 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstablishing dermatopathology encyclopedia DermpathNet with Artificial Intelligence-Based Workflow
Jan 27, 2026Accessing high-quality, open-access dermatopathology image datasets for learning and cross-referencing is a common challenge for clinicians and dermatopathology trainees. To establish a comprehensive open-access dermatopathology dataset for educational, cross-referencing, and machine-learning purposes, we employed a hybrid workflow to curate and categorize images from the PubMed Central (PMC) repository. We used specific keywords to extract relevant images, and classified them using a novel hybrid method that combined deep learning-based image modality classification with figure caption analyses. Validation on 651 manually annotated images demonstrated the robustness of our workflow, with an F-score of 89.6\% for the deep learning approach, 61.0\% for the keyword-based retrieval method, and 90.4\% for the hybrid approach. We retrieved over 7,772 images across 166 diagnoses and released this fully annotated dataset, reviewed by board-certified dermatopathologists. Using our dataset as a challenging task, we found the current image analysis algorithm from OpenAI inadequate for analyzing dermatopathology images. In conclusion, we have developed a large, peer-reviewed, open-access dermatopathology image dataset, DermpathNet, which features a semi-automated curation workflow.
Understanding Stigmatizing Language Lexicons: A Comparative Analysis in Clinical Contexts
Sep 09, 2025Stigmatizing language results in healthcare inequities, yet there is no universally accepted or standardized lexicon defining which words, terms, or phrases constitute stigmatizing language in healthcare. We conducted a systematic search of the literature to identify existing stigmatizing language lexicons and then analyzed them comparatively to examine: 1) similarities and discrepancies between these lexicons, and 2) the distribution of positive, negative, or neutral terms based on an established sentiment dataset. Our search identified four lexicons. The analysis results revealed moderate semantic similarity among them, and that most stigmatizing terms are related to judgmental expressions by clinicians to describe perceived negative behaviors. Sentiment analysis showed a predominant proportion of negatively classified terms, though variations exist across lexicons. Our findings underscore the need for a standardized lexicon and highlight challenges in defining stigmatizing language in clinical texts.
CXR-LT 2024: A MICCAI challenge on long-tailed, multi-label, and zero-shot disease classification from chest X-ray
Jun 09, 2025The CXR-LT series is a community-driven initiative designed to enhance lung disease classification using chest X-rays (CXR). It tackles challenges in open long-tailed lung disease classification and enhances the measurability of state-of-the-art techniques. The first event, CXR-LT 2023, aimed to achieve these goals by providing high-quality benchmark CXR data for model development and conducting comprehensive evaluations to identify ongoing issues impacting lung disease classification performance. Building on the success of CXR-LT 2023, the CXR-LT 2024 expands the dataset to 377,110 chest X-rays (CXRs) and 45 disease labels, including 19 new rare disease findings. It also introduces a new focus on zero-shot learning to address limitations identified in the previous event. Specifically, CXR-LT 2024 features three tasks: (i) long-tailed classification on a large, noisy test set, (ii) long-tailed classification on a manually annotated "gold standard" subset, and (iii) zero-shot generalization to five previously unseen disease findings. This paper provides an overview of CXR-LT 2024, detailing the data curation process and consolidating state-of-the-art solutions, including the use of multimodal models for rare disease detection, advanced generative approaches to handle noisy labels, and zero-shot learning strategies for unseen diseases. Additionally, the expanded dataset enhances disease coverage to better represent real-world clinical settings, offering a valuable resource for future research. By synthesizing the insights and innovations of participating teams, we aim to advance the development of clinically realistic and generalizable diagnostic models for chest radiography.
Generative Large Language Models Trained for Detecting Errors in Radiology Reports
Apr 06, 2025In this retrospective study, a dataset was constructed with two parts. The first part included 1,656 synthetic chest radiology reports generated by GPT-4 using specified prompts, with 828 being error-free synthetic reports and 828 containing errors. The second part included 614 reports: 307 error-free reports between 2011 and 2016 from the MIMIC-CXR database and 307 corresponding synthetic reports with errors generated by GPT-4 on the basis of these MIMIC-CXR reports and specified prompts. All errors were categorized into four types: negation, left/right, interval change, and transcription errors. Then, several models, including Llama-3, GPT-4, and BiomedBERT, were refined using zero-shot prompting, few-shot prompting, or fine-tuning strategies. Finally, the performance of these models was evaluated using the F1 score, 95\% confidence interval (CI) and paired-sample t-tests on our constructed dataset, with the prediction results further assessed by radiologists. Using zero-shot prompting, the fine-tuned Llama-3-70B-Instruct model achieved the best performance with the following F1 scores: 0.769 for negation errors, 0.772 for left/right errors, 0.750 for interval change errors, 0.828 for transcription errors, and 0.780 overall. In the real-world evaluation phase, two radiologists reviewed 200 randomly selected reports output by the model. Of these, 99 were confirmed to contain errors detected by the models by both radiologists, and 163 were confirmed to contain model-detected errors by at least one radiologist. Generative LLMs, fine-tuned on synthetic and MIMIC-CXR radiology reports, greatly enhanced error detection in radiology reports.
