 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-Driven Scenario-Aware Planning for Autonomous Driving
Jan 29, 2026Hybrid planner switching framework (HPSF) for autonomous driving needs to reconcile high-speed driving efficiency with safe maneuvering in dense traffic. Existing HPSF methods often fail to make reliable mode transitions or sustain efficient driving in congested environments, owing to heuristic scene recognition and low-frequency control updates. To address the limitation, this paper proposes LAP, a large language model (LLM) driven, adaptive planning method, which switches between high-speed driving in low-complexity scenes and precise driving in high-complexity scenes, enabling high qualities of trajectory generation through confined gaps. This is achieved by leveraging LLM for scene understanding and integrating its inference into the joint optimization of mode configuration and motion planning. The joint optimization is solved using tree-search model predictive control and alternating minimization. We implement LAP by Python in Robot Operating System (ROS). High-fidelity simulation results show that the proposed LAP outperforms other benchmarks in terms of both driving time and success rate.
Planning Oriented Integrated Sensing and Communication
Oct 27, 2025Integrated sensing and communication (ISAC) enables simultaneous localization, environment perception, and data exchange for connected autonomous vehicles. However, most existing ISAC designs prioritize sensing accuracy and communication throughput, treating all targets uniformly and overlooking the impact of critical obstacles on motion efficiency. To overcome this limitation, we propose a planning-oriented ISAC (PISAC) framework that reduces the sensing uncertainty of planning-bottleneck obstacles and expands the safe navigable path for the ego-vehicle, thereby bridging the gap between physical-layer optimization and motion-level planning. The core of PISAC lies in deriving a closed-form safety bound that explicitly links ISAC transmit power to sensing uncertainty, based on the Cram\'er-Rao Bound and occupancy inflation principles. Using this model, we formulate a bilevel power allocation and motion planning (PAMP) problem, where the inner layer optimizes the ISAC beam power distribution and the outer layer computes a collision-free trajectory under uncertainty-aware safety constraints. Comprehensive simulations in high-fidelity urban driving environments demonstrate that PISAC achieves up to 40% higher success rates and over 5% shorter traversal times than existing ISAC-based and communication-oriented benchmarks, validating its effectiveness in enhancing both safety and efficiency.
Edge Collaborative Gaussian Splatting with Integrated Rendering and Communication
Oct 26, 2025Gaussian splatting (GS) struggles with degraded rendering quality on low-cost devices. To address this issue, we present edge collaborative GS (ECO-GS), where each user can switch between a local small GS model to guarantee timeliness and a remote large GS model to guarantee fidelity. However, deciding how to engage the large GS model is nontrivial, due to the interdependency between rendering requirements and resource conditions. To this end, we propose integrated rendering and communication (IRAC), which jointly optimizes collaboration status (i.e., deciding whether to engage large GS) and edge power allocation (i.e., enabling remote rendering) under communication constraints across different users by minimizing a newly-derived GS switching function. Despite the nonconvexity of the problem, we propose an efficient penalty majorization minimization (PMM) algorithm to obtain the critical point solution. Furthermore, we develop an imitation learning optimization (ILO) algorithm, which reduces the computational time by over 100x compared to PMM. Experiments demonstrate the superiority of PMM and the real-time execution capability of ILO.
Communication Efficient Robotic Mixed Reality with Gaussian Splatting Cross-Layer Optimization
Aug 12, 2025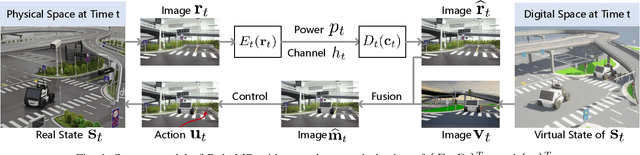
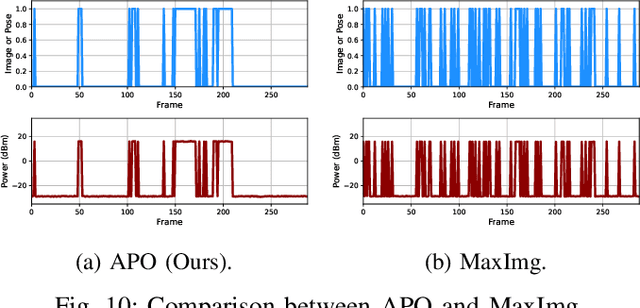
