 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Scene Generation and Planning: Driving with World Model via Unifying Vision and Motion Representation
Mar 16, 2026End-to-end autonomous driving aims to generate safe and plausible planning policies from raw sensor input. Driving world models have shown great potential in learning rich representations by predicting the future evolution of a driving scene. However, existing driving world models primarily focus on visual scene representation, and motion representation is not explicitly designed to be planner-shared and inheritable, leaving a schism between the optimization of visual scene generation and the requirements of precise motion planning. We present WorldDrive, a holistic framework that couples scene generation and real-time planning via unifying vision and motion representation. We first introduce a Trajectory-aware Driving World Model, which conditions on a trajectory vocabulary to enforce consistency between visual dynamics and motion intentions, enabling the generation of diverse and plausible future scenes conditioned on a specific trajectory. We transfer the vision and motion encoders to a downstream Multi-modal Planner, ensuring the driving policy operates on mature representations pre-optimized by scene generation. A simple interaction between motion representation, visual representation, and ego status can generate high-quality, multi-modal trajectories. Furthermore, to exploit the world model's foresight, we propose a Future-aware Rewarder, which distills future latent representation from the frozen world model to evaluate and select optimal trajectories in real-time. Extensive experiments on the NAVSIM, NAVSIM-v2, and nuScenes benchmarks demonstrate that WorldDrive achieves leading planning performance among vision-only methods while maintaining high-fidelity action-controlled video generation capabilities, providing strong evidence for the effectiveness of unifying vision and motion representation for robust autonomous driving.
Theoretical Analysis of Relative Errors in Gradient Computations for Adversarial Attacks with CE Loss
Jul 30, 2025Gradient-based adversarial attacks using the Cross-Entropy (CE) loss often suffer from overestimation due to relative errors in gradient computation induced by floating-point arithmetic. This paper provides a rigorous theoretical analysis of these errors, conducting the first comprehensive study of floating-point computation errors in gradient-based attacks across four distinct scenarios: (i) unsuccessful untargeted attacks, (ii) successful untargeted attacks, (iii) unsuccessful targeted attacks, and (iv) successful targeted attacks. We establish theoretical foundations characterizing the behavior of relative numerical errors under different attack conditions, revealing previously unknown patterns in gradient computation instability, and identify floating-point underflow and rounding as key contributors. Building on this insight, we propose the Theoretical MIFPE (T-MIFPE) loss function, which incorporates an optimal scaling factor $T = t^*$ to minimize the impact of floating-point errors, thereby enhancing the accuracy of gradient computation in adversarial attacks. Extensive experiments on the MNIST, CIFAR-10, and CIFAR-100 datasets demonstrate that T-MIFPE outperforms existing loss functions, including CE, C\&W, DLR, and MIFPE, in terms of attack potency and robustness evaluation accuracy.
Mixture of Weight-shared Heterogeneous Group Attention Experts for Dynamic Token-wise KV Optimization
Jun 16, 2025
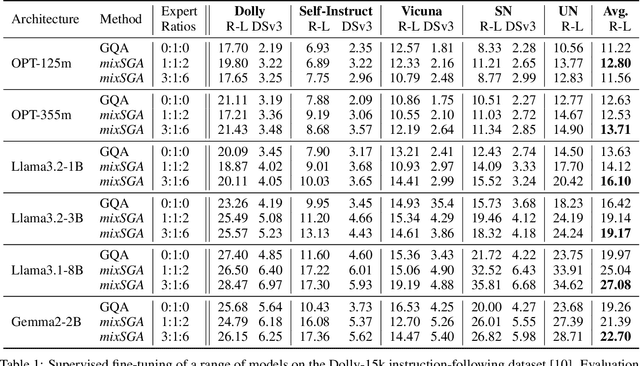
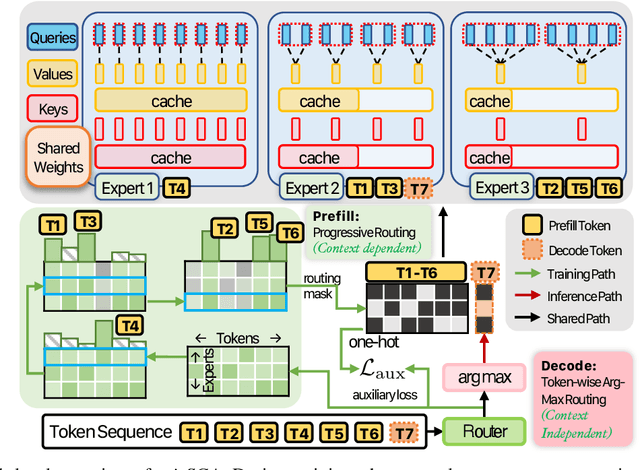

