 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCRASH: Crash Recognition and Anticipation System Harnessing with Context-Aware and Temporal Focus Attentions
Jul 25, 2024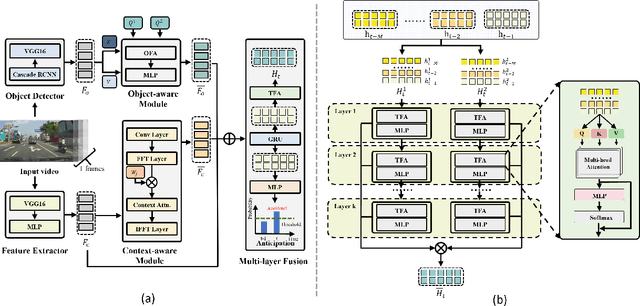



Accurately and promptly predicting accidents among surrounding traffic agents from camera footage is crucial for the safety of autonomous vehicles (AVs). This task presents substantial challenges stemming from the unpredictable nature of traffic accidents, their long-tail distribution, the intricacies of traffic scene dynamics, and the inherently constrained field of vision of onboard cameras. To address these challenges, this study introduces a novel accident anticipation framework for AVs, termed CRASH. It seamlessly integrates five components: object detector, feature extractor, object-aware module, context-aware module, and multi-layer fusion. Specifically, we develop the object-aware module to prioritize high-risk objects in complex and ambiguous environments by calculating the spatial-temporal relationships between traffic agents. In parallel, the context-aware is also devised to extend global visual information from the temporal to the frequency domain using the Fast Fourier Transform (FFT) and capture fine-grained visual features of potential objects and broader context cues within traffic scenes. To capture a wider range of visual cues, we further propose a multi-layer fusion that dynamically computes the temporal dependencies between different scenes and iteratively updates the correlations between different visual features for accurate and timely accident prediction. Evaluated on real-world datasets--Dashcam Accident Dataset (DAD), Car Crash Dataset (CCD), and AnAn Accident Detection (A3D) datasets--our model surpasses existing top baselines in critical evaluation metrics like Average Precision (AP) and mean Time-To-Accident (mTTA). Importantly, its robustness and adaptability are particularly evident in challenging driving scenarios with missing or limited training data, demonstrating significant potential for application in real-world autonomous driving systems.
MFTraj: Map-Free, Behavior-Driven Trajectory Prediction for Autonomous Driving
May 02, 2024



This paper introduces a trajectory prediction model tailored for autonomous driving, focusing on capturing complex interactions in dynamic traffic scenarios without reliance on high-definition maps. The model, termed MFTraj, harnesses historical trajectory data combined with a novel dynamic geometric graph-based behavior-aware module. At its core, an adaptive structure-aware interactive graph convolutional network captures both positional and behavioral features of road users, preserving spatial-temporal intricacies. Enhanced by a linear attention mechanism, the model achieves computational efficiency and reduced parameter overhead. Evaluations on the Argoverse, NGSIM, HighD, and MoCAD datasets underscore MFTraj's robustness and adaptability, outperforming numerous benchmarks even in data-challenged scenarios without the need for additional information such as HD maps or vectorized maps. Importantly, it maintains competitive performance even in scenarios with substantial missing data, on par with most existing state-of-the-art models. The results and methodology suggest a significant advancement in autonomous driving trajectory prediction, paving the way for safer and more efficient autonomous systems.
BAT: Behavior-Aware Human-Like Trajectory Prediction for Autonomous Driving
Dec 15, 2023



The ability to accurately predict the trajectory of surrounding vehicles is a critical hurdle to overcome on the journey to fully autonomous vehicles. To address this challenge, we pioneer a novel behavior-aware trajectory prediction model (BAT) that incorporates insights and findings from traffic psychology, human behavior, and decision-making. Our model consists of behavior-aware, interaction-aware, priority-aware, and position-aware modules that perceive and understand the underlying interactions and account for uncertainty and variability in prediction, enabling higher-level learning and flexibility without rigid categorization of driving behavior. Importantly, this approach eliminates the need for manual labeling in the training process and addresses the challenges of non-continuous behavior labeling and the selection of appropriate time windows. We evaluate BAT's performance across the Next Generation Simulation (NGSIM), Highway Drone (HighD), Roundabout Drone (RounD), and Macao Connected Autonomous Driving (MoCAD) datasets, showcasing its superiority over prevailing state-of-the-art (SOTA) benchmarks in terms of prediction accuracy and efficiency. Remarkably, even when trained on reduced portions of the training data (25%), our model outperforms most of the baselines, demonstrating its robustness and efficiency in predicting vehicle trajectories, and the potential to reduce the amount of data required to train autonomous vehicles, especially in corner cases. In conclusion, the behavior-aware model represents a significant advancement in the development of autonomous vehicles capable of predicting trajectories with the same level of proficiency as human drivers. The project page is available at https://github.com/Petrichor625/BATraj-Behavior-aware-Model.
GPT-4 Enhanced Multimodal Grounding for Autonomous Driving: Leveraging Cross-Modal Attention with Large Language Models
Dec 06, 2023



In the field of autonomous vehicles (AVs), accurately discerning commander intent and executing linguistic commands within a visual context presents a significant challenge. This paper introduces a sophisticated encoder-decoder framework, developed to address visual grounding in AVs.Our Context-Aware Visual Grounding (CAVG) model is an advanced system that integrates five core encoders-Text, Image, Context, and Cross-Modal-with a Multimodal decoder. This integration enables the CAVG model to adeptly capture contextual semantics and to learn human emotional features, augmented by state-of-the-art Large Language Models (LLMs) including GPT-4. The architecture of CAVG is reinforced by the implementation of multi-head cross-modal attention mechanisms and a Region-Specific Dynamic (RSD) layer for attention modulation. This architectural design enables the model to efficiently process and interpret a range of cross-modal inputs, yielding a comprehensive understanding of the correlation between verbal commands and corresponding visual scenes. Empirical evaluations on the Talk2Car dataset, a real-world benchmark, demonstrate that CAVG establishes new standards in prediction accuracy and operational efficiency. Notably, the model exhibits exceptional performance even with limited training data, ranging from 50% to 75% of the full dataset. This feature highlights its effectiveness and potential for deployment in practical AV applications. Moreover, CAVG has shown remarkable robustness and adaptability in challenging scenarios, including long-text command interpretation, low-light conditions, ambiguous command contexts, inclement weather conditions, and densely populated urban environments. The code for the proposed model is available at our Github.