 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecisionLLM: Large Language Models for Long Sequence Decision Exploration
Jan 15, 2026Long-sequence decision-making, which is usually addressed through reinforcement learning (RL), is a critical component for optimizing strategic operations in dynamic environments, such as real-time bidding in computational advertising. The Decision Transformer (DT) introduced a powerful paradigm by framing RL as an autoregressive sequence modeling problem. Concurrently, Large Language Models (LLMs) have demonstrated remarkable success in complex reasoning and planning tasks. This inspires us whether LLMs, which share the same Transformer foundation, but operate at a much larger scale, can unlock new levels of performance in long-horizon sequential decision-making problem. This work investigates the application of LLMs to offline decision making tasks. A fundamental challenge in this domain is the LLMs' inherent inability to interpret continuous values, as they lack a native understanding of numerical magnitude and order when values are represented as text strings. To address this, we propose treating trajectories as a distinct modality. By learning to align trajectory data with natural language task descriptions, our model can autoregressively predict future decisions within a cohesive framework we term DecisionLLM. We establish a set of scaling laws governing this paradigm, demonstrating that performance hinges on three factors: model scale, data volume, and data quality. In offline experimental benchmarks and bidding scenarios, DecisionLLM achieves strong performance. Specifically, DecisionLLM-3B outperforms the traditional Decision Transformer (DT) by 69.4 on Maze2D umaze-v1 and by 0.085 on AuctionNet. It extends the AIGB paradigm and points to promising directions for future exploration in online bidding.
Overcoming Joint Intractability with Lossless Hierarchical Speculative Decoding
Jan 09, 2026Verification is a key bottleneck in improving inference speed while maintaining distribution fidelity in Speculative Decoding. Recent work has shown that sequence-level verification leads to a higher number of accepted tokens compared to token-wise verification. However, existing solutions often rely on surrogate approximations or are constrained by partial information, struggling with joint intractability. In this work, we propose Hierarchical Speculative Decoding (HSD), a provably lossless verification method that significantly boosts the expected number of accepted tokens and overcomes joint intractability by balancing excess and deficient probability mass across accessible branches. Our extensive large-scale experiments demonstrate that HSD yields consistent improvements in acceptance rates across diverse model families and benchmarks. Moreover, its strong explainability and generality make it readily integrable into a wide range of speculative decoding frameworks. Notably, integrating HSD into EAGLE-3 yields over a 12% performance gain, establishing state-of-the-art decoding efficiency without compromising distribution fidelity. Code is available at https://github.com/ZhouYuxuanYX/Hierarchical-Speculative-Decoding.
SIGMA: Scalable Spectral Insights for LLM Collapse
Jan 06, 2026The rapid adoption of synthetic data for training Large Language Models (LLMs) has introduced the technical challenge of "model collapse"-a degenerative process where recursive training on model-generated content leads to a contraction of distributional variance and representational quality. While the phenomenology of collapse is increasingly evident, rigorous methods to quantify and predict its onset in high-dimensional spaces remain elusive. In this paper, we introduce SIGMA (Spectral Inequalities for Gram Matrix Analysis), a unified framework that benchmarks model collapse through the spectral lens of the embedding Gram matrix. By deriving and utilizing deterministic and stochastic bounds on the matrix's spectrum, SIGMA provides a mathematically grounded metric to track the contraction of the representation space. Crucially, our stochastic formulation enables scalable estimation of these bounds, making the framework applicable to large-scale foundation models where full eigendecomposition is intractable. We demonstrate that SIGMA effectively captures the transition towards degenerate states, offering both theoretical insights into the mechanics of collapse and a practical, scalable tool for monitoring the health of recursive training pipelines.