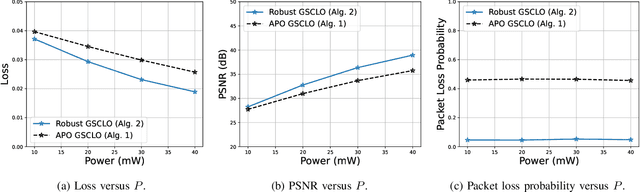
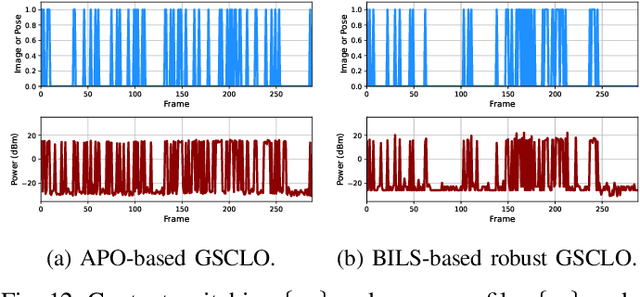
Realizing low-cost communication in robotic mixed reality (RoboMR) systems presents a challenge, due to the necessity of uploading high-resolution images through wireless channels. This paper proposes Gaussian splatting (GS) RoboMR (GSMR), which enables the simulator to opportunistically render a photo-realistic view from the robot's pose by calling ``memory'' from a GS model, thus reducing the need for excessive image uploads. However, the GS model may involve discrepancies compared to the actual environments. To this end, a GS cross-layer optimization (GSCLO) framework is further proposed, which jointly optimizes content switching (i.e., deciding whether to upload image or not) and power allocation (i.e., adjusting to content profiles) across different frames by minimizing a newly derived GSMR loss function. The GSCLO problem is addressed by an accelerated penalty optimization (APO) algorithm that reduces computational complexity by over $10$x compared to traditional branch-and-bound and search algorithms. Moreover, variants of GSCLO are presented to achieve robust, low-power, and multi-robot GSMR. Extensive experiments demonstrate that the proposed GSMR paradigm and GSCLO method achieve significant improvements over existing benchmarks on both wheeled and legged robots in terms of diverse metrics in various scenarios. For the first time, it is found that RoboMR can be achieved with ultra-low communication costs, and mixture of data is useful for enhancing GS performance in dynamic scenarios.
Towards Human-Like Trajectory Prediction for Autonomous Driving: A Behavior-Centric Approach
May 27, 2025



Predicting the trajectories of vehicles is crucial for the development of autonomous driving (AD) systems, particularly in complex and dynamic traffic environments. In this study, we introduce HiT (Human-like Trajectory Prediction), a novel model designed to enhance trajectory prediction by incorporating behavior-aware modules and dynamic centrality measures. Unlike traditional methods that primarily rely on static graph structures, HiT leverages a dynamic framework that accounts for both direct and indirect interactions among traffic participants. This allows the model to capture the subtle yet significant influences of surrounding vehicles, enabling more accurate and human-like predictions. To evaluate HiT's performance, we conducted extensive experiments using diverse and challenging real-world datasets, including NGSIM, HighD, RounD, ApolloScape, and MoCAD++. The results demonstrate that HiT consistently outperforms other top models across multiple metrics, particularly excelling in scenarios involving aggressive driving behaviors. This research presents a significant step forward in trajectory prediction, offering a more reliable and interpretable approach for enhancing the safety and efficiency of fully autonomous driving systems.
Beyond Patterns: Harnessing Causal Logic for Autonomous Driving Trajectory Prediction
May 11, 2025Accurate trajectory prediction has long been a major challenge for autonomous driving (AD). Traditional data-driven models predominantly rely on statistical correlations, often overlooking the causal relationships that govern traffic behavior. In this paper, we introduce a novel trajectory prediction framework that leverages causal inference to enhance predictive robustness, generalization, and accuracy. By decomposing the environment into spatial and temporal components, our approach identifies and mitigates spurious correlations, uncovering genuine causal relationships. We also employ a progressive fusion strategy to integrate multimodal information, simulating human-like reasoning processes and enabling real-time inference. Evaluations on five real-world datasets--ApolloScape, nuScenes, NGSIM, HighD, and MoCAD--demonstrate our model's superiority over existing state-of-the-art (SOTA) methods, with improvements in key metrics such as RMSE and FDE. Our findings highlight the potential of causal reasoning to transform trajectory prediction, paving the way for robust AD systems.
