 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFloe: Federated Specialization for Real-Time LLM-SLM Inference
Feb 15, 2026Deploying large language models (LLMs) in real-time systems remains challenging due to their substantial computational demands and privacy concerns. We propose Floe, a hybrid federated learning framework designed for latency-sensitive, resource-constrained environments. Floe combines a cloud-based black-box LLM with lightweight small language models (SLMs) on edge devices to enable low-latency, privacy-preserving inference. Personal data and fine-tuning remain on-device, while the cloud LLM contributes general knowledge without exposing proprietary weights. A heterogeneity-aware LoRA adaptation strategy enables efficient edge deployment across diverse hardware, and a logit-level fusion mechanism enables real-time coordination between edge and cloud models. Extensive experiments demonstrate that Floe enhances user privacy and personalization. Moreover, it significantly improves model performance and reduces inference latency on edge devices under real-time constraints compared with baseline approaches.
A Survey on Federated Fine-tuning of Large Language Models
Mar 15, 2025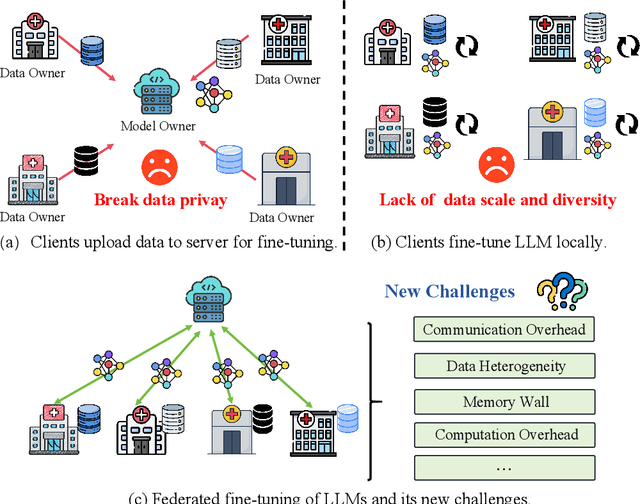
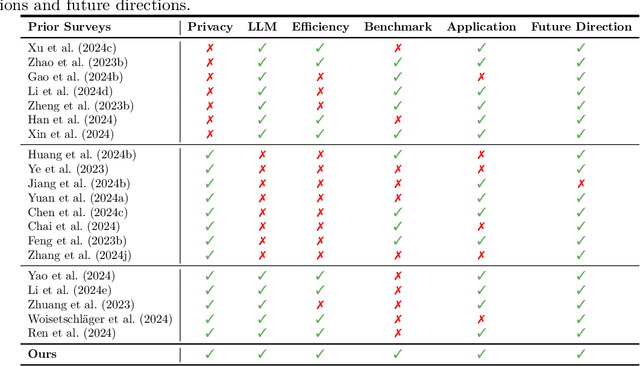
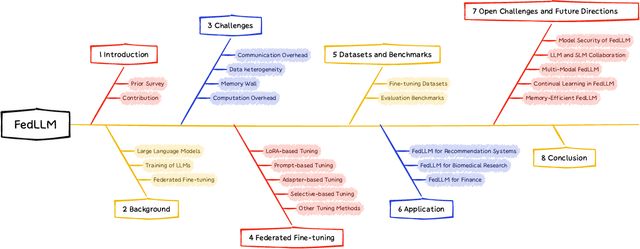

Large Language Models (LLMs) have achieved remarkable success across a wide range of tasks, with fine-tuning playing a pivotal role in adapting them to specific downstream applications. Federated Learning (FL) offers a promising approach that enables collaborative model adaptation while ensuring data privacy, i.e., FedLLM. In this survey, we provide a systematic and thorough review of the integration of LLMs with FL. Specifically, we first trace the historical evolution of both LLMs and FL, while summarizing relevant prior surveys. We then present an in-depth analysis of the fundamental challenges encountered in deploying FedLLM. Following this, we conduct an extensive study of existing parameter-efficient fine-tuning (PEFT) methods and explore their applicability in FL. Furthermore, we introduce a comprehensive evaluation benchmark to rigorously assess FedLLM performance and discuss its diverse real-world applications across multiple domains. Finally, we identify critical open challenges and outline promising research directions to drive future advancements in FedLLM. We maintain an active \href{https://github.com/Clin0212/Awesome-Federated-LLM-Learning}{GitHub repository} tracking cutting-edge advancements. This survey serves as a foundational resource for researchers and practitioners, offering insights into the evolving landscape of federated fine-tuning for LLMs while guiding future innovations in privacy-preserving AI.
CRASH: Crash Recognition and Anticipation System Harnessing with Context-Aware and Temporal Focus Attentions
Jul 25, 2024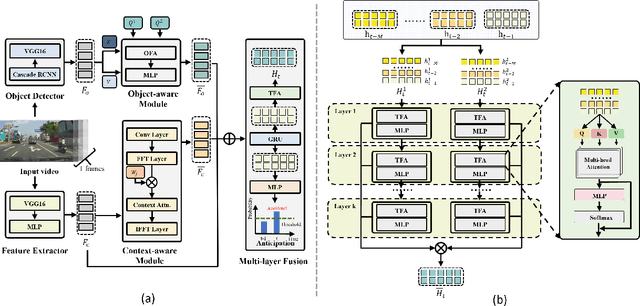



