 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNight-Voyager: Consistent and Efficient Nocturnal Vision-Aided State Estimation in Object Maps
Feb 27, 2025
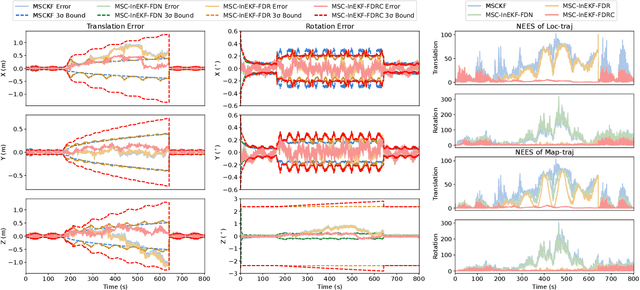
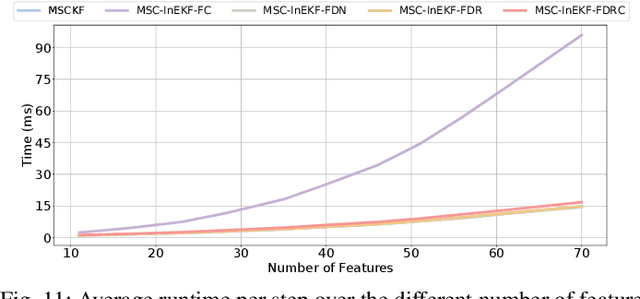

Accurate and robust state estimation at nighttime is essential for autonomous robotic navigation to achieve nocturnal or round-the-clock tasks. An intuitive question arises: Can low-cost standard cameras be exploited for nocturnal state estimation? Regrettably, most existing visual methods may fail under adverse illumination conditions, even with active lighting or image enhancement. A pivotal insight, however, is that streetlights in most urban scenarios act as stable and salient prior visual cues at night, reminiscent of stars in deep space aiding spacecraft voyage in interstellar navigation. Inspired by this, we propose Night-Voyager, an object-level nocturnal vision-aided state estimation framework that leverages prior object maps and keypoints for versatile localization. We also find that the primary limitation of conventional visual methods under poor lighting conditions stems from the reliance on pixel-level metrics. In contrast, metric-agnostic, non-pixel-level object detection serves as a bridge between pixel-level and object-level spaces, enabling effective propagation and utilization of object map information within the system. Night-Voyager begins with a fast initialization to solve the global localization problem. By employing an effective two-stage cross-modal data association, the system delivers globally consistent state updates using map-based observations. To address the challenge of significant uncertainties in visual observations at night, a novel matrix Lie group formulation and a feature-decoupled multi-state invariant filter are introduced, ensuring consistent and efficient estimation. Through comprehensive experiments in both simulation and diverse real-world scenarios (spanning approximately 12.3 km), Night-Voyager showcases its efficacy, robustness, and efficiency, filling a critical gap in nocturnal vision-aided state estimation.
Night-Rider: Nocturnal Vision-aided Localization in Streetlight Maps Using Invariant Extended Kalman Filtering
Feb 01, 2024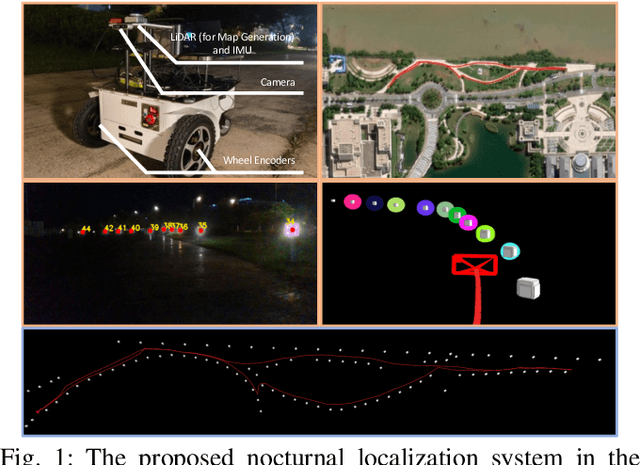
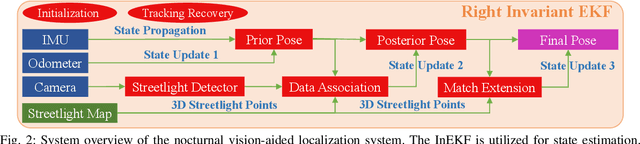
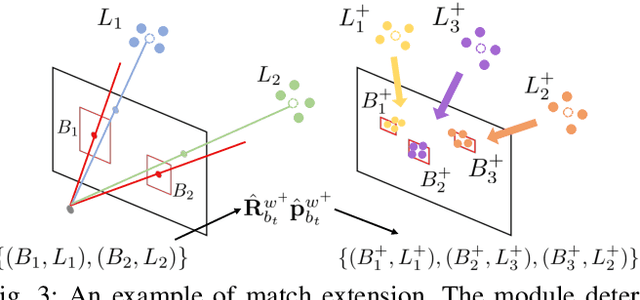
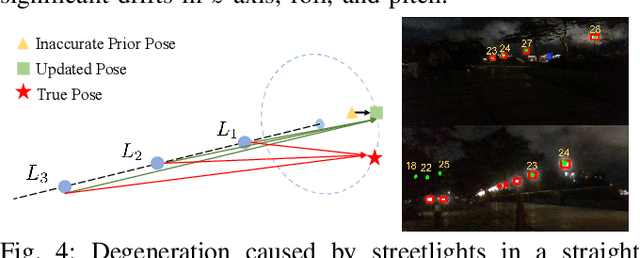
Vision-aided localization for low-cost mobile robots in diverse environments has attracted widespread attention recently. Although many current systems are applicable in daytime environments, nocturnal visual localization is still an open problem owing to the lack of stable visual information. An insight from most nocturnal scenes is that the static and bright streetlights are reliable visual information for localization. Hence we propose a nocturnal vision-aided localization system in streetlight maps with a novel data association and matching scheme using object detection methods. We leverage the Invariant Extended Kalman Filter (InEKF) to fuse IMU, odometer, and camera measurements for consistent state estimation at night. Furthermore, a tracking recovery module is also designed for tracking failures. Experiments on multiple real nighttime scenes validate that the system can achieve remarkably accurate and robust localization in nocturnal environments.