Opportunistic Collaborative Planning with Large Vision Model Guided Control and Joint Query-Service Optimization
Apr 25, 2025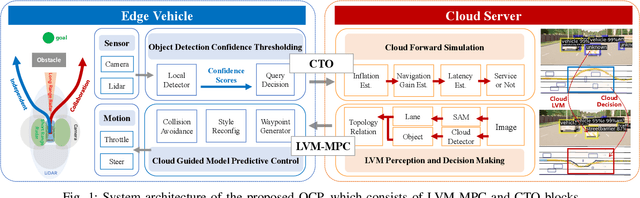
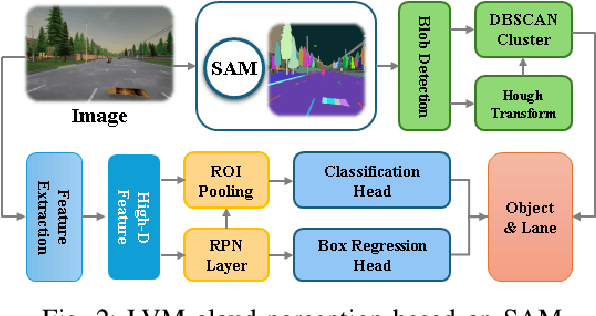
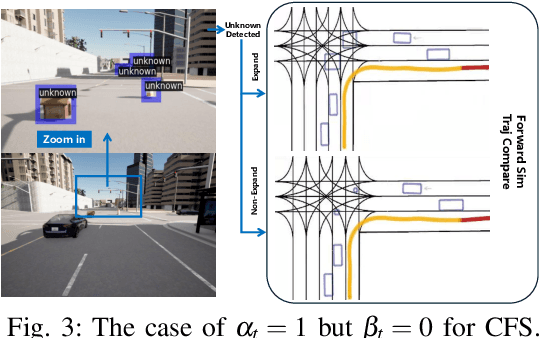
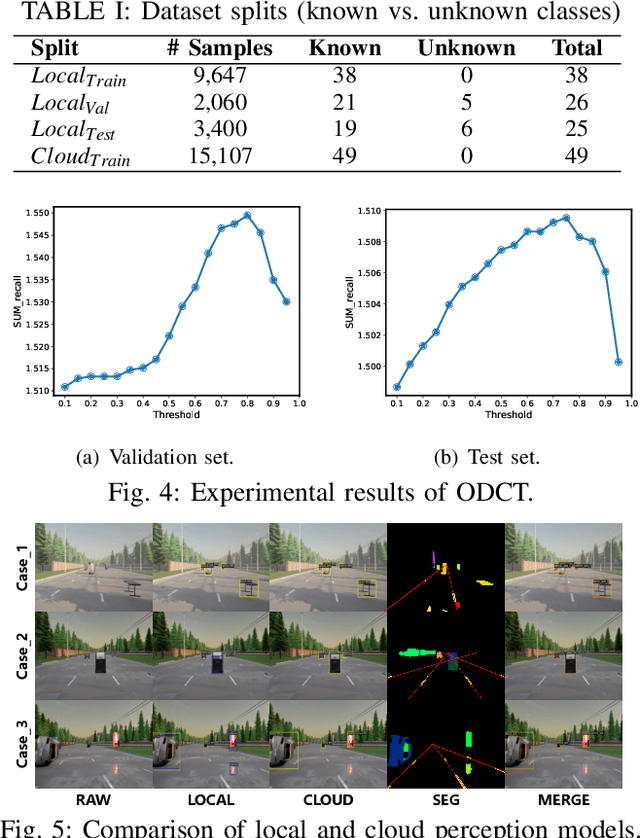
Navigating autonomous vehicles in open scenarios is a challenge due to the difficulties in handling unseen objects. Existing solutions either rely on small models that struggle with generalization or large models that are resource-intensive. While collaboration between the two offers a promising solution, the key challenge is deciding when and how to engage the large model. To address this issue, this paper proposes opportunistic collaborative planning (OCP), which seamlessly integrates efficient local models with powerful cloud models through two key innovations. First, we propose large vision model guided model predictive control (LVM-MPC), which leverages the cloud for LVM perception and decision making. The cloud output serves as a global guidance for a local MPC, thereby forming a closed-loop perception-to-control system. Second, to determine the best timing for large model query and service, we propose collaboration timing optimization (CTO), including object detection confidence thresholding (ODCT) and cloud forward simulation (CFS), to decide when to seek cloud assistance and when to offer cloud service. Extensive experiments show that the proposed OCP outperforms existing methods in terms of both navigation time and success rate.