Accurately and promptly predicting accidents among surrounding traffic agents from camera footage is crucial for the safety of autonomous vehicles (AVs). This task presents substantial challenges stemming from the unpredictable nature of traffic accidents, their long-tail distribution, the intricacies of traffic scene dynamics, and the inherently constrained field of vision of onboard cameras. To address these challenges, this study introduces a novel accident anticipation framework for AVs, termed CRASH. It seamlessly integrates five components: object detector, feature extractor, object-aware module, context-aware module, and multi-layer fusion. Specifically, we develop the object-aware module to prioritize high-risk objects in complex and ambiguous environments by calculating the spatial-temporal relationships between traffic agents. In parallel, the context-aware is also devised to extend global visual information from the temporal to the frequency domain using the Fast Fourier Transform (FFT) and capture fine-grained visual features of potential objects and broader context cues within traffic scenes. To capture a wider range of visual cues, we further propose a multi-layer fusion that dynamically computes the temporal dependencies between different scenes and iteratively updates the correlations between different visual features for accurate and timely accident prediction. Evaluated on real-world datasets--Dashcam Accident Dataset (DAD), Car Crash Dataset (CCD), and AnAn Accident Detection (A3D) datasets--our model surpasses existing top baselines in critical evaluation metrics like Average Precision (AP) and mean Time-To-Accident (mTTA). Importantly, its robustness and adaptability are particularly evident in challenging driving scenarios with missing or limited training data, demonstrating significant potential for application in real-world autonomous driving systems.
Towards Federated Domain Unlearning: Verification Methodologies and Challenges
Jun 05, 2024Federated Learning (FL) has evolved as a powerful tool for collaborative model training across multiple entities, ensuring data privacy in sensitive sectors such as healthcare and finance. However, the introduction of the Right to Be Forgotten (RTBF) poses new challenges, necessitating federated unlearning to delete data without full model retraining. Traditional FL unlearning methods, not originally designed with domain specificity in mind, inadequately address the complexities of multi-domain scenarios, often affecting the accuracy of models in non-targeted domains or leading to uniform forgetting across all domains. Our work presents the first comprehensive empirical study on Federated Domain Unlearning, analyzing the characteristics and challenges of current techniques in multi-domain contexts. We uncover that these methods falter, particularly because they neglect the nuanced influences of domain-specific data, which can lead to significant performance degradation and inaccurate model behavior. Our findings reveal that unlearning disproportionately affects the model's deeper layers, erasing critical representational subspaces acquired during earlier training phases. In response, we propose novel evaluation methodologies tailored for Federated Domain Unlearning, aiming to accurately assess and verify domain-specific data erasure without compromising the model's overall integrity and performance. This investigation not only highlights the urgent need for domain-centric unlearning strategies in FL but also sets a new precedent for evaluating and implementing these techniques effectively.
Breaking On-device Training Memory Wall: A Systematic Survey
Jun 17, 2023



On-device training has become an increasingly popular approach to machine learning, enabling models to be trained directly on mobile and edge devices. However, a major challenge in this area is the limited memory available on these devices, which can severely restrict the size and complexity of the models that can be trained. In this systematic survey, we aim to explore the current state-of-the-art techniques for breaking on-device training memory walls, focusing on methods that can enable larger and more complex models to be trained on resource-constrained devices. Specifically, we first analyze the key factors that contribute to the phenomenon of memory walls encountered during on-device training. Then, we present a comprehensive literature review of on-device training, which addresses the issue of memory limitations. Finally, we summarize on-device training and highlight the open problems for future research. By providing a comprehensive overview of these techniques and their effectiveness in breaking memory walls, we hope to help researchers and practitioners in this field navigate the rapidly evolving landscape of on-device training.