Transformer models face scalability challenges in causal language modeling (CLM) due to inefficient memory allocation for growing key-value (KV) caches, which strains compute and storage resources. Existing methods like Grouped Query Attention (GQA) and token-level KV optimization improve efficiency but rely on rigid resource allocation, often discarding "low-priority" tokens or statically grouping them, failing to address the dynamic spectrum of token importance. We propose mixSGA, a novel mixture-of-expert (MoE) approach that dynamically optimizes token-wise computation and memory allocation. Unlike prior approaches, mixSGA retains all tokens while adaptively routing them to specialized experts with varying KV group sizes, balancing granularity and efficiency. Our key novelties include: (1) a token-wise expert-choice routing mechanism guided by learned importance scores, enabling proportional resource allocation without token discard; (2) weight-sharing across grouped attention projections to minimize parameter overhead; and (3) an auxiliary loss to ensure one-hot routing decisions for training-inference consistency in CLMs. Extensive evaluations across Llama3, TinyLlama, OPT, and Gemma2 model families show mixSGA's superiority over static baselines. On instruction-following and continued pretraining tasks, mixSGA achieves higher ROUGE-L and lower perplexity under the same KV budgets.
Geometry-aware Temporal Aggregation Network for Monocular 3D Lane Detection
Apr 29, 2025Monocular 3D lane detection aims to estimate 3D position of lanes from frontal-view (FV) images. However, current monocular 3D lane detection methods suffer from two limitations, including inaccurate geometric information of the predicted 3D lanes and difficulties in maintaining lane integrity. To address these issues, we seek to fully exploit the potential of multiple input frames. First, we aim at enhancing the ability to perceive the geometry of scenes by leveraging temporal geometric consistency. Second, we strive to improve the integrity of lanes by revealing more instance information from temporal sequences. Therefore, we propose a novel Geometry-aware Temporal Aggregation Network (GTA-Net) for monocular 3D lane detection. On one hand, we develop the Temporal Geometry Enhancement Module (TGEM), which exploits geometric consistency across successive frames, facilitating effective geometry perception. On the other hand, we present the Temporal Instance-aware Query Generation (TIQG), which strategically incorporates temporal cues into query generation, thereby enabling the exploration of comprehensive instance information. Experiments demonstrate that our GTA-Net achieves SoTA results, surpassing existing monocular 3D lane detection solutions.
DrivingSphere: Building a High-fidelity 4D World for Closed-loop Simulation
Nov 18, 2024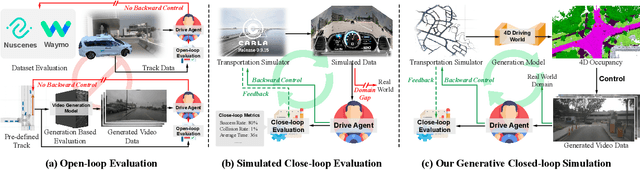
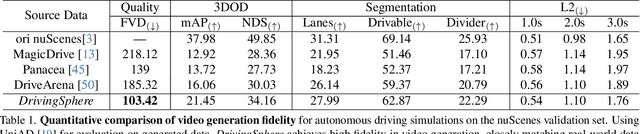
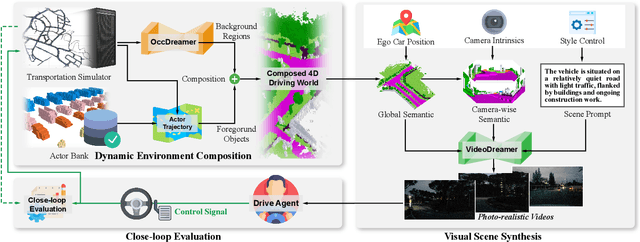

Autonomous driving evaluation requires simulation environments that closely replicate actual road conditions, including real-world sensory data and responsive feedback loops. However, many existing simulations need to predict waypoints along fixed routes on public datasets or synthetic photorealistic data, \ie, open-loop simulation usually lacks the ability to assess dynamic decision-making. While the recent efforts of closed-loop simulation offer feedback-driven environments, they cannot process visual sensor inputs or produce outputs that differ from real-world data. To address these challenges, we propose DrivingSphere, a realistic and closed-loop simulation framework. Its core idea is to build 4D world representation and generate real-life and controllable driving scenarios. In specific, our framework includes a Dynamic Environment Composition module that constructs a detailed 4D driving world with a format of occupancy equipping with static backgrounds and dynamic objects, and a Visual Scene Synthesis module that transforms this data into high-fidelity, multi-view video outputs, ensuring spatial and temporal consistency. By providing a dynamic and realistic simulation environment, DrivingSphere enables comprehensive testing and validation of autonomous driving algorithms, ultimately advancing the development of more reliable autonomous cars. The benchmark will be publicly released.
