 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOneMall: One Architecture, More Scenarios -- End-to-End Generative Recommender Family at Kuaishou E-Commerce
Feb 02, 2026In the wave of generative recommendation, we present OneMall, an end-to-end generative recommendation framework tailored for e-commerce services at Kuaishou. Our OneMall systematically unifies the e-commerce's multiple item distribution scenarios, such as Product-card, short-video and live-streaming. Specifically, it comprises three key components, aligning the entire model training pipeline to the LLM's pre-training/post-training: (1) E-commerce Semantic Tokenizer: we provide a tokenizer solution that captures both real-world semantics and business-specific item relations across different scenarios; (2) Transformer-based Architecture: we largely utilize Transformer as our model backbone, e.g., employing Query-Former for long sequence compression, Cross-Attention for multi-behavior sequence fusion, and Sparse MoE for scalable auto-regressive generation; (3) Reinforcement Learning Pipeline: we further connect retrieval and ranking models via RL, enabling the ranking model to serve as a reward signal for end-to-end policy retrieval model optimization. Extensive experiments demonstrate that OneMall achieves consistent improvements across all e-commerce scenarios: +13.01\% GMV in product-card, +15.32\% Orders in Short-Video, and +2.78\% Orders in Live-Streaming. OneMall has been deployed, serving over 400 million daily active users at Kuaishou.
OneMall: One Model, More Scenarios -- End-to-End Generative Recommender Family at Kuaishou E-Commerce
Jan 29, 2026In the wave of generative recommendation, we present OneMall, an end-to-end generative recommendation framework tailored for e-commerce services at Kuaishou. Our OneMall systematically unifies the e-commerce's multiple item distribution scenarios, such as Product-card, short-video and live-streaming. Specifically, it comprises three key components, aligning the entire model training pipeline to the LLM's pre-training/post-training: (1) E-commerce Semantic Tokenizer: we provide a tokenizer solution that captures both real-world semantics and business-specific item relations across different scenarios; (2) Transformer-based Architecture: we largely utilize Transformer as our model backbone, e.g., employing Query-Former for long sequence compression, Cross-Attention for multi-behavior sequence fusion, and Sparse MoE for scalable auto-regressive generation; (3) Reinforcement Learning Pipeline: we further connect retrieval and ranking models via RL, enabling the ranking model to serve as a reward signal for end-to-end policy retrieval model optimization. Extensive experiments demonstrate that OneMall achieves consistent improvements across all e-commerce scenarios: +13.01\% GMV in product-card, +15.32\% Orders in Short-Video, and +2.78\% Orders in Live-Streaming. OneMall has been deployed, serving over 400 million daily active users at Kuaishou.
Super LiDAR Reflectance for Robotic Perception
Aug 14, 2025Conventionally, human intuition often defines vision as a modality of passive optical sensing, while active optical sensing is typically regarded as measuring rather than the default modality of vision. However, the situation now changes: sensor technologies and data-driven paradigms empower active optical sensing to redefine the boundaries of vision, ushering in a new era of active vision. Light Detection and Ranging (LiDAR) sensors capture reflectance from object surfaces, which remains invariant under varying illumination conditions, showcasing significant potential in robotic perception tasks such as detection, recognition, segmentation, and Simultaneous Localization and Mapping (SLAM). These applications often rely on dense sensing capabilities, typically achieved by high-resolution, expensive LiDAR sensors. A key challenge with low-cost LiDARs lies in the sparsity of scan data, which limits their broader application. To address this limitation, this work introduces an innovative framework for generating dense LiDAR reflectance images from sparse data, leveraging the unique attributes of non-repeating scanning LiDAR (NRS-LiDAR). We tackle critical challenges, including reflectance calibration and the transition from static to dynamic scene domains, facilitating the reconstruction of dense reflectance images in real-world settings. The key contributions of this work include a comprehensive dataset for LiDAR reflectance image densification, a densification network tailored for NRS-LiDAR, and diverse applications such as loop closure and traffic lane detection using the generated dense reflectance images.