Deciphering genomic codes using advanced NLP techniques: a scoping review
Nov 25, 2024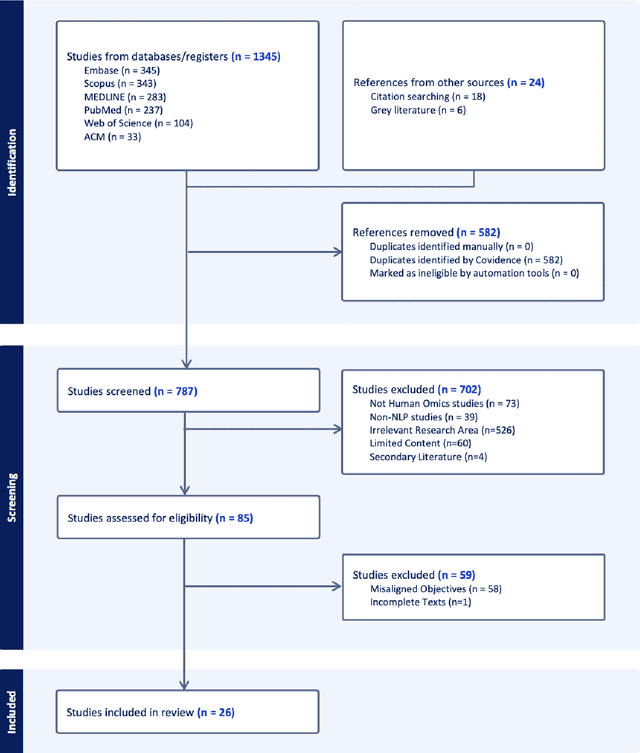
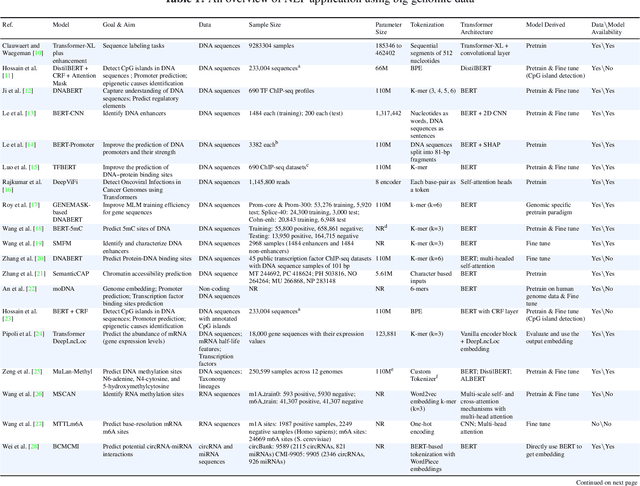
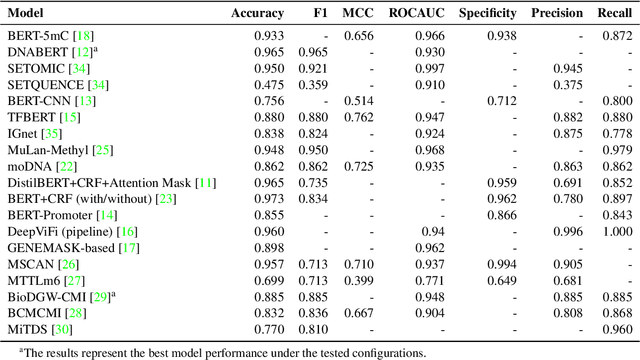
Objectives: The vast and complex nature of human genomic sequencing data presents challenges for effective analysis. This review aims to investigate the application of Natural Language Processing (NLP) techniques, particularly Large Language Models (LLMs) and transformer architectures, in deciphering genomic codes, focusing on tokenization, transformer models, and regulatory annotation prediction. The goal of this review is to assess data and model accessibility in the most recent literature, gaining a better understanding of the existing capabilities and constraints of these tools in processing genomic sequencing data. Methods: Following Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) guidelines, our scoping review was conducted across PubMed, Medline, Scopus, Web of Science, Embase, and ACM Digital Library. Studies were included if they focused on NLP methodologies applied to genomic sequencing data analysis, without restrictions on publication date or article type. Results: A total of 26 studies published between 2021 and April 2024 were selected for review. The review highlights that tokenization and transformer models enhance the processing and understanding of genomic data, with applications in predicting regulatory annotations like transcription-factor binding sites and chromatin accessibility. Discussion: The application of NLP and LLMs to genomic sequencing data interpretation is a promising field that can help streamline the processing of large-scale genomic data while also providing a better understanding of its complex structures. It has the potential to drive advancements in personalized medicine by offering more efficient and scalable solutions for genomic analysis. Further research is also needed to discuss and overcome current limitations, enhancing model transparency and applicability.
