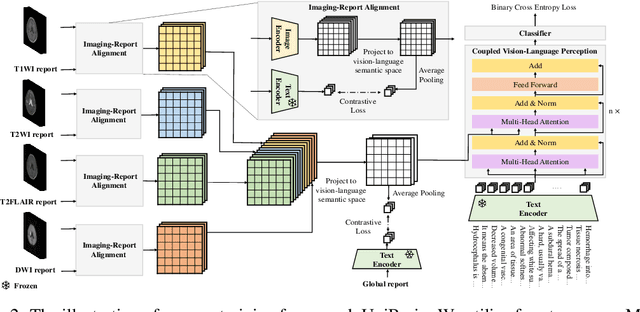

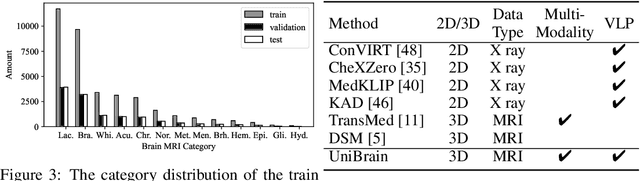
Magnetic resonance imaging~(MRI) have played a crucial role in brain disease diagnosis, with which a range of computer-aided artificial intelligence methods have been proposed. However, the early explorations usually focus on the limited types of brain diseases in one study and train the model on the data in a small scale, yielding the bottleneck of generalization. Towards a more effective and scalable paradigm, we propose a hierarchical knowledge-enhanced pre-training framework for the universal brain MRI diagnosis, termed as UniBrain. Specifically, UniBrain leverages a large-scale dataset of 24,770 imaging-report pairs from routine diagnostics. Different from previous pre-training techniques for the unitary vision or textual feature, or with the brute-force alignment between vision and language information, we leverage the unique characteristic of report information in different granularity to build a hierarchical alignment mechanism, which strengthens the efficiency in feature learning. Our UniBrain is validated on three real world datasets with severe class imbalance and the public BraTS2019 dataset. It not only consistently outperforms all state-of-the-art diagnostic methods by a large margin and provides a superior grounding performance but also shows comparable performance compared to expert radiologists on certain disease types.