 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSECURE: Stable Early Collision Understanding via Robust Embeddings in Autonomous Driving
Apr 01, 2026While deep learning has significantly advanced accident anticipation, the robustness of these safety-critical systems against real-world perturbations remains a major challenge. We reveal that state-of-the-art models like CRASH, despite their high performance, exhibit significant instability in predictions and latent representations when faced with minor input perturbations, posing serious reliability risks. To address this, we introduce SECURE - Stable Early Collision Understanding Robust Embeddings, a framework that formally defines and enforces model robustness. SECURE is founded on four key attributes: consistency and stability in both prediction space and latent feature space. We propose a principled training methodology that fine-tunes a baseline model using a multi-objective loss, which minimizes divergence from a reference model and penalizes sensitivity to adversarial perturbations. Experiments on DAD and CCD datasets demonstrate that our approach not only significantly enhances robustness against various perturbations but also improves performance on clean data, achieving new state-of-the-art results.
ACE: Attribution-Controlled Knowledge Editing for Multi-hop Factual Recall
Oct 09, 2025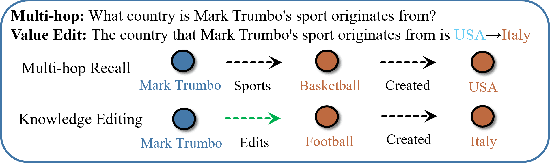

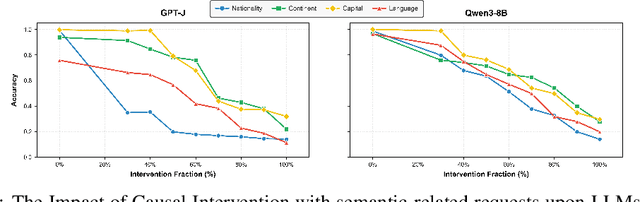
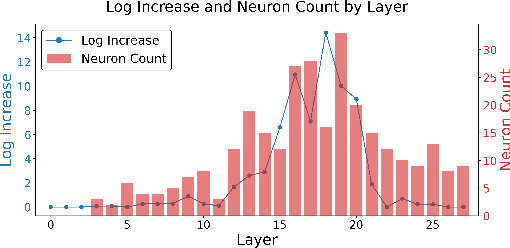
Large Language Models (LLMs) require efficient knowledge editing (KE) to update factual information, yet existing methods exhibit significant performance decay in multi-hop factual recall. This failure is particularly acute when edits involve intermediate implicit subjects within reasoning chains. Through causal analysis, we reveal that this limitation stems from an oversight of how chained knowledge is dynamically represented and utilized at the neuron level. We discover that during multi hop reasoning, implicit subjects function as query neurons, which sequentially activate corresponding value neurons across transformer layers to accumulate information toward the final answer, a dynamic prior KE work has overlooked. Guided by this insight, we propose ACE: Attribution-Controlled Knowledge Editing for Multi-hop Factual Recall, a framework that leverages neuron-level attribution to identify and edit these critical query-value (Q-V) pathways. ACE provides a mechanistically grounded solution for multi-hop KE, empirically outperforming state-of-the-art methods by 9.44% on GPT-J and 37.46% on Qwen3-8B. Our analysis further reveals more fine-grained activation patterns in Qwen3 and demonstrates that the semantic interpretability of value neurons is orchestrated by query-driven accumulation. These findings establish a new pathway for advancing KE capabilities based on the principled understanding of internal reasoning mechanisms.
