 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmark Everything Everywhere All at Once
Jun 04, 2026Benchmarks are fundamental for evaluating and advancing LLMs and MLLMs by providing standardized and explicit measures of performance. However, their construction is labor-intensive and hard to reuse, raising concerns about sustainability and scalability. Moreover, existing benchmarks often quickly reach performance saturation after their release, resulting in insufficient discrimination among state-of-the-art models. To address these challenges, we introduce Benchmark Agent, a fully autonomous agentic system designed for benchmark building. Our framework orchestrates the complete benchmark construction pipeline, from user query analysis and subtask design to data annotation and quality control. To assess Benchmark Agent, we implement it to produce 15 representative benchmarks, spanning diverse evaluation scenarios, including text understanding, multimodal understanding, and domain-specific reasoning. Extensive experiments, including human evaluation, LLM-as-a-judge assessment, and consistency checks, demonstrate Benchmark Agent can generate high-quality benchmark samples with minimal human involvement. More importantly, through continual evaluation, we observe several insightful findings, including that current models struggle with certain domain-specific reasoning tasks. We believe that rapidly evolving benchmarks can contribute significantly to the research community. The preview and code will be publicly available at the demo page and code repository.
X-Stream: Exploring MLLMs as Multiplexers for Multi-Stream Understanding
Jun 01, 2026While video streaming understanding has made significant strides, real-world applications, such as live sports broadcasting, autonomous driving, and multi-screen collaboration, inherently demand continuous, multi-stream interactions. However, existing benchmarks are confined to single-stream paradigms, leaving a critical gap in evaluating online, cross-stream reasoning. To bridge this, we introduce X-Stream, the first benchmark dedicated to multi-stream streaming understanding. Comprising 4,220 rigorously curated QA pairs across 932 videos, X-Stream evaluates 11 subtasks across multi-window, multi-view, and multi-device scenarios. Crucially, our dataset is constructed using a novel dual-verification pipeline that prevents over-reliance on a single stream. Furthermore, we pioneer the conceptualization of multi-modal large language models (MLLMs) as naive multiplexers, systematically evaluating their performance through the lens of Signal Multiplexing Theory. Our extensive online inference experiments reveal a stark reality: state-of-the-art MLLMs struggle significantly with concurrent streams, achieving only about 50% score and exhibiting poor proactive ability. Ultimately, X-Stream exposes the trade-off of current multiplexing schemes, providing both a practical evaluation protocol and empirical guidance for next-generation multi-stream agents.
From Web to Pixels: Bringing Agentic Search into Visual Perception
May 12, 2026Visual perception connects high-level semantic understanding to pixel-level perception, but most existing settings assume that the decisive evidence for identifying a target is already in the image or frozen model knowledge. We study a more practical yet harder open-world case where a visible object must first be resolved from external facts, recent events, long-tail entities, or multi-hop relations before it can be localized. We formalize this challenge as Perception Deep Research and introduce WebEye, an object-anchored benchmark with verifiable evidence, knowledge-intensive queries, precise box/mask annotations, and three task views: Search-based Grounding, Search-based Segmentation, and Search-based VQA. WebEyes contains 120 images, 473 annotated object instances, 645 unique QA pairs, and 1,927 task samples. We further propose Pixel-Searcher, an agentic search-to-pixel workflow that resolves hidden target identities and binds them to boxes, masks, or grounded answers. Experiments show that Pixel-Searcher achieves the strongest open-source performance across all three task views, while failures mainly arise from evidence acquisition, identity resolution, and visual instance binding.
AutoFly: Vision-Language-Action Model for UAV Autonomous Navigation in the Wild
Feb 10, 2026Vision-language navigation (VLN) requires intelligent agents to navigate environments by interpreting linguistic instructions alongside visual observations, serving as a cornerstone task in Embodied AI. Current VLN research for unmanned aerial vehicles (UAVs) relies on detailed, pre-specified instructions to guide the UAV along predetermined routes. However, real-world outdoor exploration typically occurs in unknown environments where detailed navigation instructions are unavailable. Instead, only coarse-grained positional or directional guidance can be provided, requiring UAVs to autonomously navigate through continuous planning and obstacle avoidance. To bridge this gap, we propose AutoFly, an end-to-end Vision-Language-Action (VLA) model for autonomous UAV navigation. AutoFly incorporates a pseudo-depth encoder that derives depth-aware features from RGB inputs to enhance spatial reasoning, coupled with a progressive two-stage training strategy that effectively aligns visual, depth, and linguistic representations with action policies. Moreover, existing VLN datasets have fundamental limitations for real-world autonomous navigation, stemming from their heavy reliance on explicit instruction-following over autonomous decision-making and insufficient real-world data. To address these issues, we construct a novel autonomous navigation dataset that shifts the paradigm from instruction-following to autonomous behavior modeling through: (1) trajectory collection emphasizing continuous obstacle avoidance, autonomous planning, and recognition workflows; (2) comprehensive real-world data integration. Experimental results demonstrate that AutoFly achieves a 3.9% higher success rate compared to state-of-the-art VLA baselines, with consistent performance across simulated and real environments.
