 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Domain-Adapted Pipeline for Structured Information Extraction from Police Incident Announcements on Social Media
Dec 18, 2025Structured information extraction from police incident announcements is crucial for timely and accurate data processing, yet presents considerable challenges due to the variability and informal nature of textual sources such as social media posts. To address these challenges, we developed a domain-adapted extraction pipeline that leverages targeted prompt engineering with parameter-efficient fine-tuning of the Qwen2.5-7B model using Low-Rank Adaptation (LoRA). This approach enables the model to handle noisy, heterogeneous text while reliably extracting 15 key fields, including location, event characteristics, and impact assessment, from a high-quality, manually annotated dataset of 4,933 instances derived from 27,822 police briefing posts on Chinese Weibo (2019-2020). Experimental results demonstrated that LoRA-based fine-tuning significantly improved performance over both the base and instruction-tuned models, achieving an accuracy exceeding 98.36% for mortality detection and Exact Match Rates of 95.31% for fatality counts and 95.54% for province-level location extraction. The proposed pipeline thus provides a validated and efficient solution for multi-task structured information extraction in specialized domains, offering a practical framework for transforming unstructured text into reliable structured data in social science research.
Uncovering Misattributed Suicide Causes through Annotation Inconsistency Detection in Death Investigation Notes
Mar 29, 2024



Data accuracy is essential for scientific research and policy development. The National Violent Death Reporting System (NVDRS) data is widely used for discovering the patterns and causes of death. Recent studies suggested the annotation inconsistencies within the NVDRS and the potential impact on erroneous suicide-cause attributions. We present an empirical Natural Language Processing (NLP) approach to detect annotation inconsistencies and adopt a cross-validation-like paradigm to identify problematic instances. We analyzed 267,804 suicide death incidents between 2003 and 2020 from the NVDRS. Our results showed that incorporating the target state's data into training the suicide-crisis classifier brought an increase of 5.4% to the F-1 score on the target state's test set and a decrease of 1.1% on other states' test set. To conclude, we demonstrated the annotation inconsistencies in NVDRS's death investigation notes, identified problematic instances, evaluated the effectiveness of correcting problematic instances, and eventually proposed an NLP improvement solution.
Classifying Crime Types using Judgment Documents from Social Media
Jun 29, 2023
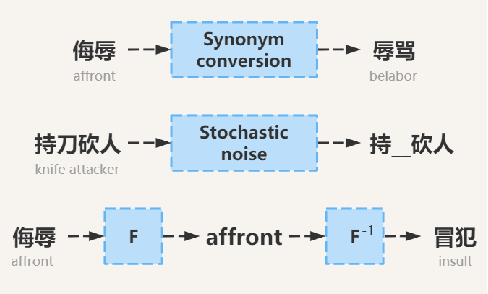
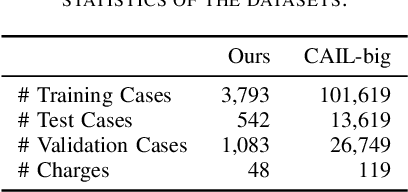
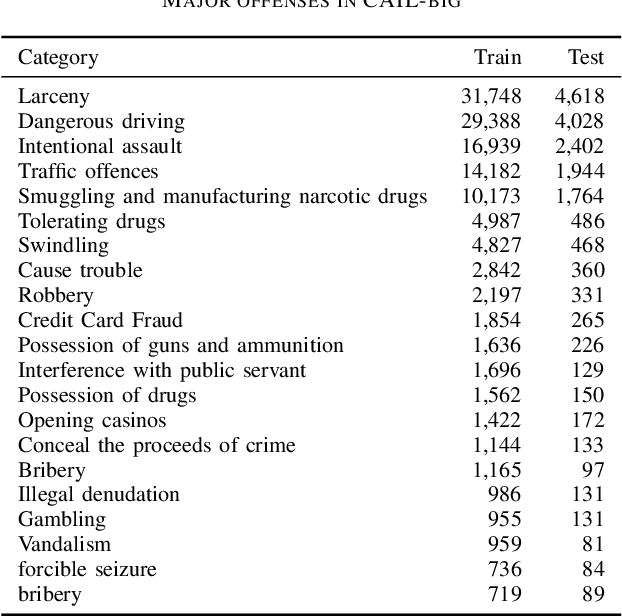
The task of determining crime types based on criminal behavior facts has become a very important and meaningful task in social science. But the problem facing the field now is that the data samples themselves are unevenly distributed, due to the nature of the crime itself. At the same time, data sets in the judicial field are less publicly available, and it is not practical to produce large data sets for direct training. This article proposes a new training model to solve this problem through NLP processing methods. We first propose a Crime Fact Data Preprocessing Module (CFDPM), which can balance the defects of uneven data set distribution by generating new samples. Then we use a large open source dataset (CAIL-big) as our pretraining dataset and a small dataset collected by ourselves for Fine-tuning, giving it good generalization ability to unfamiliar small datasets. At the same time, we use the improved Bert model with dynamic masking to improve the model. Experiments show that the proposed method achieves state-of-the-art results on the present dataset. At the same time, the effectiveness of module CFDPM is proved by experiments. This article provides a valuable methodology contribution for classifying social science texts such as criminal behaviors. Extensive experiments on public benchmarks show that the proposed method achieves new state-of-the-art results.