Mimicking the Physicist's Eye:A VLM-centric Approach for Physics Formula Discovery
Aug 24, 2025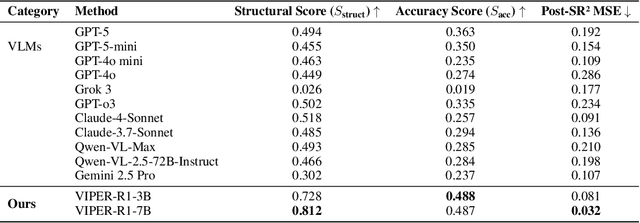
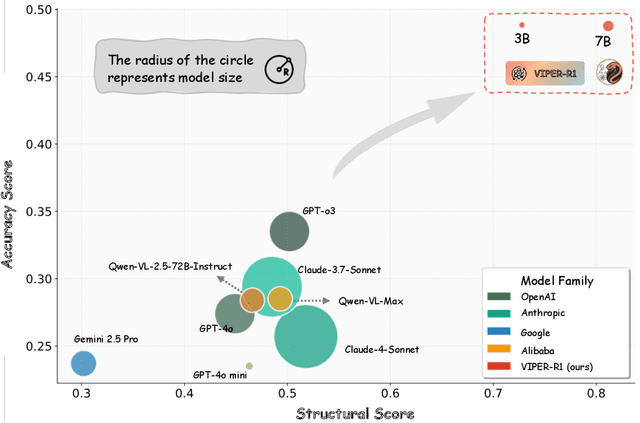
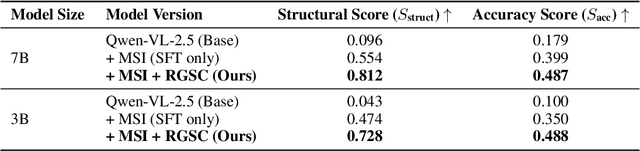
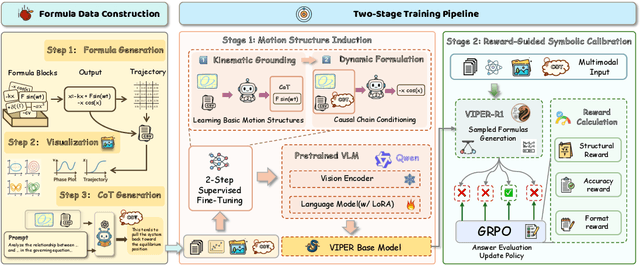
Automated discovery of physical laws from observational data in the real world is a grand challenge in AI. Current methods, relying on symbolic regression or LLMs, are limited to uni-modal data and overlook the rich, visual phenomenological representations of motion that are indispensable to physicists. This "sensory deprivation" severely weakens their ability to interpret the inherent spatio-temporal patterns within dynamic phenomena. To address this gap, we propose VIPER-R1, a multimodal model that performs Visual Induction for Physics-based Equation Reasoning to discover fundamental symbolic formulas. It integrates visual perception, trajectory data, and symbolic reasoning to emulate the scientific discovery process. The model is trained via a curriculum of Motion Structure Induction (MSI), using supervised fine-tuning to interpret kinematic phase portraits and to construct hypotheses guided by a Causal Chain of Thought (C-CoT), followed by Reward-Guided Symbolic Calibration (RGSC) to refine the formula structure with reinforcement learning. During inference, the trained VIPER-R1 acts as an agent: it first posits a high-confidence symbolic ansatz, then proactively invokes an external symbolic regression tool to perform Symbolic Residual Realignment (SR^2). This final step, analogous to a physicist's perturbation analysis, reconciles the theoretical model with empirical data. To support this research, we introduce PhysSymbol, a new 5,000-instance multimodal corpus. Experiments show that VIPER-R1 consistently outperforms state-of-the-art VLM baselines in accuracy and interpretability, enabling more precise discovery of physical laws. Project page: https://jiaaqiliu.github.io/VIPER-R1/
Da Yu: Towards USV-Based Image Captioning for Waterway Surveillance and Scene Understanding
Jun 24, 2025Automated waterway environment perception is crucial for enabling unmanned surface vessels (USVs) to understand their surroundings and make informed decisions. Most existing waterway perception models primarily focus on instance-level object perception paradigms (e.g., detection, segmentation). However, due to the complexity of waterway environments, current perception datasets and models fail to achieve global semantic understanding of waterways, limiting large-scale monitoring and structured log generation. With the advancement of vision-language models (VLMs), we leverage image captioning to introduce WaterCaption, the first captioning dataset specifically designed for waterway environments. WaterCaption focuses on fine-grained, multi-region long-text descriptions, providing a new research direction for visual geo-understanding and spatial scene cognition. Exactly, it includes 20.2k image-text pair data with 1.8 million vocabulary size. Additionally, we propose Da Yu, an edge-deployable multi-modal large language model for USVs, where we propose a novel vision-to-language projector called Nano Transformer Adaptor (NTA). NTA effectively balances computational efficiency with the capacity for both global and fine-grained local modeling of visual features, thereby significantly enhancing the model's ability to generate long-form textual outputs. Da Yu achieves an optimal balance between performance and efficiency, surpassing state-of-the-art models on WaterCaption and several other captioning benchmarks.
