 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCognitive Disentanglement for Referring Multi-Object Tracking
Mar 14, 2025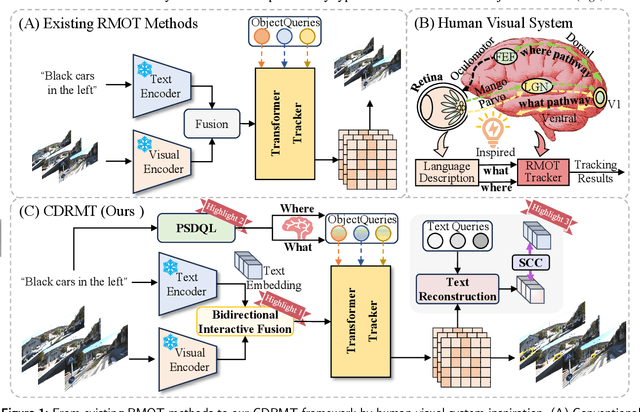
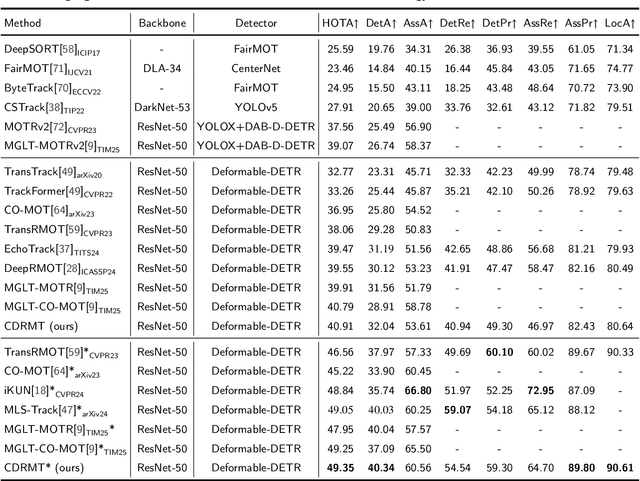
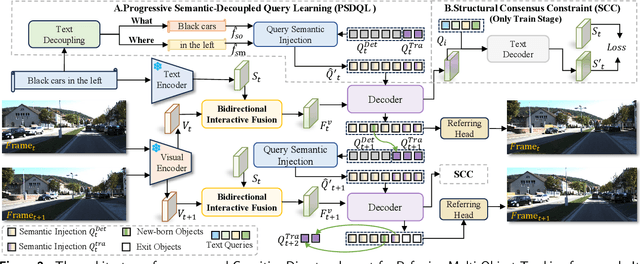
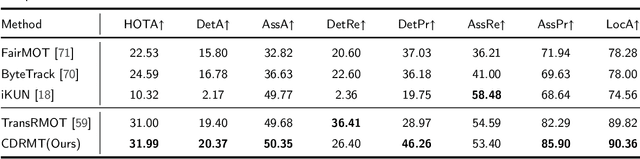
As a significant application of multi-source information fusion in intelligent transportation perception systems, Referring Multi-Object Tracking (RMOT) involves localizing and tracking specific objects in video sequences based on language references. However, existing RMOT approaches often treat language descriptions as holistic embeddings and struggle to effectively integrate the rich semantic information contained in language expressions with visual features. This limitation is especially apparent in complex scenes requiring comprehensive understanding of both static object attributes and spatial motion information. In this paper, we propose a Cognitive Disentanglement for Referring Multi-Object Tracking (CDRMT) framework that addresses these challenges. It adapts the "what" and "where" pathways from human visual processing system to RMOT tasks. Specifically, our framework comprises three collaborative components: (1)The Bidirectional Interactive Fusion module first establishes cross-modal connections while preserving modality-specific characteristics; (2) Building upon this foundation, the Progressive Semantic-Decoupled Query Learning mechanism hierarchically injects complementary information into object queries, progressively refining object understanding from coarse to fine-grained semantic levels; (3) Finally, the Structural Consensus Constraint enforces bidirectional semantic consistency between visual features and language descriptions, ensuring that tracked objects faithfully reflect the referring expression. Extensive experiments on different benchmark datasets demonstrate that CDRMT achieves substantial improvements over state-of-the-art methods, with average gains of 6.0% in HOTA score on Refer-KITTI and 3.2% on Refer-KITTI-V2. Our approach advances the state-of-the-art in RMOT while simultaneously providing new insights into multi-source information fusion.
Talk2PC: Enhancing 3D Visual Grounding through LiDAR and Radar Point Clouds Fusion for Autonomous Driving
Mar 11, 2025Embodied outdoor scene understanding forms the foundation for autonomous agents to perceive, analyze, and react to dynamic driving environments. However, existing 3D understanding is predominantly based on 2D Vision-Language Models (VLMs), collecting and processing limited scene-aware contexts. Instead, compared to the 2D planar visual information, point cloud sensors like LiDAR offer rich depth information and fine-grained 3D representations of objects. Meanwhile, the emerging 4D millimeter-wave (mmWave) radar is capable of detecting the motion trend, velocity, and reflection intensity of each object. Therefore, the integration of these two modalities provides more flexible querying conditions for natural language, enabling more accurate 3D visual grounding. To this end, in this paper, we exploratively propose a novel method called TPCNet, the first outdoor 3D visual grounding model upon the paradigm of prompt-guided point cloud sensor combination, including both LiDAR and radar contexts. To adaptively balance the features of these two sensors required by the prompt, we have designed a multi-fusion paradigm called Two-Stage Heterogeneous Modal Adaptive Fusion. Specifically, this paradigm initially employs Bidirectional Agent Cross-Attention (BACA), which feeds dual-sensor features, characterized by global receptive fields, to the text features for querying. Additionally, we have designed a Dynamic Gated Graph Fusion (DGGF) module to locate the regions of interest identified by the queries. To further enhance accuracy, we innovatively devise an C3D-RECHead, based on the nearest object edge. Our experiments have demonstrated that our TPCNet, along with its individual modules, achieves the state-of-the-art performance on both the Talk2Radar and Talk2Car datasets.