SpaceVista: All-Scale Visual Spatial Reasoning from mm to km
Oct 10, 2025With the current surge in spatial reasoning explorations, researchers have made significant progress in understanding indoor scenes, but still struggle with diverse applications such as robotics and autonomous driving. This paper aims to advance all-scale spatial reasoning across diverse scenarios by tackling two key challenges: 1) the heavy reliance on indoor 3D scans and labor-intensive manual annotations for dataset curation; 2) the absence of effective all-scale scene modeling, which often leads to overfitting to individual scenes. In this paper, we introduce a holistic solution that integrates a structured spatial reasoning knowledge system, scale-aware modeling, and a progressive training paradigm, as the first attempt to broaden the all-scale spatial intelligence of MLLMs to the best of our knowledge. Using a task-specific, specialist-driven automated pipeline, we curate over 38K video scenes across 5 spatial scales to create SpaceVista-1M, a dataset comprising approximately 1M spatial QA pairs spanning 19 diverse task types. While specialist models can inject useful domain knowledge, they are not reliable for evaluation. We then build an all-scale benchmark with precise annotations by manually recording, retrieving, and assembling video-based data. However, naive training with SpaceVista-1M often yields suboptimal results due to the potential knowledge conflict. Accordingly, we introduce SpaceVista-7B, a spatial reasoning model that accepts dense inputs beyond semantics and uses scale as an anchor for scale-aware experts and progressive rewards. Finally, extensive evaluations across 5 benchmarks, including our SpaceVista-Bench, demonstrate competitive performance, showcasing strong generalization across all scales and scenarios. Our dataset, model, and benchmark will be released on https://peiwensun2000.github.io/mm2km .
RAGNet: Large-scale Reasoning-based Affordance Segmentation Benchmark towards General Grasping
Jul 31, 2025



General robotic grasping systems require accurate object affordance perception in diverse open-world scenarios following human instructions. However, current studies suffer from the problem of lacking reasoning-based large-scale affordance prediction data, leading to considerable concern about open-world effectiveness. To address this limitation, we build a large-scale grasping-oriented affordance segmentation benchmark with human-like instructions, named RAGNet. It contains 273k images, 180 categories, and 26k reasoning instructions. The images cover diverse embodied data domains, such as wild, robot, ego-centric, and even simulation data. They are carefully annotated with an affordance map, while the difficulty of language instructions is largely increased by removing their category name and only providing functional descriptions. Furthermore, we propose a comprehensive affordance-based grasping framework, named AffordanceNet, which consists of a VLM pre-trained on our massive affordance data and a grasping network that conditions an affordance map to grasp the target. Extensive experiments on affordance segmentation benchmarks and real-robot manipulation tasks show that our model has a powerful open-world generalization ability. Our data and code is available at https://github.com/wudongming97/AffordanceNet.
Grounding Beyond Detection: Enhancing Contextual Understanding in Embodied 3D Grounding
Jun 05, 2025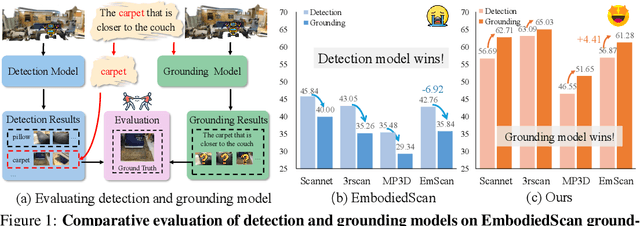
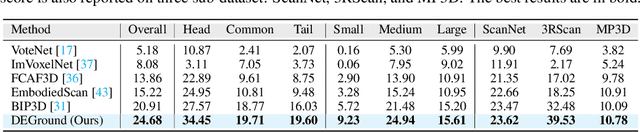
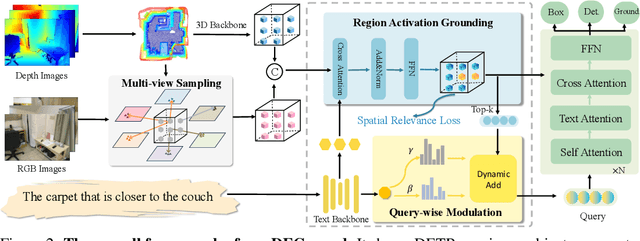
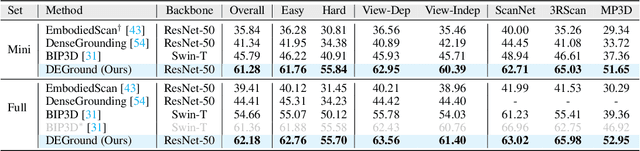
