 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Redundancy Regulation for Balanced Multimodal Information Refinement
Nov 14, 2025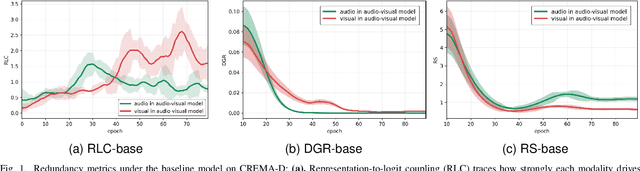
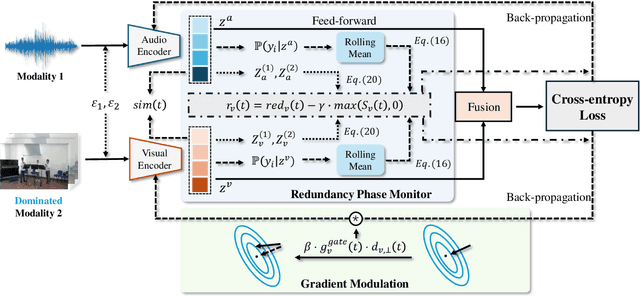
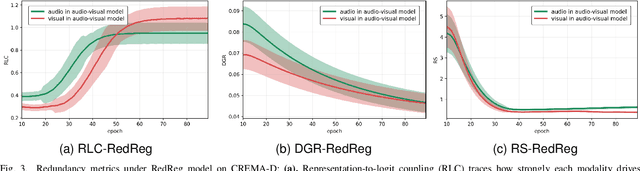
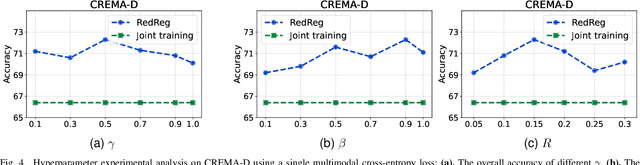
Multimodal learning aims to improve performance by leveraging data from multiple sources. During joint multimodal training, due to modality bias, the advantaged modality often dominates backpropagation, leading to imbalanced optimization. Existing methods still face two problems: First, the long-term dominance of the dominant modality weakens representation-output coupling in the late stages of training, resulting in the accumulation of redundant information. Second, previous methods often directly and uniformly adjust the gradients of the advantaged modality, ignoring the semantics and directionality between modalities. To address these limitations, we propose Adaptive Redundancy Regulation for Balanced Multimodal Information Refinement (RedReg), which is inspired by information bottleneck principle. Specifically, we construct a redundancy phase monitor that uses a joint criterion of effective gain growth rate and redundancy to trigger intervention only when redundancy is high. Furthermore, we design a co-information gating mechanism to estimate the contribution of the current dominant modality based on cross-modal semantics. When the task primarily relies on a single modality, the suppression term is automatically disabled to preserve modality-specific information. Finally, we project the gradient of the dominant modality onto the orthogonal complement of the joint multimodal gradient subspace and suppress the gradient according to redundancy. Experiments show that our method demonstrates superiority among current major methods in most scenarios. Ablation experiments verify the effectiveness of our method. The code is available at https://github.com/xia-zhe/RedReg.git
An End-to-End Room Geometry Constrained Depth Estimation Framework for Indoor Panorama Images
Oct 09, 2025Predicting spherical pixel depth from monocular $360^{\circ}$ indoor panoramas is critical for many vision applications. However, existing methods focus on pixel-level accuracy, causing oversmoothed room corners and noise sensitivity. In this paper, we propose a depth estimation framework based on room geometry constraints, which extracts room geometry information through layout prediction and integrates those information into the depth estimation process through background segmentation mechanism. At the model level, our framework comprises a shared feature encoder followed by task-specific decoders for layout estimation, depth estimation, and background segmentation. The shared encoder extracts multi-scale features, which are subsequently processed by individual decoders to generate initial predictions: a depth map, a room layout map, and a background segmentation map. Furthermore, our framework incorporates two strategies: a room geometry-based background depth resolving strategy and a background-segmentation-guided fusion mechanism. The proposed room-geometry-based background depth resolving strategy leverages the room layout and the depth decoder's output to generate the corresponding background depth map. Then, a background-segmentation-guided fusion strategy derives fusion weights for the background and coarse depth maps from the segmentation decoder's predictions. Extensive experimental results on the Stanford2D3D, Matterport3D and Structured3D datasets show that our proposed methods can achieve significantly superior performance than current open-source methods. Our code is available at https://github.com/emiyaning/RGCNet.