HMoE: Heterogeneous Mixture of Experts for Language Modeling
Aug 20, 2024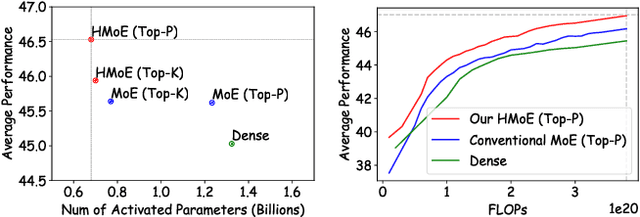
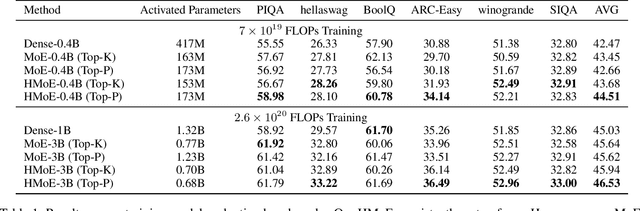
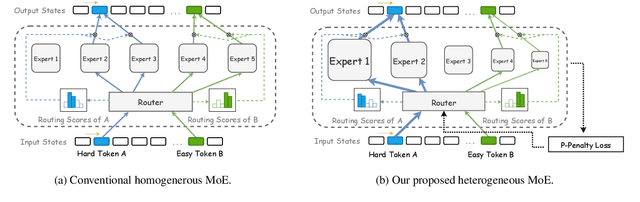

Mixture of Experts (MoE) offers remarkable performance and computational efficiency by selectively activating subsets of model parameters. Traditionally, MoE models use homogeneous experts, each with identical capacity. However, varying complexity in input data necessitates experts with diverse capabilities, while homogeneous MoE hinders effective expert specialization and efficient parameter utilization. In this study, we propose a novel Heterogeneous Mixture of Experts (HMoE), where experts differ in size and thus possess diverse capacities. This heterogeneity allows for more specialized experts to handle varying token complexities more effectively. To address the imbalance in expert activation, we propose a novel training objective that encourages the frequent activation of smaller experts, enhancing computational efficiency and parameter utilization. Extensive experiments demonstrate that HMoE achieves lower loss with fewer activated parameters and outperforms conventional homogeneous MoE models on various pre-training evaluation benchmarks. Codes will be released upon acceptance.
