 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWavelet-based Multi-View Fusion of 4D Radar Tensor and Camera for Robust 3D Object Detection
Dec 28, 20254D millimeter-wave (mmWave) radar has been widely adopted in autonomous driving and robot perception due to its low cost and all-weather robustness. However, its inherent sparsity and limited semantic richness significantly constrain perception capability. Recently, fusing camera data with 4D radar has emerged as a promising cost effective solution, by exploiting the complementary strengths of the two modalities. Nevertheless, point-cloud-based radar often suffer from information loss introduced by multi-stage signal processing, while directly utilizing raw 4D radar data incurs prohibitive computational costs. To address these challenges, we propose WRCFormer, a novel 3D object detection framework that fuses raw radar cubes with camera inputs via multi-view representations of the decoupled radar cube. Specifically, we design a Wavelet Attention Module as the basic module of wavelet-based Feature Pyramid Network (FPN) to enhance the representation of sparse radar signals and image data. We further introduce a two-stage query-based, modality-agnostic fusion mechanism termed Geometry-guided Progressive Fusion to efficiently integrate multi-view features from both modalities. Extensive experiments demonstrate that WRCFormer achieves state-of-the-art performance on the K-Radar benchmarks, surpassing the best model by approximately 2.4% in all scenarios and 1.6% in the sleet scenario, highlighting its robustness under adverse weather conditions.
Guided Path Sampling: Steering Diffusion Models Back on Track with Principled Path Guidance
Dec 28, 2025Iterative refinement methods based on a denoising-inversion cycle are powerful tools for enhancing the quality and control of diffusion models. However, their effectiveness is critically limited when combined with standard Classifier-Free Guidance (CFG). We identify a fundamental limitation: CFG's extrapolative nature systematically pushes the sampling path off the data manifold, causing the approximation error to diverge and undermining the refinement process. To address this, we propose Guided Path Sampling (GPS), a new paradigm for iterative refinement. GPS replaces unstable extrapolation with a principled, manifold-constrained interpolation, ensuring the sampling path remains on the data manifold. We theoretically prove that this correction transforms the error series from unbounded amplification to strictly bounded, guaranteeing stability. Furthermore, we devise an optimal scheduling strategy that dynamically adjusts guidance strength, aligning semantic injection with the model's natural coarse-to-fine generation process. Extensive experiments on modern backbones like SDXL and Hunyuan-DiT show that GPS outperforms existing methods in both perceptual quality and complex prompt adherence. For instance, GPS achieves a superior ImageReward of 0.79 and HPS v2 of 0.2995 on SDXL, while improving overall semantic alignment accuracy on GenEval to 57.45%. Our work establishes that path stability is a prerequisite for effective iterative refinement, and GPS provides a robust framework to achieve it.
MMDrive: Interactive Scene Understanding Beyond Vision with Multi-representational Fusion
Dec 16, 2025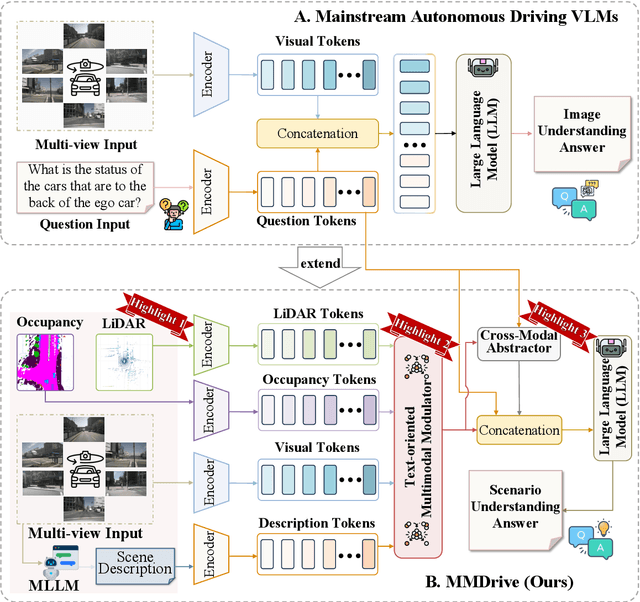
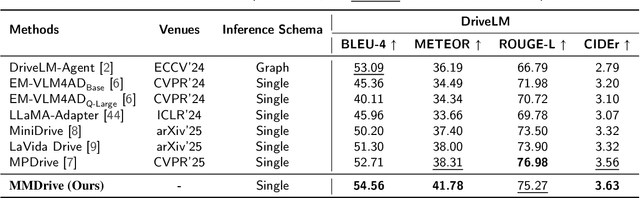


