 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnlocking air traffic flow prediction through microscopic aircraft-state modeling
May 11, 2026Short-term air traffic flow prediction in terminal airspace is essential for proactive air traffic management. Existing approaches predominantly model traffic flow as aggregated time series, despite traffic dynamics being governed by aircraft states and interactions in continuous airspace. Such aggregation obscures fine-grained information including aircraft kinematics, boundary interactions, and control intent. Here we present AeroSense, a state-to-flow modeling framework that predicts future traffic flow directly from instantaneous airspace situations represented as dynamic sets of aircraft states derived from ADS-B trajectories. By establishing an end-to-end mapping from microscopic aircraft states to future regional traffic flow, AeroSense preserves aircraft-level dynamics while naturally accommodating varying traffic density without relying on historical look-back windows. Experiments on a large-scale real-world dataset show that AeroSense consistently improves predictive accuracy over aggregation-based forecasting approaches, particularly during high-density traffic periods. These findings suggest that instantaneous airspace situations provide an effective alternative to conventional time-series-based traffic forecasting paradigms.
From Time Series to State: Situation-Aware Modeling for Air Traffic Flow Prediction
Apr 16, 2026Accurate air traffic prediction in the terminal airspace (TA) is pivotal for proactive air traffic management (ATM). However, existing data-driven approaches predominantly rely on time series-based forecasting paradigms, which inherently overlook critical aircraft state information, such as real-time kinematics and proximity to airspace boundaries. To address this limitation, we propose \textit{AeroSense}, a direct state-to-flow modeling framework for air traffic prediction. Unlike classical time series-based methods that first aggregate aircraft trajectories into macroscopic flow sequences before modeling, AeroSense explicitly represents the real-time airspace situation as \textit{a dynamic set of aircraft states}, enabling the direct processing of a variable number of aircraft instead of time series as inputs. Specifically, we introduce a situation-aware state representation that enables AeroSense to sense the instantaneous terminal airspace situation directly from microscopic aircraft states. Furthermore, we design a model architecture that incorporates masked self-attention to capture inter-aircraft interactions, together with two decoupled prediction heads to model heterogeneous flow dynamics across two key functional areas of the TA. Extensive experiments on a large-scale real-world airport dataset demonstrate that AeroSense consistently achieves state-of-the-art performance, validating that direct modeling of microscopic aircraft states yields substantially higher predictive fidelity than time series-based baselines. Moreover, the proposed framework exhibits superior robustness during peak traffic periods, achieves Pareto-optimal performance under dayparting multi-object evaluation, and provides meaningful interpretability through attention-based visualizations.
Towards Situation-aware State Modeling for Air Traffic Flow Prediction
Apr 14, 2026Accurate air traffic prediction in the terminal airspace (TA) is pivotal for proactive air traffic management (ATM). However, existing data-driven approaches predominantly rely on time series-based forecasting paradigms, which inherently overlook critical aircraft state information, such as real-time kinematics and proximity to airspace boundaries. To address this limitation, we propose \textit{AeroSense}, a direct state-to-flow modeling framework for air traffic prediction. Unlike classical time series-based methods that first aggregate aircraft trajectories into macroscopic flow sequences before modeling, AeroSense explicitly represents the real-time airspace situation as \textit{a dynamic set of aircraft states}, enabling the direct processing of a variable number of aircraft instead of time series as inputs. Specifically, we introduce a situation-aware state representation that enables AeroSense to sense the instantaneous terminal airspace situation directly from microscopic aircraft states. Furthermore, we design a model architecture that incorporates masked self-attention to capture inter-aircraft interactions, together with two decoupled prediction heads to model heterogeneous flow dynamics across two key functional areas of the TA. Extensive experiments on a large-scale real-world airport dataset demonstrate that AeroSense consistently achieves state-of-the-art performance, validating that direct modeling of microscopic aircraft states yields substantially higher predictive fidelity than time series-based baselines. Moreover, the proposed framework exhibits superior robustness during peak traffic periods, achieves Pareto-optimal performance under dayparting multi-object evaluation, and provides meaningful interpretability through attention-based visualizations.