Spatio-Temporal Recurrent Networks for Event-Based Optical Flow Estimation
Sep 10, 2021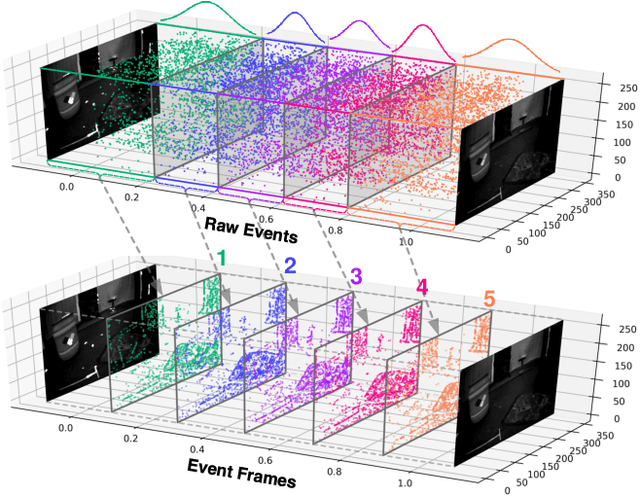
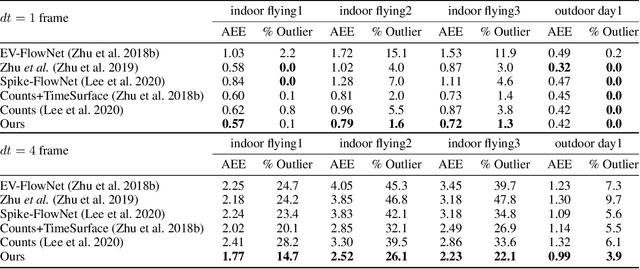
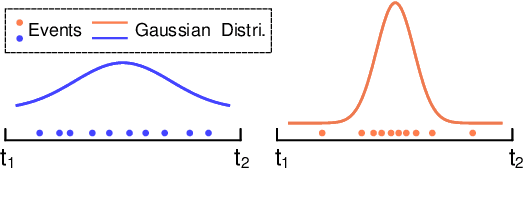
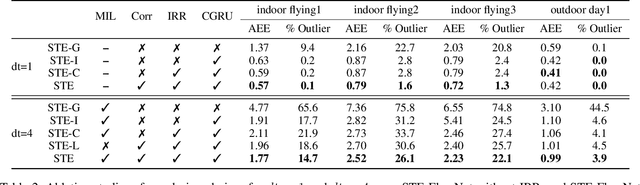
Event camera has offered promising alternative for visual perception, especially in high speed and high dynamic range scenes. Recently, many deep learning methods have shown great success in providing model-free solutions to many event-based problems, such as optical flow estimation. However, existing deep learning methods did not address the importance of temporal information well from the perspective of architecture design and cannot effectively extract spatio-temporal features. Another line of research that utilizes Spiking Neural Network suffers from training issues for deeper architecture. To address these points, a novel input representation is proposed that captures the events temporal distribution for signal enhancement. Moreover, we introduce a spatio-temporal recurrent encoding-decoding neural network architecture for event-based optical flow estimation, which utilizes Convolutional Gated Recurrent Units to extract feature maps from a series of event images. Besides, our architecture allows some traditional frame-based core modules, such as correlation layer and iterative residual refine scheme, to be incorporated. The network is end-to-end trained with self-supervised learning on the Multi-Vehicle Stereo Event Camera dataset. We have shown that it outperforms all the existing state-of-the-art methods by a large margin.