Embodied 3D grounding aims to localize target objects described in human instructions from ego-centric viewpoint. Most methods typically follow a two-stage paradigm where a trained 3D detector's optimized backbone parameters are used to initialize a grounding model. In this study, we explore a fundamental question: Does embodied 3D grounding benefit enough from detection? To answer this question, we assess the grounding performance of detection models using predicted boxes filtered by the target category. Surprisingly, these detection models without any instruction-specific training outperform the grounding models explicitly trained with language instructions. This indicates that even category-level embodied 3D grounding may not be well resolved, let alone more fine-grained context-aware grounding. Motivated by this finding, we propose DEGround, which shares DETR queries as object representation for both DEtection and Grounding and enables the grounding to benefit from basic category classification and box detection. Based on this framework, we further introduce a regional activation grounding module that highlights instruction-related regions and a query-wise modulation module that incorporates sentence-level semantic into the query representation, strengthening the context-aware understanding of language instructions. Remarkably, DEGround outperforms state-of-the-art model BIP3D by 7.52\% at overall accuracy on the EmbodiedScan validation set. The source code will be publicly available at https://github.com/zyn213/DEGround.
Cognitive Disentanglement for Referring Multi-Object Tracking
Mar 14, 2025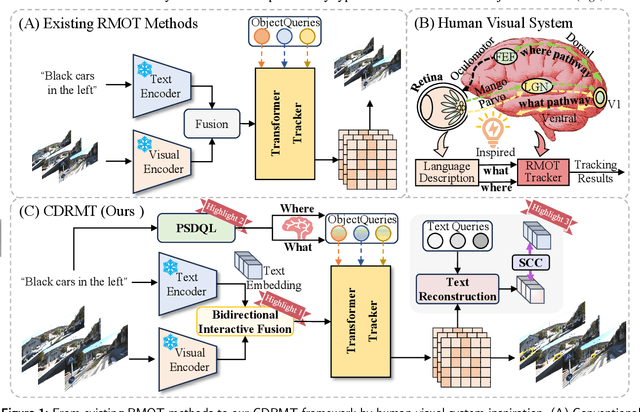
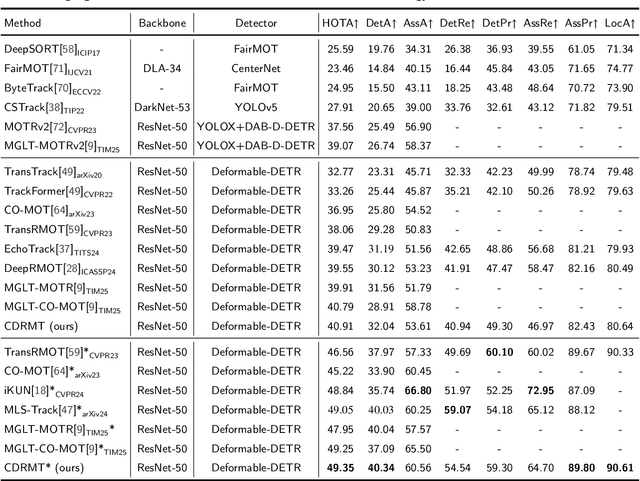
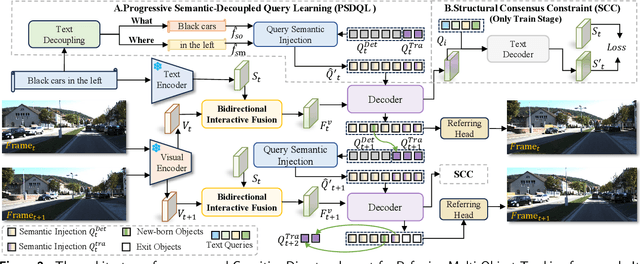
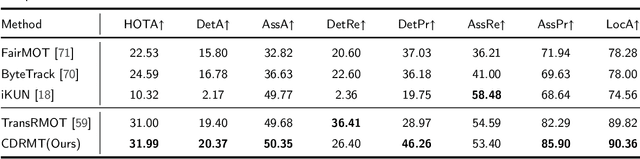
As a significant application of multi-source information fusion in intelligent transportation perception systems, Referring Multi-Object Tracking (RMOT) involves localizing and tracking specific objects in video sequences based on language references. However, existing RMOT approaches often treat language descriptions as holistic embeddings and struggle to effectively integrate the rich semantic information contained in language expressions with visual features. This limitation is especially apparent in complex scenes requiring comprehensive understanding of both static object attributes and spatial motion information. In this paper, we propose a Cognitive Disentanglement for Referring Multi-Object Tracking (CDRMT) framework that addresses these challenges. It adapts the "what" and "where" pathways from human visual processing system to RMOT tasks. Specifically, our framework comprises three collaborative components: (1)The Bidirectional Interactive Fusion module first establishes cross-modal connections while preserving modality-specific characteristics; (2) Building upon this foundation, the Progressive Semantic-Decoupled Query Learning mechanism hierarchically injects complementary information into object queries, progressively refining object understanding from coarse to fine-grained semantic levels; (3) Finally, the Structural Consensus Constraint enforces bidirectional semantic consistency between visual features and language descriptions, ensuring that tracked objects faithfully reflect the referring expression. Extensive experiments on different benchmark datasets demonstrate that CDRMT achieves substantial improvements over state-of-the-art methods, with average gains of 6.0% in HOTA score on Refer-KITTI and 3.2% on Refer-KITTI-V2. Our approach advances the state-of-the-art in RMOT while simultaneously providing new insights into multi-source information fusion.