Rejection Mixing: Fast Semantic Propagation of Mask Tokens for Efficient DLLM Inference
Feb 26, 2026Diffusion Large Language Models (DLLMs) promise fast non-autoregressive inference but suffer a severe quality-speed trade-off in parallel decoding. This stems from the ''combinatorial contradiction'' phenomenon, where parallel tokens form semantically inconsistent combinations. We address this by integrating continuous representations into the discrete decoding process, as they preserve rich inter-position dependency. We propose ReMix (Rejection Mixing), a framework that introduces a novel Continuous Mixing State as an intermediate between the initial masked state and the final decoded token state. This intermediate state allows a token's representation to be iteratively refined in a continuous space, resolving mutual conflicts with other tokens before collapsing into a final discrete sample. Furthermore, a rejection rule reverts uncertain representations from the continuous state back to the masked state for reprocessing, ensuring stability and preventing error propagation. ReMix thus mitigates combinatorial contradictions by enabling continuous-space refinement during discrete diffusion decoding. Extensive experiments demonstrate that ReMix, as a training-free method, achieves a $2-8 \times$ inference speedup without any quality degradation.
TRIP-Bench: A Benchmark for Long-Horizon Interactive Agents in Real-World Scenarios
Feb 02, 2026As LLM-based agents are deployed in increasingly complex real-world settings, existing benchmarks underrepresent key challenges such as enforcing global constraints, coordinating multi-tool reasoning, and adapting to evolving user behavior over long, multi-turn interactions. To bridge this gap, we introduce \textbf{TRIP-Bench}, a long-horizon benchmark grounded in realistic travel-planning scenarios. TRIP-Bench leverages real-world data, offers 18 curated tools and 40+ travel requirements, and supports automated evaluation. It includes splits of varying difficulty; the hard split emphasizes long and ambiguous interactions, style shifts, feasibility changes, and iterative version revision. Dialogues span up to 15 user turns, can involve 150+ tool calls, and may exceed 200k tokens of context. Experiments show that even advanced models achieve at most 50\% success on the easy split, with performance dropping below 10\% on hard subsets. We further propose \textbf{GTPO}, an online multi-turn reinforcement learning method with specialized reward normalization and reward differencing. Applied to Qwen2.5-32B-Instruct, GTPO improves constraint satisfaction and interaction robustness, outperforming Gemini-3-Pro in our evaluation. We expect TRIP-Bench to advance practical long-horizon interactive agents, and GTPO to provide an effective online RL recipe for robust long-horizon training.
TriSpec: Ternary Speculative Decoding via Lightweight Proxy Verification
Jan 30, 2026Inference efficiency in Large Language Models (LLMs) is fundamentally limited by their serial, autoregressive generation, especially as reasoning becomes a key capability and response sequences grow longer. Speculative decoding (SD) offers a powerful solution, providing significant speed-ups through its lightweight drafting and parallel verification mechanism. While existing work has nearly saturated improvements in draft effectiveness and efficiency, this paper advances SD from a new yet critical perspective: the verification cost. We propose TriSpec, a novel ternary SD framework that, at its core, introduces a lightweight proxy to significantly reduce computational cost by approving easily verifiable draft sequences and engaging the full target model only when encountering uncertain tokens. TriSpec can be integrated with state-of-the-art SD methods like EAGLE-3 to further reduce verification costs, achieving greater acceleration. Extensive experiments on the Qwen3 and DeepSeek-R1-Distill-Qwen/LLaMA families show that TriSpec achieves up to 35\% speedup over standard SD, with up to 50\% fewer target model invocations while maintaining comparable accuracy.