Vision-language models enable the understanding and reasoning of complex traffic scenarios through multi-source information fusion, establishing it as a core technology for autonomous driving. However, existing vision-language models are constrained by the image understanding paradigm in 2D plane, which restricts their capability to perceive 3D spatial information and perform deep semantic fusion, resulting in suboptimal performance in complex autonomous driving environments. This study proposes MMDrive, an multimodal vision-language model framework that extends traditional image understanding to a generalized 3D scene understanding framework. MMDrive incorporates three complementary modalities, including occupancy maps, LiDAR point clouds, and textual scene descriptions. To this end, it introduces two novel components for adaptive cross-modal fusion and key information extraction. Specifically, the Text-oriented Multimodal Modulator dynamically weights the contributions of each modality based on the semantic cues in the question, guiding context-aware feature integration. The Cross-Modal Abstractor employs learnable abstract tokens to generate compact, cross-modal summaries that highlight key regions and essential semantics. Comprehensive evaluations on the DriveLM and NuScenes-QA benchmarks demonstrate that MMDrive achieves significant performance gains over existing vision-language models for autonomous driving, with a BLEU-4 score of 54.56 and METEOR of 41.78 on DriveLM, and an accuracy score of 62.7% on NuScenes-QA. MMDrive effectively breaks the traditional image-only understanding barrier, enabling robust multimodal reasoning in complex driving environments and providing a new foundation for interpretable autonomous driving scene understanding.
Da Yu: Towards USV-Based Image Captioning for Waterway Surveillance and Scene Understanding
Jun 24, 2025Automated waterway environment perception is crucial for enabling unmanned surface vessels (USVs) to understand their surroundings and make informed decisions. Most existing waterway perception models primarily focus on instance-level object perception paradigms (e.g., detection, segmentation). However, due to the complexity of waterway environments, current perception datasets and models fail to achieve global semantic understanding of waterways, limiting large-scale monitoring and structured log generation. With the advancement of vision-language models (VLMs), we leverage image captioning to introduce WaterCaption, the first captioning dataset specifically designed for waterway environments. WaterCaption focuses on fine-grained, multi-region long-text descriptions, providing a new research direction for visual geo-understanding and spatial scene cognition. Exactly, it includes 20.2k image-text pair data with 1.8 million vocabulary size. Additionally, we propose Da Yu, an edge-deployable multi-modal large language model for USVs, where we propose a novel vision-to-language projector called Nano Transformer Adaptor (NTA). NTA effectively balances computational efficiency with the capacity for both global and fine-grained local modeling of visual features, thereby significantly enhancing the model's ability to generate long-form textual outputs. Da Yu achieves an optimal balance between performance and efficiency, surpassing state-of-the-art models on WaterCaption and several other captioning benchmarks.