Stable Vision Concept Transformers for Medical Diagnosis
Jun 05, 2025Transparency is a paramount concern in the medical field, prompting researchers to delve into the realm of explainable AI (XAI). Among these XAI methods, Concept Bottleneck Models (CBMs) aim to restrict the model's latent space to human-understandable high-level concepts by generating a conceptual layer for extracting conceptual features, which has drawn much attention recently. However, existing methods rely solely on concept features to determine the model's predictions, which overlook the intrinsic feature embeddings within medical images. To address this utility gap between the original models and concept-based models, we propose Vision Concept Transformer (VCT). Furthermore, despite their benefits, CBMs have been found to negatively impact model performance and fail to provide stable explanations when faced with input perturbations, which limits their application in the medical field. To address this faithfulness issue, this paper further proposes the Stable Vision Concept Transformer (SVCT) based on VCT, which leverages the vision transformer (ViT) as its backbone and incorporates a conceptual layer. SVCT employs conceptual features to enhance decision-making capabilities by fusing them with image features and ensures model faithfulness through the integration of Denoised Diffusion Smoothing. Comprehensive experiments on four medical datasets demonstrate that our VCT and SVCT maintain accuracy while remaining interpretable compared to baselines. Furthermore, even when subjected to perturbations, our SVCT model consistently provides faithful explanations, thus meeting the needs of the medical field.
IMTS is Worth Time $\times$ Channel Patches: Visual Masked Autoencoders for Irregular Multivariate Time Series Prediction
May 28, 2025Irregular Multivariate Time Series (IMTS) forecasting is challenging due to the unaligned nature of multi-channel signals and the prevalence of extensive missing data. Existing methods struggle to capture reliable temporal patterns from such data due to significant missing values. While pre-trained foundation models show potential for addressing these challenges, they are typically designed for Regularly Sampled Time Series (RTS). Motivated by the visual Mask AutoEncoder's (MAE) powerful capability for modeling sparse multi-channel information and its success in RTS forecasting, we propose VIMTS, a framework adapting Visual MAE for IMTS forecasting. To mitigate the effect of missing values, VIMTS first processes IMTS along the timeline into feature patches at equal intervals. These patches are then complemented using learned cross-channel dependencies. Then it leverages visual MAE's capability in handling sparse multichannel data for patch reconstruction, followed by a coarse-to-fine technique to generate precise predictions from focused contexts. In addition, we integrate self-supervised learning for improved IMTS modeling by adapting the visual MAE to IMTS data. Extensive experiments demonstrate VIMTS's superior performance and few-shot capability, advancing the application of visual foundation models in more general time series tasks. Our code is available at https://github.com/WHU-HZY/VIMTS.