High-Fidelity Differential-information Driven Binary Vision Transformer
Jul 03, 2025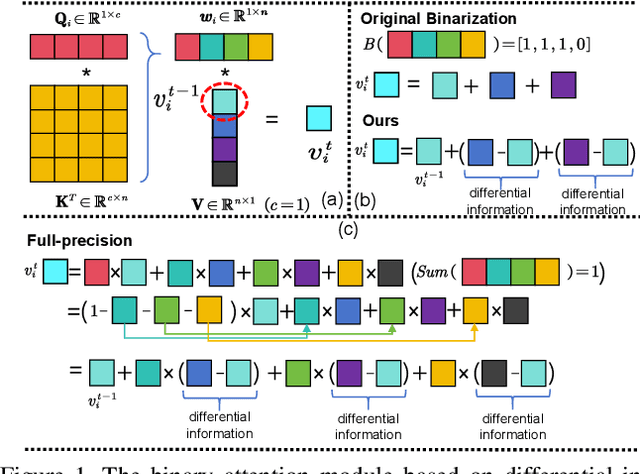
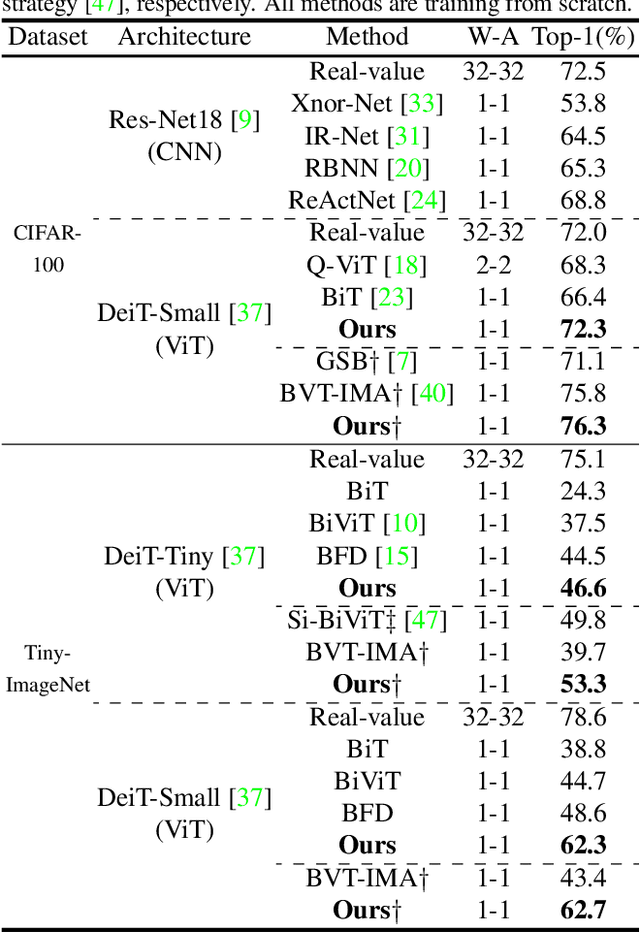
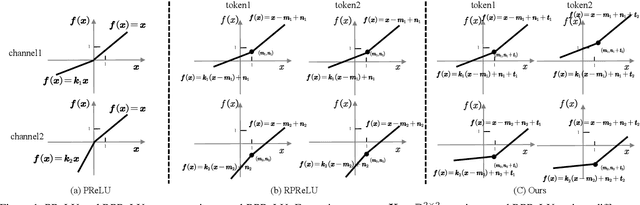

The binarization of vision transformers (ViTs) offers a promising approach to addressing the trade-off between high computational/storage demands and the constraints of edge-device deployment. However, existing binary ViT methods often suffer from severe performance degradation or rely heavily on full-precision modules. To address these issues, we propose DIDB-ViT, a novel binary ViT that is highly informative while maintaining the original ViT architecture and computational efficiency. Specifically, we design an informative attention module incorporating differential information to mitigate information loss caused by binarization and enhance high-frequency retention. To preserve the fidelity of the similarity calculations between binary Q and K tensors, we apply frequency decomposition using the discrete Haar wavelet and integrate similarities across different frequencies. Additionally, we introduce an improved RPReLU activation function to restructure the activation distribution, expanding the model's representational capacity. Experimental results demonstrate that our DIDB-ViT significantly outperforms state-of-the-art network quantization methods in multiple ViT architectures, achieving superior image classification and segmentation performance.