Green Robotic Mixed Reality with Gaussian Splatting
Apr 18, 2025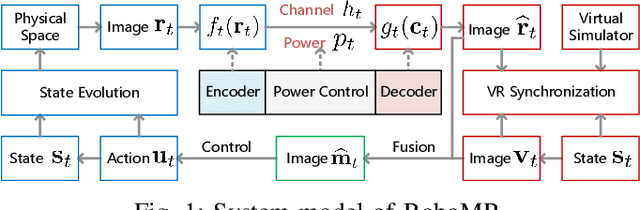

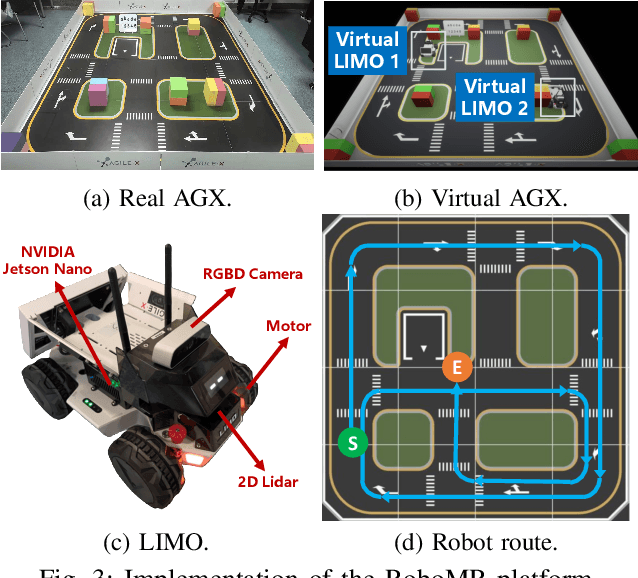
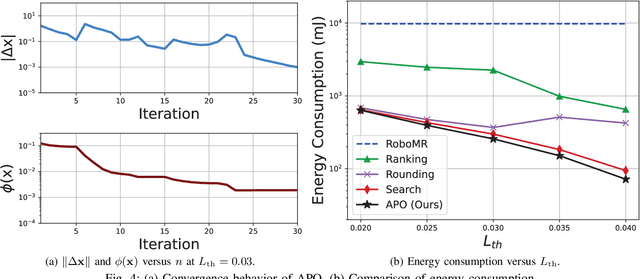
Realizing green communication in robotic mixed reality (RoboMR) systems presents a challenge, due to the necessity of uploading high-resolution images at high frequencies through wireless channels. This paper proposes Gaussian splatting (GS) RoboMR (GSRMR), which achieves a lower energy consumption and makes a concrete step towards green RoboMR. The crux to GSRMR is to build a GS model which enables the simulator to opportunistically render a photo-realistic view from the robot's pose, thereby reducing the need for excessive image uploads. Since the GS model may involve discrepancies compared to the actual environments, a GS cross-layer optimization (GSCLO) framework is further proposed, which jointly optimizes content switching (i.e., deciding whether to upload image or not) and power allocation across different frames. The GSCLO problem is solved by an accelerated penalty optimization (APO) algorithm. Experiments demonstrate that the proposed GSRMR reduces the communication energy by over 10x compared with RoboMR. Furthermore, the proposed GSRMR with APO outperforms extensive baseline schemes, in terms of peak signal-to-noise ratio (PSNR) and structural similarity index measure (SSIM).
TransMamba: Flexibly Switching between Transformer and Mamba
Mar 31, 2025Transformers are the cornerstone of modern large language models, but their quadratic computational complexity limits efficiency in long-sequence processing. Recent advancements in Mamba, a state space model (SSM) with linear complexity, offer promising efficiency gains but suffer from unstable contextual learning and multitask generalization. This paper proposes TransMamba, a novel framework that unifies Transformer and Mamba through shared parameter matrices (e.g., QKV and CBx), and thus could dynamically switch between attention and SSM mechanisms at different token lengths and layers. We design the Memory converter to bridge Transformer and Mamba by converting attention outputs into SSM-compatible states, ensuring seamless information flow at TransPoints where the transformation happens. The TransPoint scheduling is also thoroughly explored for further improvements. We conducted extensive experiments demonstrating that TransMamba achieves superior training efficiency and performance compared to baselines, and validated the deeper consistency between Transformer and Mamba paradigms, offering a scalable solution for next-generation sequence modeling.
FLIP: Towards Comprehensive and Reliable Evaluation of Federated Prompt Learning
Mar 28, 2025The increasing emphasis on privacy and data security has driven the adoption of federated learning, a decentralized approach to train machine learning models without sharing raw data. Prompt learning, which fine-tunes prompt embeddings of pretrained models, offers significant advantages in federated settings by reducing computational costs and communication overheads while leveraging the strong performance and generalization capabilities of vision-language models such as CLIP. This paper addresses the intersection of federated learning and prompt learning, particularly for vision-language models. In this work, we introduce a comprehensive framework, named FLIP, to evaluate federated prompt learning algorithms. FLIP assesses the performance of 8 state-of-the-art federated prompt learning methods across 4 federated learning protocols and 12 open datasets, considering 6 distinct evaluation scenarios. Our findings demonstrate that prompt learning maintains strong generalization performance in both in-distribution and out-of-distribution settings with minimal resource consumption. This work highlights the effectiveness of federated prompt learning in environments characterized by data scarcity, unseen classes, and cross-domain distributional shifts. We open-source the code for all implemented algorithms in FLIP to facilitate further research in this domain.