Sophia: A Persistent Agent Framework of Artificial Life
Dec 20, 2025
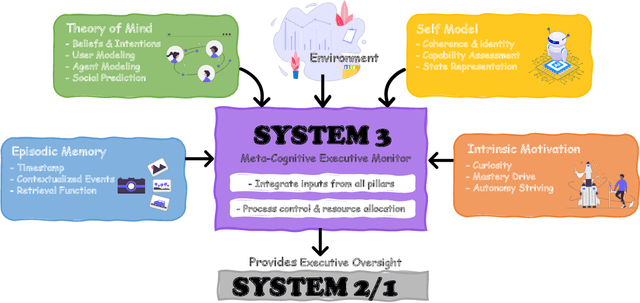
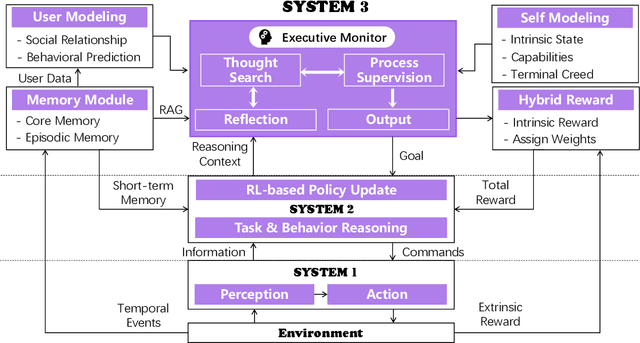
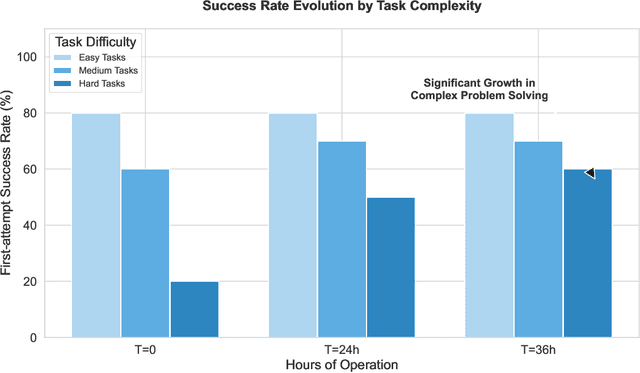
The development of LLMs has elevated AI agents from task-specific tools to long-lived, decision-making entities. Yet, most architectures remain static and reactive, tethered to manually defined, narrow scenarios. These systems excel at perception (System 1) and deliberation (System 2) but lack a persistent meta-layer to maintain identity, verify reasoning, and align short-term actions with long-term survival. We first propose a third stratum, System 3, that presides over the agent's narrative identity and long-horizon adaptation. The framework maps selected psychological constructs to concrete computational modules, thereby translating abstract notions of artificial life into implementable design requirements. The ideas coalesce in Sophia, a "Persistent Agent" wrapper that grafts a continuous self-improvement loop onto any LLM-centric System 1/2 stack. Sophia is driven by four synergistic mechanisms: process-supervised thought search, narrative memory, user and self modeling, and a hybrid reward system. Together, they transform repetitive reasoning into a self-driven, autobiographical process, enabling identity continuity and transparent behavioral explanations. Although the paper is primarily conceptual, we provide a compact engineering prototype to anchor the discussion. Quantitatively, Sophia independently initiates and executes various intrinsic tasks while achieving an 80% reduction in reasoning steps for recurring operations. Notably, meta-cognitive persistence yielded a 40% gain in success for high-complexity tasks, effectively bridging the performance gap between simple and sophisticated goals. Qualitatively, System 3 exhibited a coherent narrative identity and an innate capacity for task organization. By fusing psychological insight with a lightweight reinforcement-learning core, the persistent agent architecture advances a possible practical pathway toward artificial life.
Wide-In, Narrow-Out: Revokable Decoding for Efficient and Effective DLLMs
Jul 24, 2025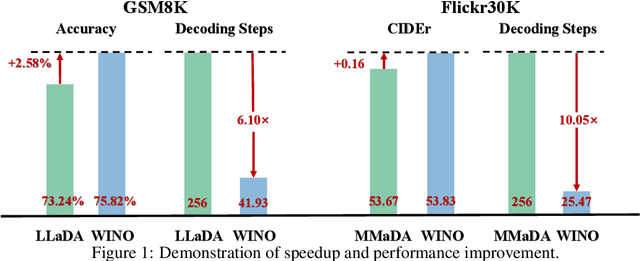
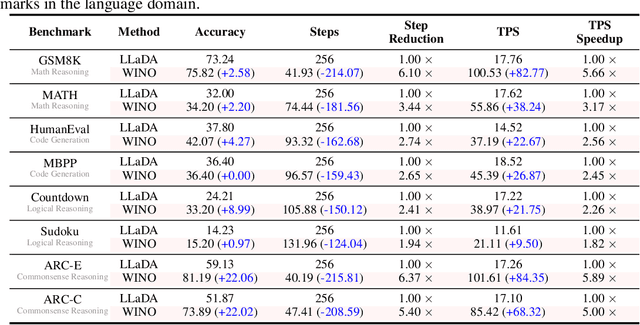
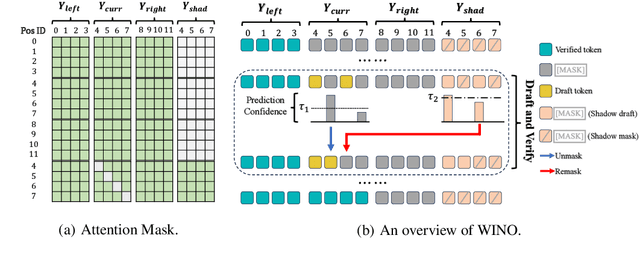
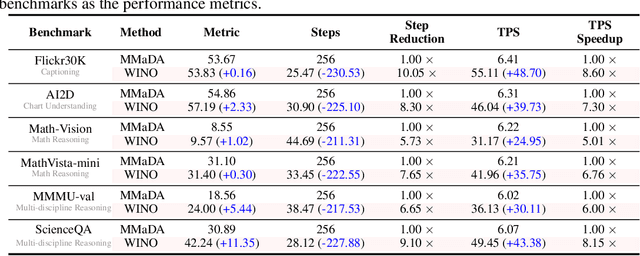