TS-Diff: Two-Stage Diffusion Model for Low-Light RAW Image Enhancement
May 07, 2025This paper presents a novel Two-Stage Diffusion Model (TS-Diff) for enhancing extremely low-light RAW images. In the pre-training stage, TS-Diff synthesizes noisy images by constructing multiple virtual cameras based on a noise space. Camera Feature Integration (CFI) modules are then designed to enable the model to learn generalizable features across diverse virtual cameras. During the aligning stage, CFIs are averaged to create a target-specific CFI$^T$, which is fine-tuned using a small amount of real RAW data to adapt to the noise characteristics of specific cameras. A structural reparameterization technique further simplifies CFI$^T$ for efficient deployment. To address color shifts during the diffusion process, a color corrector is introduced to ensure color consistency by dynamically adjusting global color distributions. Additionally, a novel dataset, QID, is constructed, featuring quantifiable illumination levels and a wide dynamic range, providing a comprehensive benchmark for training and evaluation under extreme low-light conditions. Experimental results demonstrate that TS-Diff achieves state-of-the-art performance on multiple datasets, including QID, SID, and ELD, excelling in denoising, generalization, and color consistency across various cameras and illumination levels. These findings highlight the robustness and versatility of TS-Diff, making it a practical solution for low-light imaging applications. Source codes and models are available at https://github.com/CircccleK/TS-Diff
HDiffTG: A Lightweight Hybrid Diffusion-Transformer-GCN Architecture for 3D Human Pose Estimation
May 07, 2025We propose HDiffTG, a novel 3D Human Pose Estimation (3DHPE) method that integrates Transformer, Graph Convolutional Network (GCN), and diffusion model into a unified framework. HDiffTG leverages the strengths of these techniques to significantly improve pose estimation accuracy and robustness while maintaining a lightweight design. The Transformer captures global spatiotemporal dependencies, the GCN models local skeletal structures, and the diffusion model provides step-by-step optimization for fine-tuning, achieving a complementary balance between global and local features. This integration enhances the model's ability to handle pose estimation under occlusions and in complex scenarios. Furthermore, we introduce lightweight optimizations to the integrated model and refine the objective function design to reduce computational overhead without compromising performance. Evaluation results on the Human3.6M and MPI-INF-3DHP datasets demonstrate that HDiffTG achieves state-of-the-art (SOTA) performance on the MPI-INF-3DHP dataset while excelling in both accuracy and computational efficiency. Additionally, the model exhibits exceptional robustness in noisy and occluded environments. Source codes and models are available at https://github.com/CirceJie/HDiffTG
BHViT: Binarized Hybrid Vision Transformer
Mar 05, 2025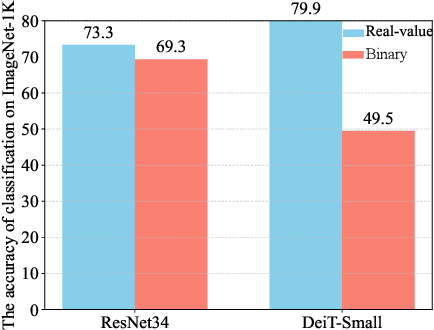
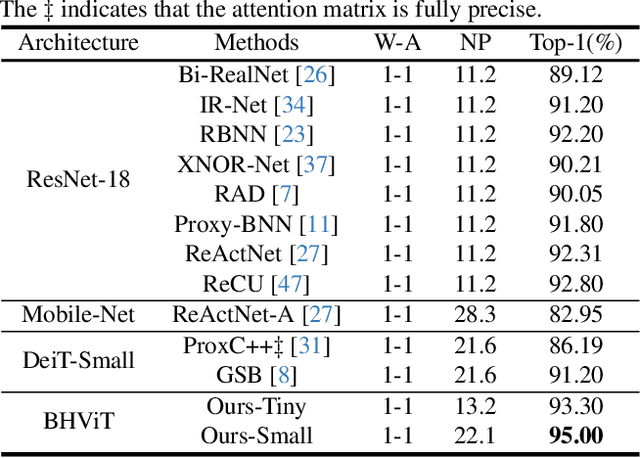
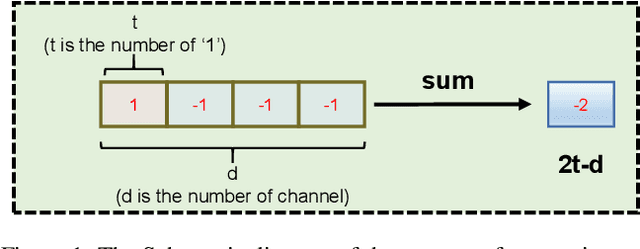

