 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Human Intention to Action Prediction: A Comprehensive Benchmark for Intention-driven End-to-End Autonomous Driving
Dec 13, 2025Current end-to-end autonomous driving systems operate at a level of intelligence akin to following simple steering commands. However, achieving genuinely intelligent autonomy requires a paradigm shift: moving from merely executing low-level instructions to understanding and fulfilling high-level, abstract human intentions. This leap from a command-follower to an intention-fulfiller, as illustrated in our conceptual framework, is hindered by a fundamental challenge: the absence of a standardized benchmark to measure and drive progress on this complex task. To address this critical gap, we introduce Intention-Drive, the first comprehensive benchmark designed to evaluate the ability to translate high-level human intent into safe and precise driving actions. Intention-Drive features two core contributions: (1) a new dataset of complex scenarios paired with corresponding natural language intentions, and (2) a novel evaluation protocol centered on the Intent Success Rate (ISR), which assesses the semantic fulfillment of the human's goal beyond simple geometric accuracy. Through an extensive evaluation of a spectrum of baseline models on Intention-Drive, we reveal a significant performance deficit, showing that the baseline model struggle to achieve the comprehensive scene and intention understanding required for this advanced task.
Weakly Supervised Monocular 3D Object Detection using Multi-View Projection and Direction Consistency
Mar 15, 2023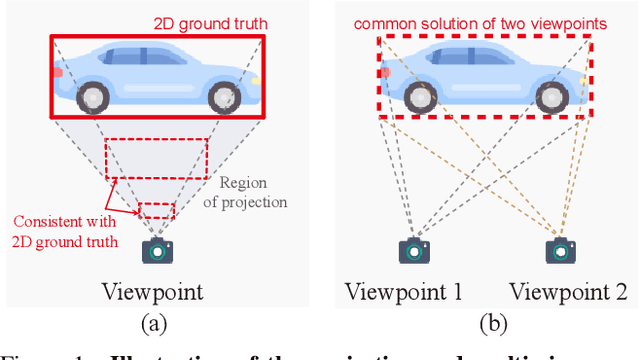
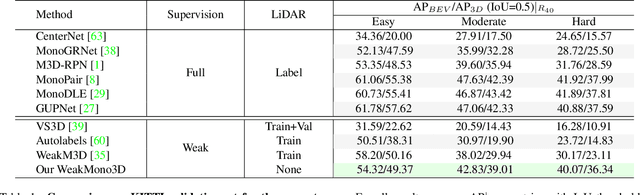
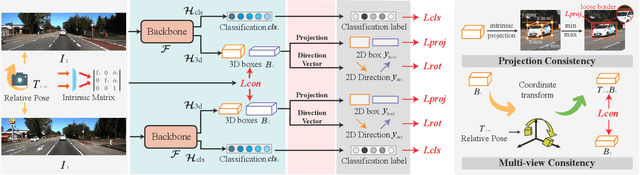
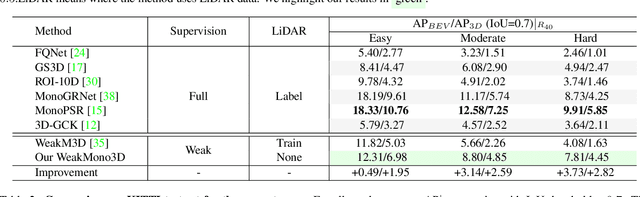
Monocular 3D object detection has become a mainstream approach in automatic driving for its easy application. A prominent advantage is that it does not need LiDAR point clouds during the inference. However, most current methods still rely on 3D point cloud data for labeling the ground truths used in the training phase. This inconsistency between the training and inference makes it hard to utilize the large-scale feedback data and increases the data collection expenses. To bridge this gap, we propose a new weakly supervised monocular 3D objection detection method, which can train the model with only 2D labels marked on images. To be specific, we explore three types of consistency in this task, i.e. the projection, multi-view and direction consistency, and design a weakly-supervised architecture based on these consistencies. Moreover, we propose a new 2D direction labeling method in this task to guide the model for accurate rotation direction prediction. Experiments show that our weakly-supervised method achieves comparable performance with some fully supervised methods. When used as a pre-training method, our model can significantly outperform the corresponding fully-supervised baseline with only 1/3 3D labels. https://github.com/weakmono3d/weakmono3d