Diffusion Large Language Models (DLLMs) have emerged as a compelling alternative to Autoregressive models, designed for fast parallel generation. However, existing DLLMs are plagued by a severe quality-speed trade-off, where faster parallel decoding leads to significant performance degradation. We attribute this to the irreversibility of standard decoding in DLLMs, which is easily polarized into the wrong decoding direction along with early error context accumulation. To resolve this, we introduce Wide-In, Narrow-Out (WINO), a training-free decoding algorithm that enables revokable decoding in DLLMs. WINO employs a parallel draft-and-verify mechanism, aggressively drafting multiple tokens while simultaneously using the model's bidirectional context to verify and re-mask suspicious ones for refinement. Verified in open-source DLLMs like LLaDA and MMaDA, WINO is shown to decisively improve the quality-speed trade-off. For instance, on the GSM8K math benchmark, it accelerates inference by 6$\times$ while improving accuracy by 2.58%; on Flickr30K captioning, it achieves a 10$\times$ speedup with higher performance. More comprehensive experiments are conducted to demonstrate the superiority and provide an in-depth understanding of WINO.
Differential-informed Sample Selection Accelerates Multimodal Contrastive Learning
Jul 17, 2025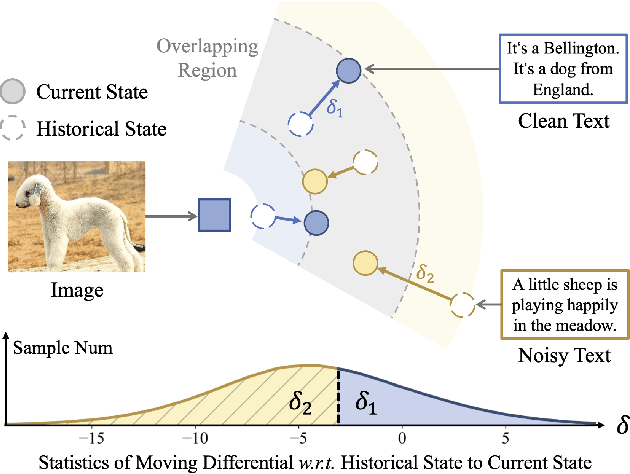
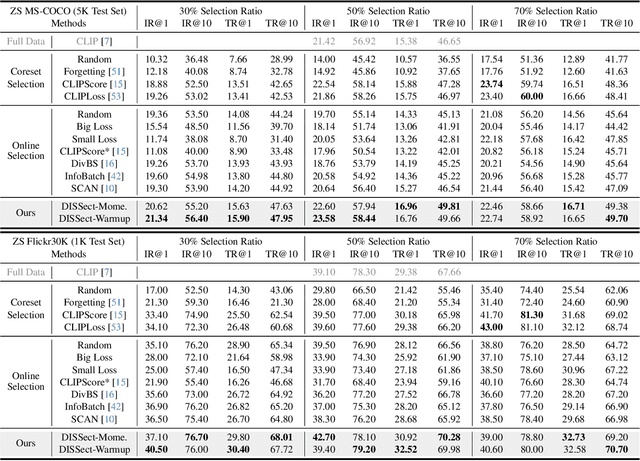
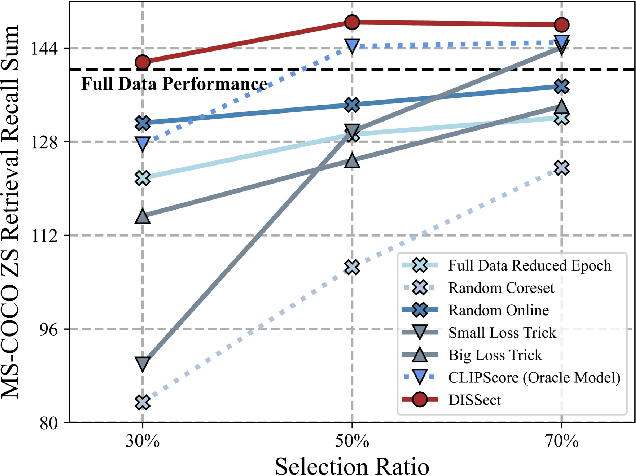
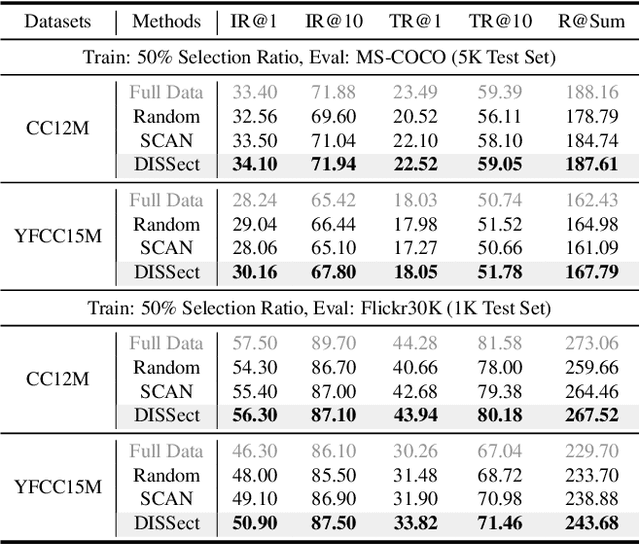
The remarkable success of contrastive-learning-based multimodal models has been greatly driven by training on ever-larger datasets with expensive compute consumption. Sample selection as an alternative efficient paradigm plays an important direction to accelerate the training process. However, recent advances on sample selection either mostly rely on an oracle model to offline select a high-quality coreset, which is limited in the cold-start scenarios, or focus on online selection based on real-time model predictions, which has not sufficiently or efficiently considered the noisy correspondence. To address this dilemma, we propose a novel Differential-Informed Sample Selection (DISSect) method, which accurately and efficiently discriminates the noisy correspondence for training acceleration. Specifically, we rethink the impact of noisy correspondence on contrastive learning