Spatio-Temporal Distortion Aware Omnidirectional Video Super-Resolution
Oct 15, 2024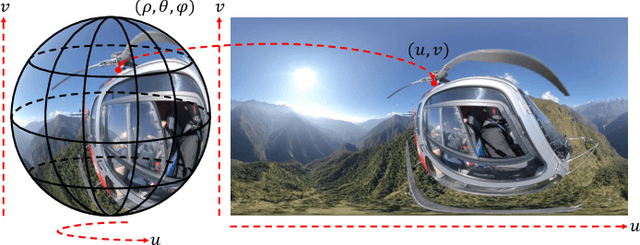


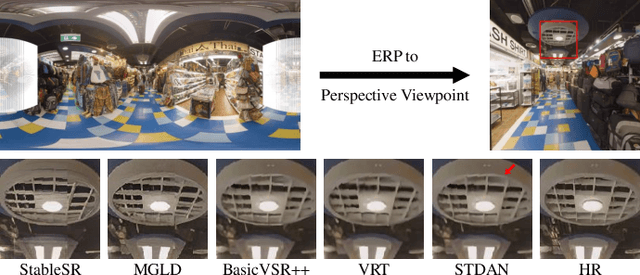
Omnidirectional video (ODV) can provide an immersive experience and is widely utilized in the field of virtual reality and augmented reality. However, the restricted capturing devices and transmission bandwidth lead to the low resolution of ODVs. Video super-resolution (VSR) methods are proposed to enhance the resolution of videos, but ODV projection distortions in the application are not well addressed directly applying such methods. To achieve better super-resolution reconstruction quality, we propose a novel Spatio-Temporal Distortion Aware Network (STDAN) oriented to ODV characteristics. Specifically, a spatio-temporal distortion modulation module is introduced to improve spatial ODV projection distortions and exploit the temporal correlation according to intra and inter alignments. Next, we design a multi-frame reconstruction and fusion mechanism to refine the consistency of reconstructed ODV frames. Furthermore, we incorporate latitude-saliency adaptive maps in the loss function to concentrate on important viewpoint regions with higher texture complexity and human-watching interest. In addition, we collect a new ODV-SR dataset with various scenarios. Extensive experimental results demonstrate that the proposed STDAN achieves superior super-resolution performance on ODVs and outperforms state-of-the-art methods.
Spiking Tucker Fusion Transformer for Audio-Visual Zero-Shot Learning
Jul 11, 2024

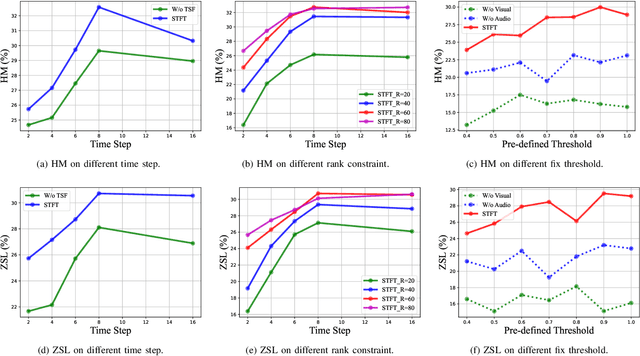
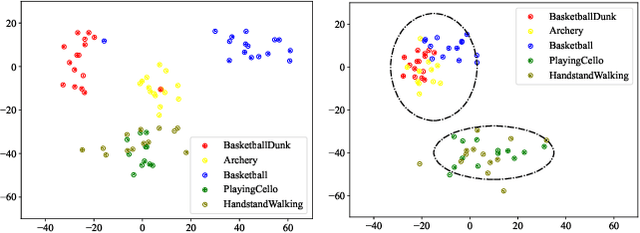
The spiking neural networks (SNNs) that efficiently encode temporal sequences have shown great potential in extracting audio-visual joint feature representations. However, coupling SNNs (binary spike sequences) with transformers (float-point sequences) to jointly explore the temporal-semantic information still facing challenges. In this paper, we introduce a novel Spiking Tucker Fusion Transformer (STFT) for audio-visual zero-shot learning (ZSL). The STFT leverage the temporal and semantic information from different time steps to generate robust representations. The time-step factor (TSF) is introduced to dynamically synthesis the subsequent inference information. To guide the formation of input membrane potentials and reduce the spike noise, we propose a global-local pooling (GLP) which combines the max and average pooling operations. Furthermore, the thresholds of the spiking neurons are dynamically adjusted based on semantic and temporal cues. Integrating the temporal and semantic information extracted by SNNs and Transformers are difficult due to the increased number of parameters in a straightforward bilinear model. To address this, we introduce a temporal-semantic Tucker fusion module, which achieves multi-scale fusion of SNN and Transformer outputs while maintaining full second-order interactions. Our experimental results demonstrate the effectiveness of the proposed approach in achieving state-of-the-art performance in three benchmark datasets. The harmonic mean (HM) improvement of VGGSound, UCF101 and ActivityNet are around 15.4\%, 3.9\%, and 14.9\%, respectively.