Weakly Supervised Monocular 3D Object Detection using Multi-View Projection and Direction Consistency
Mar 15, 2023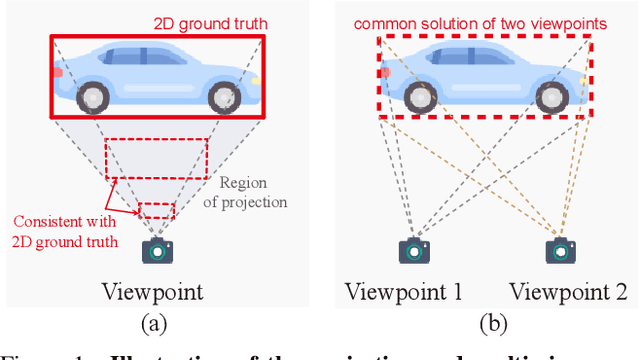
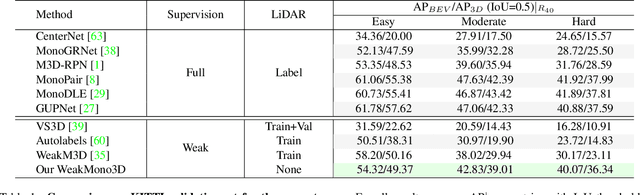
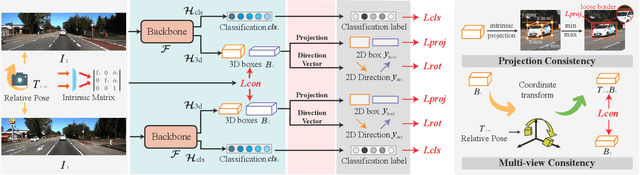
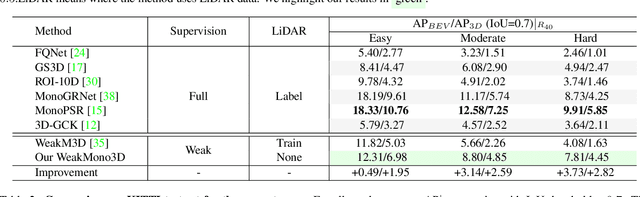
Monocular 3D object detection has become a mainstream approach in automatic driving for its easy application. A prominent advantage is that it does not need LiDAR point clouds during the inference. However, most current methods still rely on 3D point cloud data for labeling the ground truths used in the training phase. This inconsistency between the training and inference makes it hard to utilize the large-scale feedback data and increases the data collection expenses. To bridge this gap, we propose a new weakly supervised monocular 3D objection detection method, which can train the model with only 2D labels marked on images. To be specific, we explore three types of consistency in this task, i.e. the projection, multi-view and direction consistency, and design a weakly-supervised architecture based on these consistencies. Moreover, we propose a new 2D direction labeling method in this task to guide the model for accurate rotation direction prediction. Experiments show that our weakly-supervised method achieves comparable performance with some fully supervised methods. When used as a pre-training method, our model can significantly outperform the corresponding fully-supervised baseline with only 1/3 3D labels. https://github.com/weakmono3d/weakmono3d
Dynamic Channel Pruning: Feature Boosting and Suppression
Oct 12, 2018

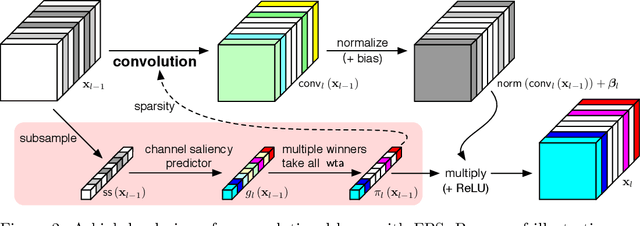
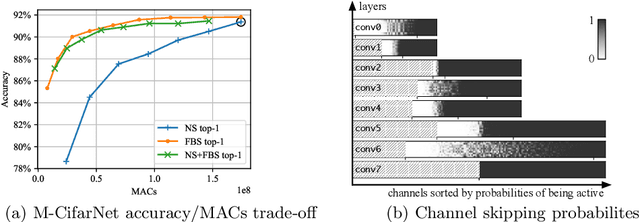
Making deep convolutional neural networks more accurate typically comes at the cost of increased computational and memory resources. In this paper, we exploit the fact that the importance of features computed by convolutional layers is highly input-dependent, and propose feature boosting and suppression (FBS), a new method to predictively amplify salient convolutional channels and skip unimportant ones at run-time. FBS introduces small auxiliary connections to existing convolutional layers. In contrast to channel pruning methods which permanently remove channels, it preserves the full network structures and accelerates convolution by dynamically skipping unimportant input and output channels. FBS-augmented networks are trained with conventional stochastic gradient descent, making it readily available for many state-of-the-art CNNs. We compare FBS to a range of existing channel pruning and dynamic execution schemes and demonstrate large improvements on ImageNet classification. Experiments show that FBS can accelerate VGG-16 by $5\times$ and improve the speed of ResNet-18 by $2\times$, both with less than $0.6\%$ top-5 accuracy loss.