Enhancing disease detection in radiology reports through fine-tuning lightweight LLM on weak labels
Sep 25, 2024Despite significant progress in applying large language models (LLMs) to the medical domain, several limitations still prevent them from practical applications. Among these are the constraints on model size and the lack of cohort-specific labeled datasets. In this work, we investigated the potential of improving a lightweight LLM, such as Llama 3.1-8B, through fine-tuning with datasets using synthetic labels. Two tasks are jointly trained by combining their respective instruction datasets. When the quality of the task-specific synthetic labels is relatively high (e.g., generated by GPT4- o), Llama 3.1-8B achieves satisfactory performance on the open-ended disease detection task, with a micro F1 score of 0.91. Conversely, when the quality of the task-relevant synthetic labels is relatively low (e.g., from the MIMIC-CXR dataset), fine-tuned Llama 3.1-8B is able to surpass its noisy teacher labels (micro F1 score of 0.67 v.s. 0.63) when calibrated against curated labels, indicating the strong inherent underlying capability of the model. These findings demonstrate the potential of fine-tuning LLMs with synthetic labels, offering a promising direction for future research on LLM specialization in the medical domain.
Closing the gap between open-source and commercial large language models for medical evidence summarization
Jul 25, 2024



Large language models (LLMs) hold great promise in summarizing medical evidence. Most recent studies focus on the application of proprietary LLMs. Using proprietary LLMs introduces multiple risk factors, including a lack of transparency and vendor dependency. While open-source LLMs allow better transparency and customization, their performance falls short compared to proprietary ones. In this study, we investigated to what extent fine-tuning open-source LLMs can further improve their performance in summarizing medical evidence. Utilizing a benchmark dataset, MedReview, consisting of 8,161 pairs of systematic reviews and summaries, we fine-tuned three broadly-used, open-sourced LLMs, namely PRIMERA, LongT5, and Llama-2. Overall, the fine-tuned LLMs obtained an increase of 9.89 in ROUGE-L (95% confidence interval: 8.94-10.81), 13.21 in METEOR score (95% confidence interval: 12.05-14.37), and 15.82 in CHRF score (95% confidence interval: 13.89-16.44). The performance of fine-tuned LongT5 is close to GPT-3.5 with zero-shot settings. Furthermore, smaller fine-tuned models sometimes even demonstrated superior performance compared to larger zero-shot models. The above trends of improvement were also manifested in both human and GPT4-simulated evaluations. Our results can be applied to guide model selection for tasks demanding particular domain knowledge, such as medical evidence summarization.
Evaluating GPT-4 with Vision on Detection of Radiological Findings on Chest Radiographs
Apr 03, 2024The study examines the application of GPT-4V, a multi-modal large language model equipped with visual recognition, in detecting radiological findings from a set of 100 chest radiographs and suggests that GPT-4V is currently not ready for real-world diagnostic usage in interpreting chest radiographs.
Uncovering Misattributed Suicide Causes through Annotation Inconsistency Detection in Death Investigation Notes
Mar 29, 2024



Data accuracy is essential for scientific research and policy development. The National Violent Death Reporting System (NVDRS) data is widely used for discovering the patterns and causes of death. Recent studies suggested the annotation inconsistencies within the NVDRS and the potential impact on erroneous suicide-cause attributions. We present an empirical Natural Language Processing (NLP) approach to detect annotation inconsistencies and adopt a cross-validation-like paradigm to identify problematic instances. We analyzed 267,804 suicide death incidents between 2003 and 2020 from the NVDRS. Our results showed that incorporating the target state's data into training the suicide-crisis classifier brought an increase of 5.4% to the F-1 score on the target state's test set and a decrease of 1.1% on other states' test set. To conclude, we demonstrated the annotation inconsistencies in NVDRS's death investigation notes, identified problematic instances, evaluated the effectiveness of correcting problematic instances, and eventually proposed an NLP improvement solution.
Hidden Flaws Behind Expert-Level Accuracy of GPT-4 Vision in Medicine
Jan 24, 2024Recent studies indicate that Generative Pre-trained Transformer 4 with Vision (GPT-4V) outperforms human physicians in medical challenge tasks. However, these evaluations primarily focused on the accuracy of multi-choice questions alone. Our study extends the current scope by conducting a comprehensive analysis of GPT-4V's rationales of image comprehension, recall of medical knowledge, and step-by-step multimodal reasoning when solving New England Journal of Medicine (NEJM) Image Challenges - an imaging quiz designed to test the knowledge and diagnostic capabilities of medical professionals. Evaluation results confirmed that GPT-4V outperforms human physicians regarding multi-choice accuracy (88.0% vs. 77.0%, p=0.034). GPT-4V also performs well in cases where physicians incorrectly answer, with over 80% accuracy. However, we discovered that GPT-4V frequently presents flawed rationales in cases where it makes the correct final choices (27.3%), most prominent in image comprehension (21.6%). Regardless of GPT-4V's high accuracy in multi-choice questions, our findings emphasize the necessity for further in-depth evaluations of its rationales before integrating such models into clinical workflows.