 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixture of Weight-shared Heterogeneous Group Attention Experts for Dynamic Token-wise KV Optimization
Jun 16, 2025
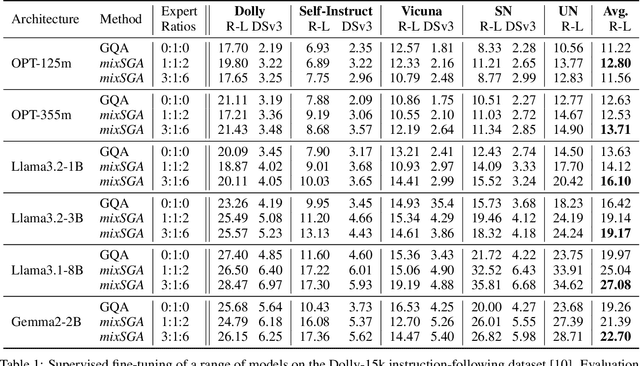
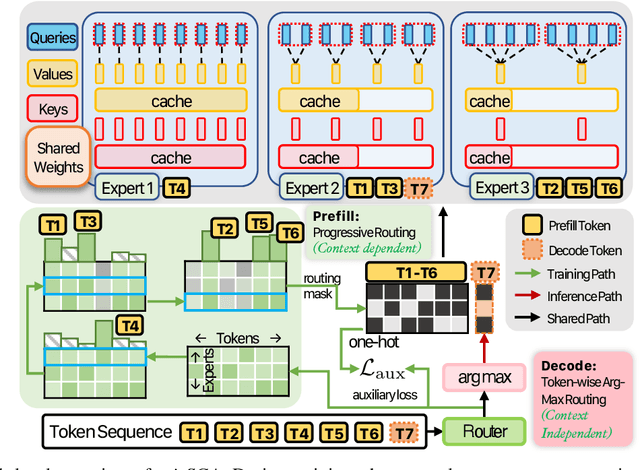

Transformer models face scalability challenges in causal language modeling (CLM) due to inefficient memory allocation for growing key-value (KV) caches, which strains compute and storage resources. Existing methods like Grouped Query Attention (GQA) and token-level KV optimization improve efficiency but rely on rigid resource allocation, often discarding "low-priority" tokens or statically grouping them, failing to address the dynamic spectrum of token importance. We propose mixSGA, a novel mixture-of-expert (MoE) approach that dynamically optimizes token-wise computation and memory allocation. Unlike prior approaches, mixSGA retains all tokens while adaptively routing them to specialized experts with varying KV group sizes, balancing granularity and efficiency. Our key novelties include: (1) a token-wise expert-choice routing mechanism guided by learned importance scores, enabling proportional resource allocation without token discard; (2) weight-sharing across grouped attention projections to minimize parameter overhead; and (3) an auxiliary loss to ensure one-hot routing decisions for training-inference consistency in CLMs. Extensive evaluations across Llama3, TinyLlama, OPT, and Gemma2 model families show mixSGA's superiority over static baselines. On instruction-following and continued pretraining tasks, mixSGA achieves higher ROUGE-L and lower perplexity under the same KV budgets.
FLIP: Towards Comprehensive and Reliable Evaluation of Federated Prompt Learning
Mar 28, 2025The increasing emphasis on privacy and data security has driven the adoption of federated learning, a decentralized approach to train machine learning models without sharing raw data. Prompt learning, which fine-tunes prompt embeddings of pretrained models, offers significant advantages in federated settings by reducing computational costs and communication overheads while leveraging the strong performance and generalization capabilities of vision-language models such as CLIP. This paper addresses the intersection of federated learning and prompt learning, particularly for vision-language models. In this work, we introduce a comprehensive framework, named FLIP, to evaluate federated prompt learning algorithms. FLIP assesses the performance of 8 state-of-the-art federated prompt learning methods across 4 federated learning protocols and 12 open datasets, considering 6 distinct evaluation scenarios. Our findings demonstrate that prompt learning maintains strong generalization performance in both in-distribution and out-of-distribution settings with minimal resource consumption. This work highlights the effectiveness of federated prompt learning in environments characterized by data scarcity, unseen classes, and cross-domain distributional shifts. We open-source the code for all implemented algorithms in FLIP to facilitate further research in this domain.
MFTraj: Map-Free, Behavior-Driven Trajectory Prediction for Autonomous Driving
May 02, 2024



This paper introduces a trajectory prediction model tailored for autonomous driving, focusing on capturing complex interactions in dynamic traffic scenarios without reliance on high-definition maps. The model, termed MFTraj, harnesses historical trajectory data combined with a novel dynamic geometric graph-based behavior-aware module. At its core, an adaptive structure-aware interactive graph convolutional network captures both positional and behavioral features of road users, preserving spatial-temporal intricacies. Enhanced by a linear attention mechanism, the model achieves computational efficiency and reduced parameter overhead. Evaluations on the Argoverse, NGSIM, HighD, and MoCAD datasets underscore MFTraj's robustness and adaptability, outperforming numerous benchmarks even in data-challenged scenarios without the need for additional information such as HD maps or vectorized maps. Importantly, it maintains competitive performance even in scenarios with substantial missing data, on par with most existing state-of-the-art models. The results and methodology suggest a significant advancement in autonomous driving trajectory prediction, paving the way for safer and more efficient autonomous systems.
BAT: Behavior-Aware Human-Like Trajectory Prediction for Autonomous Driving
Dec 15, 2023