Model binarization has made significant progress in enabling real-time and energy-efficient computation for convolutional neural networks (CNN), offering a potential solution to the deployment challenges faced by Vision Transformers (ViTs) on edge devices. However, due to the structural differences between CNN and Transformer architectures, simply applying binary CNN strategies to the ViT models will lead to a significant performance drop. To tackle this challenge, we propose BHViT, a binarization-friendly hybrid ViT architecture and its full binarization model with the guidance of three important observations. Initially, BHViT utilizes the local information interaction and hierarchical feature aggregation technique from coarse to fine levels to address redundant computations stemming from excessive tokens. Then, a novel module based on shift operations is proposed to enhance the performance of the binary Multilayer Perceptron (MLP) module without significantly increasing computational overhead. In addition, an innovative attention matrix binarization method based on quantization decomposition is proposed to evaluate the token's importance in the binarized attention matrix. Finally, we propose a regularization loss to address the inadequate optimization caused by the incompatibility between the weight oscillation in the binary layers and the Adam Optimizer. Extensive experimental results demonstrate that our proposed algorithm achieves SOTA performance among binary ViT methods.
Night-Voyager: Consistent and Efficient Nocturnal Vision-Aided State Estimation in Object Maps
Feb 27, 2025
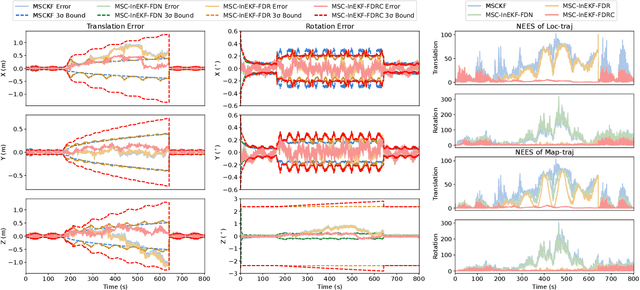
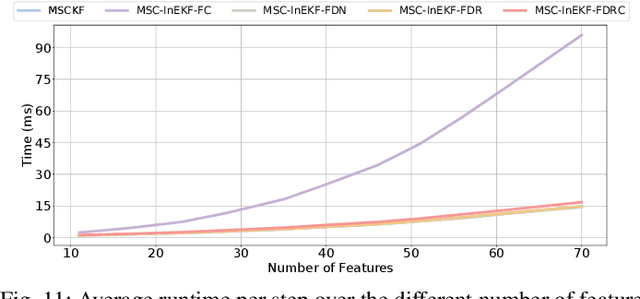

Accurate and robust state estimation at nighttime is essential for autonomous robotic navigation to achieve nocturnal or round-the-clock tasks. An intuitive question arises: Can low-cost standard cameras be exploited for nocturnal state estimation? Regrettably, most existing visual methods may fail under adverse illumination conditions, even with active lighting or image enhancement. A pivotal insight, however, is that streetlights in most urban scenarios act as stable and salient prior visual cues at night, reminiscent of stars in deep space aiding spacecraft voyage in interstellar navigation. Inspired by this, we propose Night-Voyager, an object-level nocturnal vision-aided state estimation framework that leverages prior object maps and keypoints for versatile localization. We also find that the primary limitation of conventional visual methods under poor lighting conditions stems from the reliance on pixel-level metrics. In contrast, metric-agnostic, non-pixel-level object detection serves as a bridge between pixel-level and object-level spaces, enabling effective propagation and utilization of object map information within the system. Night-Voyager begins with a fast initialization to solve the global localization problem. By employing an effective two-stage cross-modal data association, the system delivers globally consistent state updates using map-based observations. To address the challenge of significant uncertainties in visual observations at night, a novel matrix Lie group formulation and a feature-decoupled multi-state invariant filter are introduced, ensuring consistent and efficient estimation. Through comprehensive experiments in both simulation and diverse real-world scenarios (spanning approximately 12.3 km), Night-Voyager showcases its efficacy, robustness, and efficiency, filling a critical gap in nocturnal vision-aided state estimation.
