 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on Federated Fine-tuning of Large Language Models
Mar 15, 2025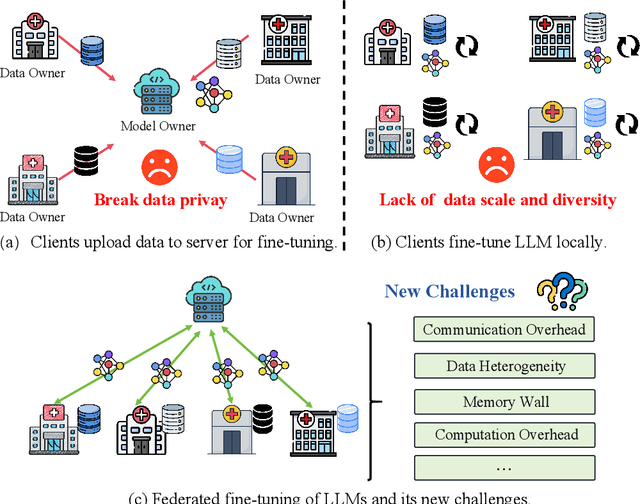
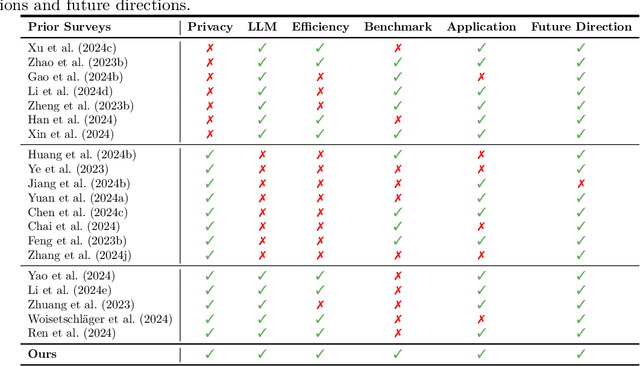
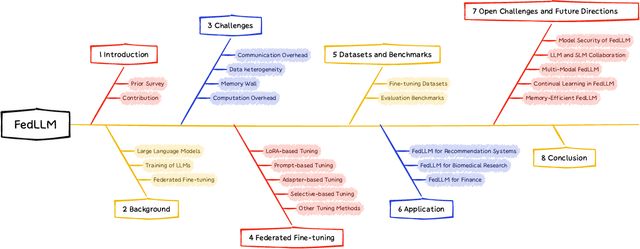

Large Language Models (LLMs) have achieved remarkable success across a wide range of tasks, with fine-tuning playing a pivotal role in adapting them to specific downstream applications. Federated Learning (FL) offers a promising approach that enables collaborative model adaptation while ensuring data privacy, i.e., FedLLM. In this survey, we provide a systematic and thorough review of the integration of LLMs with FL. Specifically, we first trace the historical evolution of both LLMs and FL, while summarizing relevant prior surveys. We then present an in-depth analysis of the fundamental challenges encountered in deploying FedLLM. Following this, we conduct an extensive study of existing parameter-efficient fine-tuning (PEFT) methods and explore their applicability in FL. Furthermore, we introduce a comprehensive evaluation benchmark to rigorously assess FedLLM performance and discuss its diverse real-world applications across multiple domains. Finally, we identify critical open challenges and outline promising research directions to drive future advancements in FedLLM. We maintain an active \href{https://github.com/Clin0212/Awesome-Federated-LLM-Learning}{GitHub repository} tracking cutting-edge advancements. This survey serves as a foundational resource for researchers and practitioners, offering insights into the evolving landscape of federated fine-tuning for LLMs while guiding future innovations in privacy-preserving AI.
Heterogeneity-Aware Coordination for Federated Learning via Stitching Pre-trained blocks
Sep 11, 2024



Federated learning (FL) coordinates multiple devices to collaboratively train a shared model while preserving data privacy. However, large memory footprint and high energy consumption during the training process excludes the low-end devices from contributing to the global model with their own data, which severely deteriorates the model performance in real-world scenarios. In this paper, we propose FedStitch, a hierarchical coordination framework for heterogeneous federated learning with pre-trained blocks. Unlike the traditional approaches that train the global model from scratch, for a new task, FedStitch composes the global model via stitching pre-trained blocks. Specifically, each participating client selects the most suitable block based on their local data from the candidate pool composed of blocks from pre-trained models. The server then aggregates the optimal block for stitching. This process iterates until a new stitched network is generated. Except for the new training paradigm, FedStitch consists of the following three core components: 1) an RL-weighted aggregator, 2) a search space optimizer deployed on the server side, and 3) a local energy optimizer deployed on each participating client. The RL-weighted aggregator helps to select the right block in the non-IID scenario, while the search space optimizer continuously reduces the size of the candidate block pool during stitching. Meanwhile, the local energy optimizer is designed to minimize energy consumption of each client while guaranteeing the overall training progress. The results demonstrate that compared to existing approaches, FedStitch improves the model accuracy up to 20.93%. At the same time, it achieves up to 8.12% speedup, reduces the memory footprint up to 79.5%, and achieves 89.41% energy saving at most during the learning procedure.
Breaking the Memory Wall for Heterogeneous Federated Learning with Progressive Training
Apr 20, 2024This paper presents ProFL, a novel progressive FL framework to effectively break the memory wall. Specifically, ProFL divides the model into different blocks based on its original architecture. Instead of updating the full model in each training round, ProFL first trains the front blocks and safely freezes them after convergence. Training of the next block is then triggered. This process iterates until the training of the whole model is completed. In this way, the memory footprint is effectively reduced for feasible deployment on heterogeneous devices. In order to preserve the feature representation of each block, we decouple the whole training process into two stages: progressive model shrinking and progressive model growing. During the progressive model shrinking stage, we meticulously design corresponding output modules to assist each block in learning the expected feature representation and obtain the initialization parameters. Then, the obtained output modules are utilized in the corresponding progressive model growing stage. Additionally, to control the training pace for each block, a novel metric from the scalar perspective is proposed to assess the learning status of each block and determines when to trigger the training of the next one. Finally, we theoretically prove the convergence of ProFL and conduct extensive experiments on representative models and datasets to evaluate the effectiveness of ProFL. The results demonstrate that ProFL effectively reduces the peak memory footprint by up to 57.4% and improves model accuracy by up to 82.4%.