Unsupervised Optical Flow Estimation with Dynamic Timing Representation for Spike Camera
Jul 12, 2023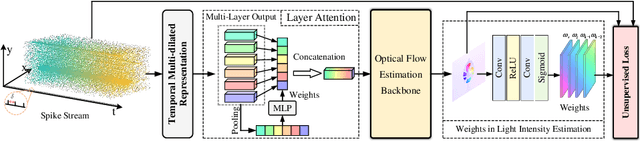
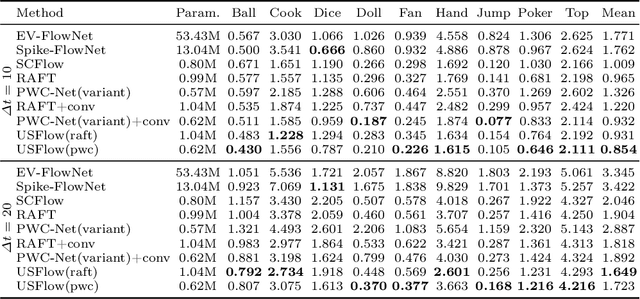
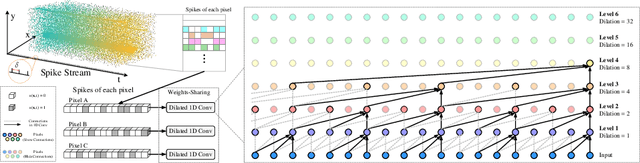
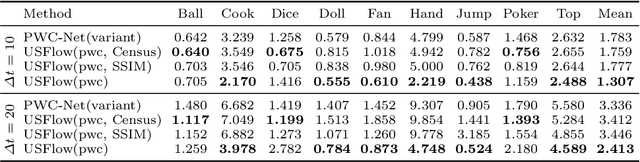
Efficiently selecting an appropriate spike stream data length to extract precise information is the key to the spike vision tasks. To address this issue, we propose a dynamic timing representation for spike streams. Based on multi-layers architecture, it applies dilated convolutions on temporal dimension to extract features on multi-temporal scales with few parameters. And we design layer attention to dynamically fuse these features. Moreover, we propose an unsupervised learning method for optical flow estimation in a spike-based manner to break the dependence on labeled data. In addition, to verify the robustness, we also build a spike-based synthetic validation dataset for extreme scenarios in autonomous driving, denoted as SSES dataset. It consists of various corner cases. Experiments show that our method can predict optical flow from spike streams in different high-speed scenes, including real scenes. For instance, our method gets $15\%$ and $19\%$ error reduction from the best spike-based work, SCFlow, in $\Delta t=10$ and $\Delta t=20$ respectively which are the same settings as the previous works.
MoWE: Mixture of Weather Experts for Multiple Adverse Weather Removal
Mar 24, 2023Currently, most adverse weather removal tasks are handled independently, such as deraining, desnowing, and dehazing. However, in autonomous driving scenarios, the type, intensity, and mixing degree of the weather are unknown, so the separated task setting cannot deal with these complex conditions well. Besides, the vision applications in autonomous driving often aim at high-level tasks, but existing weather removal methods neglect the connection between performance on perceptual tasks and signal fidelity. To this end, in upstream task, we propose a novel \textbf{Mixture of Weather Experts(MoWE)} Transformer framework to handle complex weather removal in a perception-aware fashion. We design a \textbf{Weather-aware Router} to make the experts targeted more relevant to weather types while without the need for weather type labels during inference. To handle diverse weather conditions, we propose \textbf{Multi-scale Experts} to fuse information among neighbor tokens. In downstream task, we propose a \textbf{Label-free Perception-aware Metric} to measure whether the outputs of image processing models are suitable for high level perception tasks without the demand for semantic labels. We collect a syntactic dataset \textbf{MAW-Sim} towards autonomous driving scenarios to benchmark the multiple weather removal performance of existing methods. Our MoWE achieves SOTA performance in upstream task on the proposed dataset and two public datasets, i.e. All-Weather and Rain/Fog-Cityscapes, and also have better perceptual results in downstream segmentation task compared to other methods. Our codes and datasets will be released after acceptance.