DrivingSphere: Building a High-fidelity 4D World for Closed-loop Simulation
Nov 18, 2024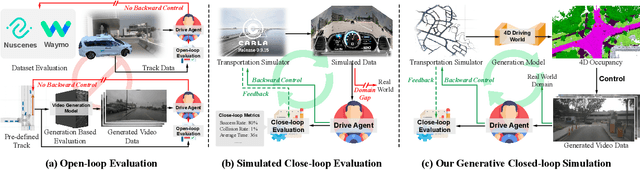
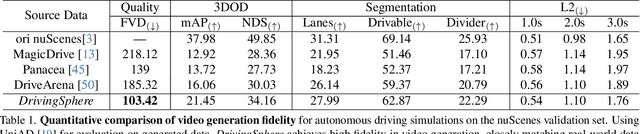
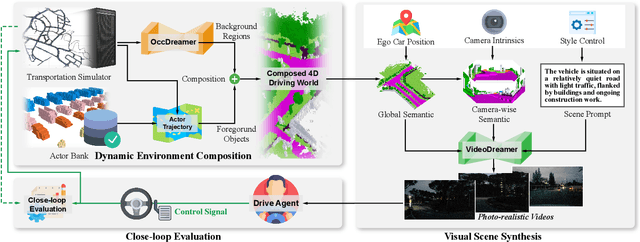

Autonomous driving evaluation requires simulation environments that closely replicate actual road conditions, including real-world sensory data and responsive feedback loops. However, many existing simulations need to predict waypoints along fixed routes on public datasets or synthetic photorealistic data, \ie, open-loop simulation usually lacks the ability to assess dynamic decision-making. While the recent efforts of closed-loop simulation offer feedback-driven environments, they cannot process visual sensor inputs or produce outputs that differ from real-world data. To address these challenges, we propose DrivingSphere, a realistic and closed-loop simulation framework. Its core idea is to build 4D world representation and generate real-life and controllable driving scenarios. In specific, our framework includes a Dynamic Environment Composition module that constructs a detailed 4D driving world with a format of occupancy equipping with static backgrounds and dynamic objects, and a Visual Scene Synthesis module that transforms this data into high-fidelity, multi-view video outputs, ensuring spatial and temporal consistency. By providing a dynamic and realistic simulation environment, DrivingSphere enables comprehensive testing and validation of autonomous driving algorithms, ultimately advancing the development of more reliable autonomous cars. The benchmark will be publicly released.
Bootstrapping Referring Multi-Object Tracking
Jun 07, 2024



Referring multi-object tracking (RMOT) aims at detecting and tracking multiple objects following human instruction represented by a natural language expression. Existing RMOT benchmarks are usually formulated through manual annotations, integrated with static regulations. This approach results in a dearth of notable diversity and a constrained scope of implementation. In this work, our key idea is to bootstrap the task of referring multi-object tracking by introducing discriminative language words as much as possible. In specific, we first develop Refer-KITTI into a large-scale dataset, named Refer-KITTI-V2. It starts with 2,719 manual annotations, addressing the issue of class imbalance and introducing more keywords to make it closer to real-world scenarios compared to Refer-KITTI. They are further expanded to a total of 9,758 annotations by prompting large language models, which create 617 different words, surpassing previous RMOT benchmarks. In addition, the end-to-end framework in RMOT is also bootstrapped by a simple yet elegant temporal advancement strategy, which achieves better performance than previous approaches. The source code and dataset is available at https://github.com/zyn213/TempRMOT.