Pathfinder for Low-altitude Aircraft with Binary Neural Network
Sep 13, 2024



A prior global topological map (e.g., the OpenStreetMap, OSM) can boost the performance of autonomous mapping by a ground mobile robot. However, the prior map is usually incomplete due to lacking labeling in partial paths. To solve this problem, this paper proposes an OSM maker using airborne sensors carried by low-altitude aircraft, where the core of the OSM maker is a novel efficient pathfinder approach based on LiDAR and camera data, i.e., a binary dual-stream road segmentation model. Specifically, a multi-scale feature extraction based on the UNet architecture is implemented for images and point clouds. To reduce the effect caused by the sparsity of point cloud, an attention-guided gated block is designed to integrate image and point-cloud features. For enhancing the efficiency of the model, we propose a binarization streamline to each model component, including a variant of vision transformer (ViT) architecture as the encoder of the image branch, and new focal and perception losses to optimize the model training. The experimental results on two datasets demonstrate that our pathfinder method achieves SOTA accuracy with high efficiency in finding paths from the low-level airborne sensors, and we can create complete OSM prior maps based on the segmented road skeletons. Code and data are available at:https://github.com/IMRL/Pathfinder}{https://github.com/IMRL/Pathfinder.
UMAD: University of Macau Anomaly Detection Benchmark Dataset
Aug 22, 2024



Anomaly detection is critical in surveillance systems and patrol robots by identifying anomalous regions in images for early warning. Depending on whether reference data are utilized, anomaly detection can be categorized into anomaly detection with reference and anomaly detection without reference. Currently, anomaly detection without reference, which is closely related to out-of-distribution (OoD) object detection, struggles with learning anomalous patterns due to the difficulty of collecting sufficiently large and diverse anomaly datasets with the inherent rarity and novelty of anomalies. Alternatively, anomaly detection with reference employs the scheme of change detection to identify anomalies by comparing semantic changes between a reference image and a query one. However, there are very few ADr works due to the scarcity of public datasets in this domain. In this paper, we aim to address this gap by introducing the UMAD Benchmark Dataset. To our best knowledge, this is the first benchmark dataset designed specifically for anomaly detection with reference in robotic patrolling scenarios, e.g., where an autonomous robot is employed to detect anomalous objects by comparing a reference and a query video sequences. The reference sequences can be taken by the robot along a specified route when there are no anomalous objects in the scene. The query sequences are captured online by the robot when it is patrolling in the same scene following the same route. Our benchmark dataset is elaborated such that each query image can find a corresponding reference based on accurate robot localization along the same route in the prebuilt 3D map, with which the reference and query images can be geometrically aligned using adaptive warping. Besides the proposed benchmark dataset, we evaluate the baseline models of ADr on this dataset.