SpikeCV: Open a Continuous Computer Vision Era
Mar 21, 2023



SpikeCV is a new open-source computer vision platform for the spike camera, which is a neuromorphic visual sensor that has developed rapidly in recent years. In the spike camera, each pixel position directly accumulates the light intensity and asynchronously fires spikes. The output binary spikes can reach a frequency of 40,000 Hz. As a new type of visual expression, spike sequence has high spatiotemporal completeness and preserves the continuous visual information of the external world. Taking advantage of the low latency and high dynamic range of the spike camera, many spike-based algorithms have made significant progress, such as high-quality imaging and ultra-high-speed target detection. To build up a community ecology for the spike vision to facilitate more users to take advantage of the spike camera, SpikeCV provides a variety of ultra-high-speed scene datasets, hardware interfaces, and an easy-to-use modules library. SpikeCV focuses on encapsulation for spike data, standardization for dataset interfaces, modularization for vision tasks, and real-time applications for challenging scenes. With the advent of the open-source Python ecosystem, modules of SpikeCV can be used as a Python library to fulfilled most of the numerical analysis needs of researchers. We demonstrate the efficiency of the SpikeCV on offline inference and real-time applications. The project repository address are \url{https://openi.pcl.ac.cn/Cordium/SpikeCV} and \url{https://github.com/Zyj061/SpikeCV
Progressive Content-aware Coded Hyperspectral Compressive Imaging
Mar 17, 2023


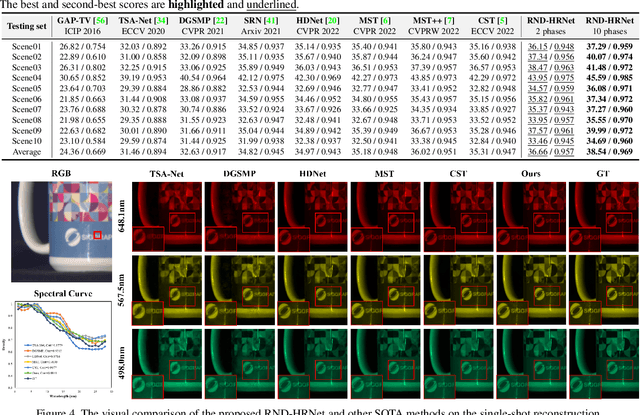
Hyperspectral imaging plays a pivotal role in a wide range of applications, like remote sensing, medicine, and cytology. By acquiring 3D hyperspectral images (HSIs) via 2D sensors, the coded aperture snapshot spectral imaging (CASSI) has achieved great success due to its hardware-friendly implementation and fast imaging speed. However, for some less spectrally sparse scenes, single snapshot and unreasonable coded aperture design tend to make HSI recovery more ill-posed and yield poor spatial and spectral fidelity. In this paper, we propose a novel Progressive Content-Aware CASSI framework, dubbed PCA-CASSI, which captures HSIs with multiple optimized content-aware coded apertures and fuses all the snapshots for reconstruction progressively. Simultaneously, by mapping the Range-Null space Decomposition (RND) into a deep network with several phases, an RND-HRNet is proposed for HSI recovery. Each recovery phase can fully exploit the hidden physical information in the coded apertures via explicit $\mathcal{R}$$-$$\mathcal{N}$ decomposition and explore the spatial-spectral correlation by dual transformer blocks. Our method is validated to surpass other state-of-the-art methods on both multiple- and single-shot HSI imaging tasks by large margins.