The ability to accurately predict the trajectory of surrounding vehicles is a critical hurdle to overcome on the journey to fully autonomous vehicles. To address this challenge, we pioneer a novel behavior-aware trajectory prediction model (BAT) that incorporates insights and findings from traffic psychology, human behavior, and decision-making. Our model consists of behavior-aware, interaction-aware, priority-aware, and position-aware modules that perceive and understand the underlying interactions and account for uncertainty and variability in prediction, enabling higher-level learning and flexibility without rigid categorization of driving behavior. Importantly, this approach eliminates the need for manual labeling in the training process and addresses the challenges of non-continuous behavior labeling and the selection of appropriate time windows. We evaluate BAT's performance across the Next Generation Simulation (NGSIM), Highway Drone (HighD), Roundabout Drone (RounD), and Macao Connected Autonomous Driving (MoCAD) datasets, showcasing its superiority over prevailing state-of-the-art (SOTA) benchmarks in terms of prediction accuracy and efficiency. Remarkably, even when trained on reduced portions of the training data (25%), our model outperforms most of the baselines, demonstrating its robustness and efficiency in predicting vehicle trajectories, and the potential to reduce the amount of data required to train autonomous vehicles, especially in corner cases. In conclusion, the behavior-aware model represents a significant advancement in the development of autonomous vehicles capable of predicting trajectories with the same level of proficiency as human drivers. The project page is available at https://github.com/Petrichor625/BATraj-Behavior-aware-Model.
Deep Density-aware Count Regressor
Aug 09, 2019
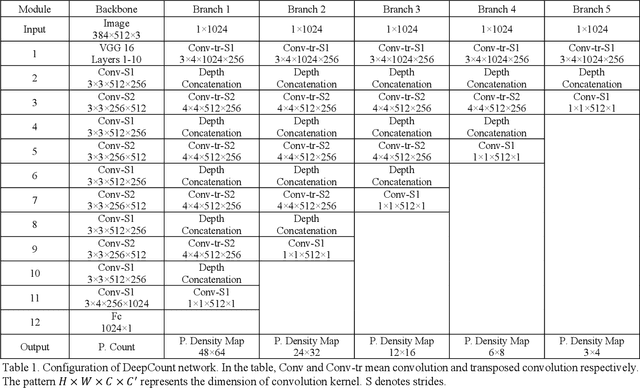
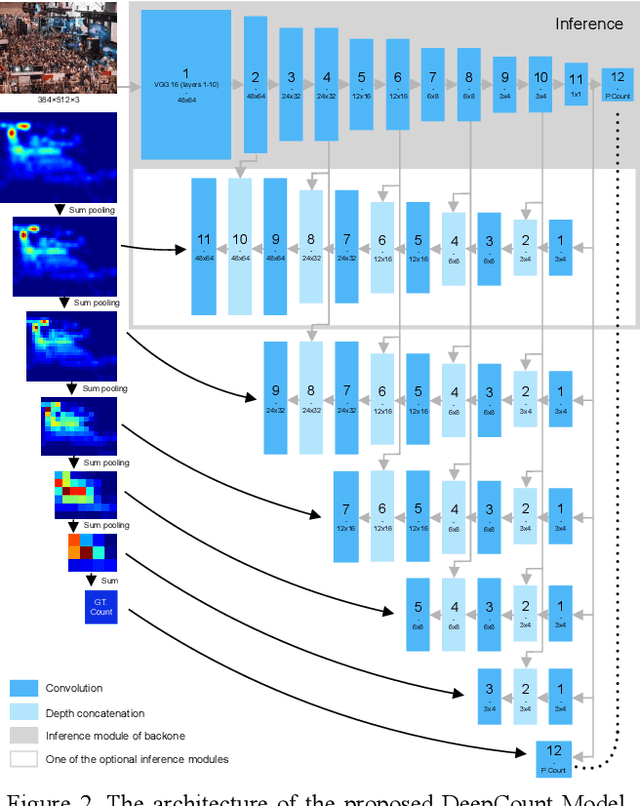
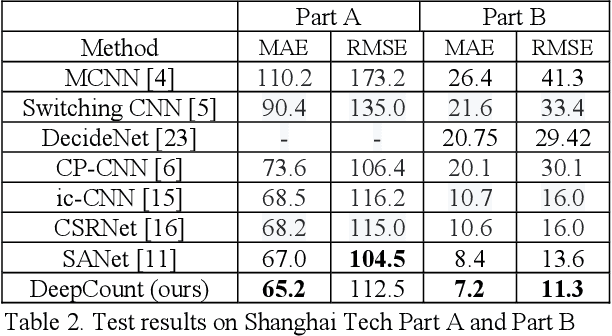
We seek to improve crowd counting as we perceive limits of currently prevalent density map estimation approach on both prediction accuracy and time efficiency. We show that a CNN regressing a global count trained with density map supervision can make more accurate prediction. We introduce multilayer gradient fusion for training a densityaware global count regressor. More specifically, on training stage, a backbone network receives gradients from multiple branches to learn the density information, whereas those branches are to be detached to accelerate inference. By taking advantages of such method, our model improves benchmark results on public datasets and exhibits itself to be a new solution to crowd counting problem in practice.