Beyond Patterns: Harnessing Causal Logic for Autonomous Driving Trajectory Prediction
May 11, 2025Accurate trajectory prediction has long been a major challenge for autonomous driving (AD). Traditional data-driven models predominantly rely on statistical correlations, often overlooking the causal relationships that govern traffic behavior. In this paper, we introduce a novel trajectory prediction framework that leverages causal inference to enhance predictive robustness, generalization, and accuracy. By decomposing the environment into spatial and temporal components, our approach identifies and mitigates spurious correlations, uncovering genuine causal relationships. We also employ a progressive fusion strategy to integrate multimodal information, simulating human-like reasoning processes and enabling real-time inference. Evaluations on five real-world datasets--ApolloScape, nuScenes, NGSIM, HighD, and MoCAD--demonstrate our model's superiority over existing state-of-the-art (SOTA) methods, with improvements in key metrics such as RMSE and FDE. Our findings highlight the potential of causal reasoning to transform trajectory prediction, paving the way for robust AD systems.
Towards Reliable Time Series Forecasting under Future Uncertainty: Ambiguity and Novelty Rejection Mechanisms
Mar 25, 2025In real-world time series forecasting, uncertainty and lack of reliable evaluation pose significant challenges. Notably, forecasting errors often arise from underfitting in-distribution data and failing to handle out-of-distribution inputs. To enhance model reliability, we introduce a dual rejection mechanism combining ambiguity and novelty rejection. Ambiguity rejection, using prediction error variance, allows the model to abstain under low confidence, assessed through historical error variance analysis without future ground truth. Novelty rejection, employing Variational Autoencoders and Mahalanobis distance, detects deviations from training data. This dual approach improves forecasting reliability in dynamic environments by reducing errors and adapting to data changes, advancing reliability in complex scenarios.
Adaptive H&E-IHC information fusion staining framework based on feature extra
Feb 27, 2025Immunohistochemistry (IHC) staining plays a significant role in the evaluation of diseases such as breast cancer. The H&E-to-IHC transformation based on generative models provides a simple and cost-effective method for obtaining IHC images. Although previous models can perform digital coloring well, they still suffer from (i) coloring only through the pixel features that are not prominent in HE, which is easy to cause information loss in the coloring process; (ii) The lack of pixel-perfect H&E-IHC groundtruth pairs poses a challenge to the classical L1 loss.To address the above challenges, we propose an adaptive information enhanced coloring framework based on feature extractors. We first propose the VMFE module to effectively extract the color information features using multi-scale feature extraction and wavelet transform convolution, while combining the shared decoder for feature fusion. The high-performance dual feature extractor of H&E-IHC is trained by contrastive learning, which can effectively perform feature alignment of HE-IHC in high latitude space. At the same time, the trained feature encoder is used to enhance the features and adaptively adjust the loss in the HE section staining process to solve the problems related to unclear and asymmetric information. We have tested on different datasets and achieved excellent performance.Our code is available at https://github.com/babyinsunshine/CEFF
RMDM: Radio Map Diffusion Model with Physics Informed
Jan 31, 2025



With the rapid development of wireless communication technology, the efficient utilization of spectrum resources, optimization of communication quality, and intelligent communication have become critical. Radio map reconstruction is essential for enabling advanced applications, yet challenges such as complex signal propagation and sparse data hinder accurate reconstruction. To address these issues, we propose the **Radio Map Diffusion Model (RMDM)**, a physics-informed framework that integrates **Physics-Informed Neural Networks (PINNs)** to incorporate constraints like the **Helmholtz equation**. RMDM employs a dual U-Net architecture: the first ensures physical consistency by minimizing PDE residuals, boundary conditions, and source constraints, while the second refines predictions via diffusion-based denoising. By leveraging physical laws, RMDM significantly enhances accuracy, robustness, and generalization. Experiments demonstrate that RMDM outperforms state-of-the-art methods, achieving **NMSE of 0.0031** and **RMSE of 0.0125** under the Static RM (SRM) setting, and **NMSE of 0.0047** and **RMSE of 0.0146** under the Dynamic RM (DRM) setting. These results establish a novel paradigm for integrating physics-informed and data-driven approaches in radio map reconstruction, particularly under sparse data conditions.