1000x Faster Camera and Machine Vision with Ordinary Devices
Jan 23, 2022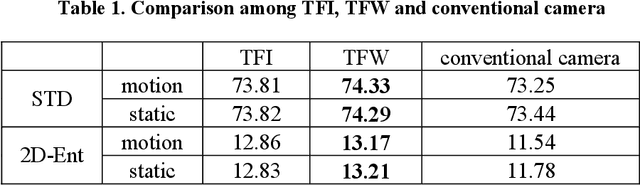


In digital cameras, we find a major limitation: the image and video form inherited from a film camera obstructs it from capturing the rapidly changing photonic world. Here, we present vidar, a bit sequence array where each bit represents whether the accumulation of photons has reached a threshold, to record and reconstruct the scene radiance at any moment. By employing only consumer-level CMOS sensors and integrated circuits, we have developed a vidar camera that is 1,000x faster than conventional cameras. By treating vidar as spike trains in biological vision, we have further developed a spiking neural network-based machine vision system that combines the speed of the machine and the mechanism of biological vision, achieving high-speed object detection and tracking 1,000x faster than human vision. We demonstrate the utility of the vidar camera and the super vision system in an assistant referee and target pointing system. Our study is expected to fundamentally revolutionize the image and video concepts and related industries, including photography, movies, and visual media, and to unseal a new spiking neural network-enabled speed-free machine vision era.
Contrastive and Selective Hidden Embeddings for Medical Image Segmentation
Jan 21, 2022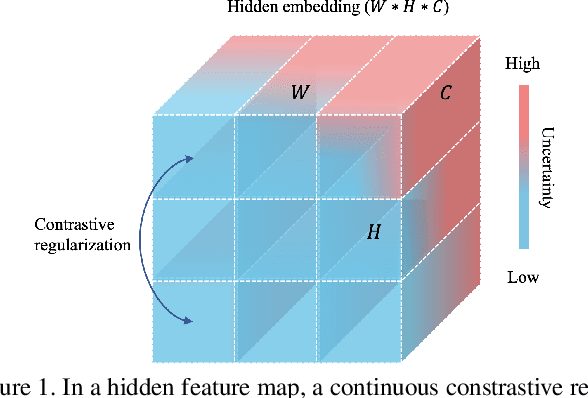
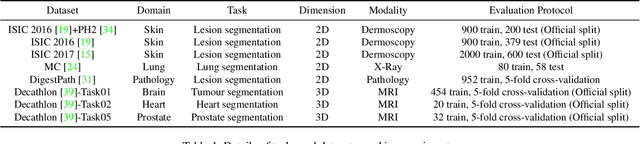
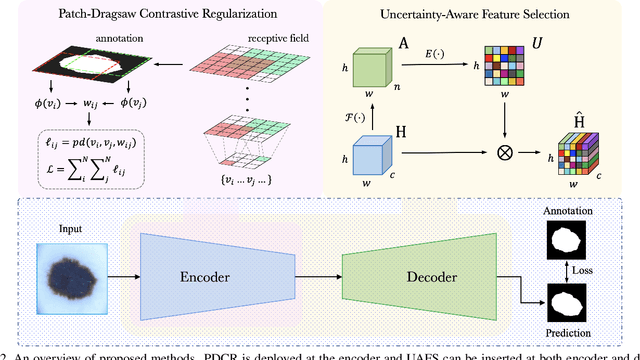
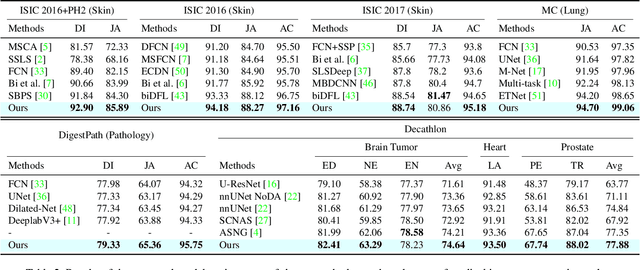
Medical image segmentation has been widely recognized as a pivot procedure for clinical diagnosis, analysis, and treatment planning. However, the laborious and expensive annotation process lags down the speed of further advances. Contrastive learning-based weight pre-training provides an alternative by leveraging unlabeled data to learn a good representation. In this paper, we investigate how contrastive learning benefits the general supervised medical segmentation tasks. To this end, patch-dragsaw contrastive regularization (PDCR) is proposed to perform patch-level tugging and repulsing with the extent controlled by a continuous affinity score. And a new structure dubbed uncertainty-aware feature selection block (UAFS) is designed to perform the feature selection process, which can handle the learning target shift caused by minority features with high uncertainty. By plugging the proposed 2 modules into the existing segmentation architecture, we achieve state-of-the-art results across 8 public datasets from 6 domains. Newly designed modules further decrease the amount of training data to a quarter while achieving comparable, if not better, performances. From this perspective, we take the opposite direction of the original self/un-supervised contrastive learning by further excavating information contained within the label.