Cognitive Disentanglement for Referring Multi-Object Tracking
Mar 14, 2025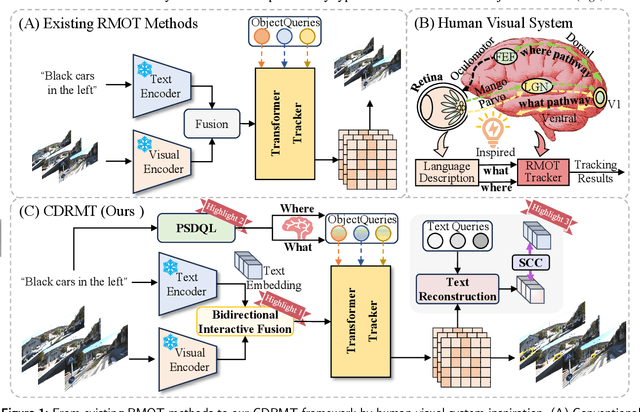
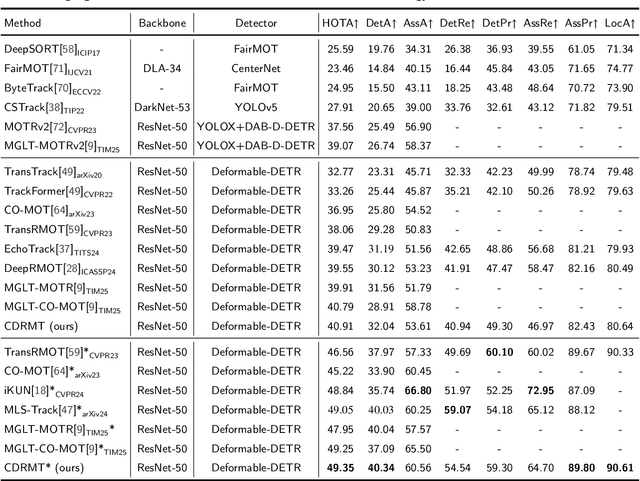
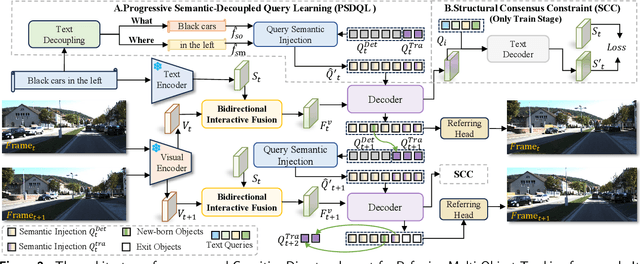
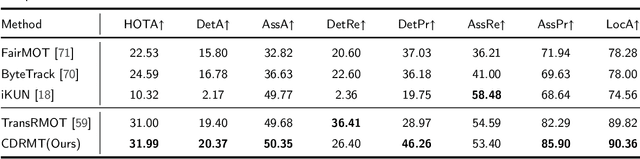
As a significant application of multi-source information fusion in intelligent transportation perception systems, Referring Multi-Object Tracking (RMOT) involves localizing and tracking specific objects in video sequences based on language references. However, existing RMOT approaches often treat language descriptions as holistic embeddings and struggle to effectively integrate the rich semantic information contained in language expressions with visual features. This limitation is especially apparent in complex scenes requiring comprehensive understanding of both static object attributes and spatial motion information. In this paper, we propose a Cognitive Disentanglement for Referring Multi-Object Tracking (CDRMT) framework that addresses these challenges. It adapts the "what" and "where" pathways from human visual processing system to RMOT tasks. Specifically, our framework comprises three collaborative components: (1)The Bidirectional Interactive Fusion module first establishes cross-modal connections while preserving modality-specific characteristics; (2) Building upon this foundation, the Progressive Semantic-Decoupled Query Learning mechanism hierarchically injects complementary information into object queries, progressively refining object understanding from coarse to fine-grained semantic levels; (3) Finally, the Structural Consensus Constraint enforces bidirectional semantic consistency between visual features and language descriptions, ensuring that tracked objects faithfully reflect the referring expression. Extensive experiments on different benchmark datasets demonstrate that CDRMT achieves substantial improvements over state-of-the-art methods, with average gains of 6.0% in HOTA score on Refer-KITTI and 3.2% on Refer-KITTI-V2. Our approach advances the state-of-the-art in RMOT while simultaneously providing new insights into multi-source information fusion.