CI-Net: Contextual Information for Joint Semantic Segmentation and Depth Estimation
Jul 29, 2021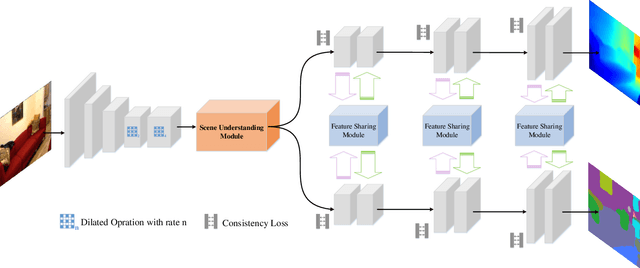
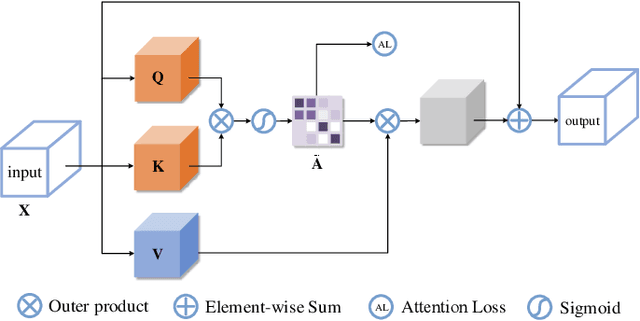
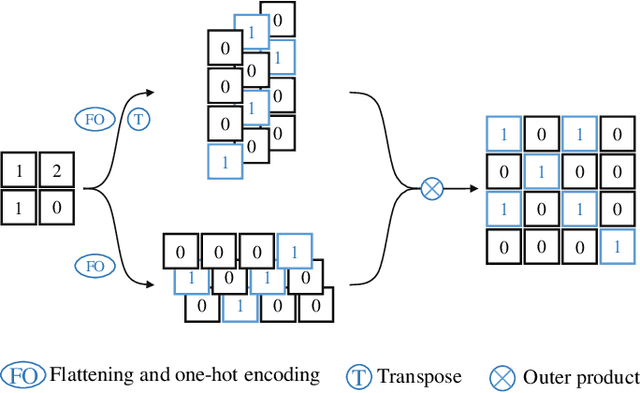
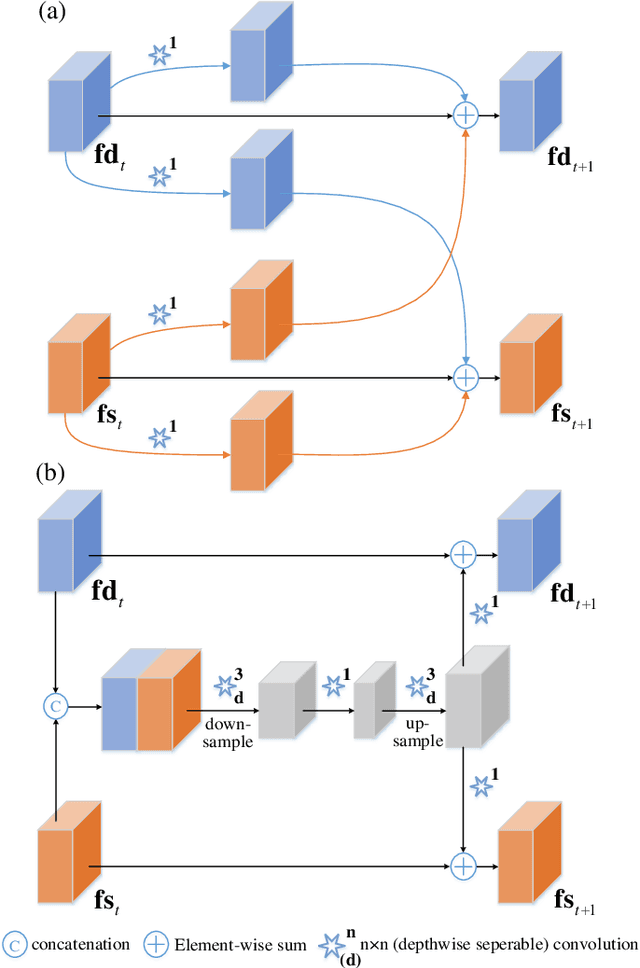
Monocular depth estimation and semantic segmentation are two fundamental goals of scene understanding. Due to the advantages of task interaction, many works study the joint task learning algorithm. However, most existing methods fail to fully leverage the semantic labels, ignoring the provided context structures and only using them to supervise the prediction of segmentation split. In this paper, we propose a network injected with contextual information (CI-Net) to solve the problem. Specifically, we introduce self-attention block in the encoder to generate attention map. With supervision from the ground truth created by semantic labels, the network is embedded with contextual information so that it could understand the scene better, utilizing dependent features to make accurate prediction. Besides, a feature sharing module is constructed to make the task-specific features deeply fused and a consistency loss is devised to make the features mutually guided. We evaluate the proposed CI-Net on the NYU-Depth-v2 and SUN-RGBD datasets. The experimental results validate that our proposed CI-Net is competitive with the state-of-the-arts.