and propose that the differential between the predicted correlation of the current model and that of a historical model is more informative to characterize sample quality. Based on this, we construct a robust differential-based sample selection and analyze its theoretical insights. Extensive experiments on three benchmark datasets and various downstream tasks demonstrate the consistent superiority of DISSect over current state-of-the-art methods. Source code is available at: https://github.com/MediaBrain-SJTU/DISSect.
Deep Learning Framework for Infrastructure Maintenance: Crack Detection and High-Resolution Imaging of Infrastructure Surfaces
May 06, 2025



Recently, there has been an impetus for the application of cutting-edge data collection platforms such as drones mounted with camera sensors for infrastructure asset management. However, the sensor characteristics, proximity to the structure, hard-to-reach access, and environmental conditions often limit the resolution of the datasets. A few studies used super-resolution techniques to address the problem of low-resolution images. Nevertheless, these techniques were observed to increase computational cost and false alarms of distress detection due to the consideration of all the infrastructure images i.e., positive and negative distress classes. In order to address the pre-processing of false alarm and achieve efficient super-resolution, this study developed a framework consisting of convolutional neural network (CNN) and efficient sub-pixel convolutional neural network (ESPCNN). CNN accurately classified both the classes. ESPCNN, which is the lightweight super-resolution technique, generated high-resolution infrastructure image of positive distress obtained from CNN. The ESPCNN outperformed bicubic interpolation in all the evaluation metrics for super-resolution. Based on the performance metrics, the combination of CNN and ESPCNN was observed to be effective in preprocessing the infrastructure images with negative distress, reducing the computational cost and false alarms in the next step of super-resolution. The visual inspection showed that EPSCNN is able to capture crack propagation, complex geometry of even minor cracks. The proposed framework is expected to help the highway agencies in accurately performing distress detection and assist in efficient asset management practices.