Self-Evaluation Unlocks Any-Step Text-to-Image Generation
Dec 26, 2025We introduce the Self-Evaluating Model (Self-E), a novel, from-scratch training approach for text-to-image generation that supports any-step inference. Self-E learns from data similarly to a Flow Matching model, while simultaneously employing a novel self-evaluation mechanism: it evaluates its own generated samples using its current score estimates, effectively serving as a dynamic self-teacher. Unlike traditional diffusion or flow models, it does not rely solely on local supervision, which typically necessitates many inference steps. Unlike distillation-based approaches, it does not require a pretrained teacher. This combination of instantaneous local learning and self-driven global matching bridges the gap between the two paradigms, enabling the training of a high-quality text-to-image model from scratch that excels even at very low step counts. Extensive experiments on large-scale text-to-image benchmarks show that Self-E not only excels in few-step generation, but is also competitive with state-of-the-art Flow Matching models at 50 steps. We further find that its performance improves monotonically as inference steps increase, enabling both ultra-fast few-step generation and high-quality long-trajectory sampling within a single unified model. To our knowledge, Self-E is the first from-scratch, any-step text-to-image model, offering a unified framework for efficient and scalable generation.
Whole-Body Control With Terrain Estimation of A 6-DoF Wheeled Bipedal Robot
Nov 09, 2025
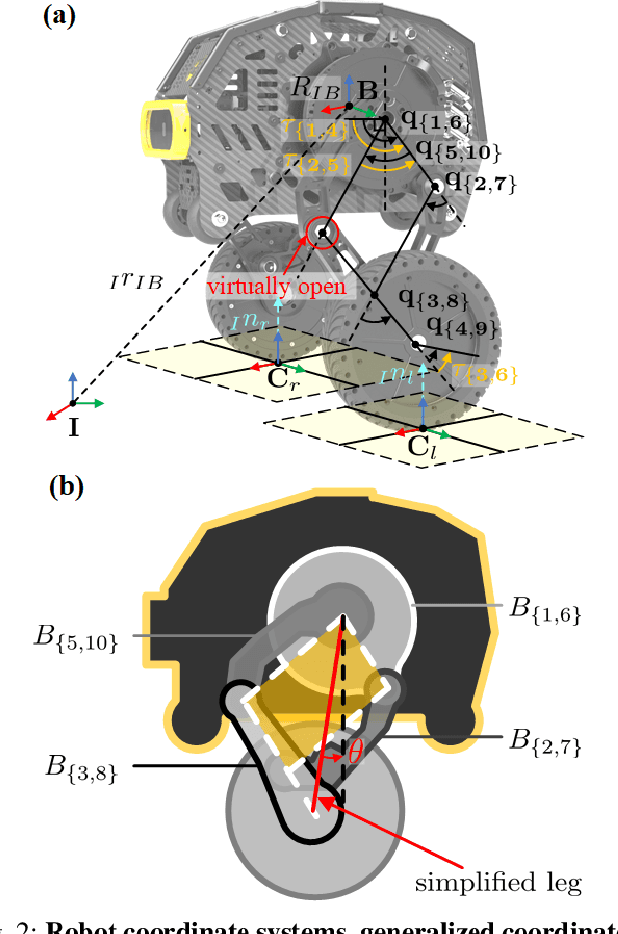
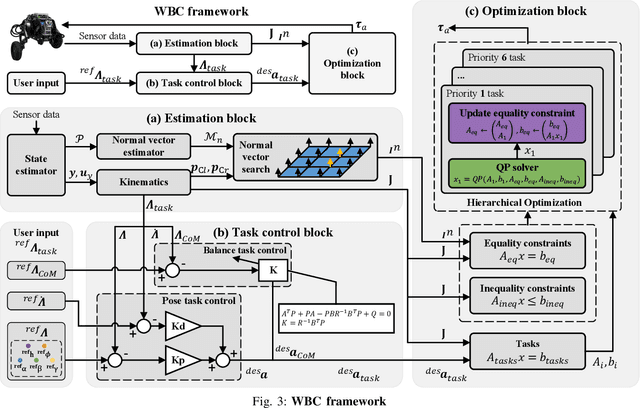
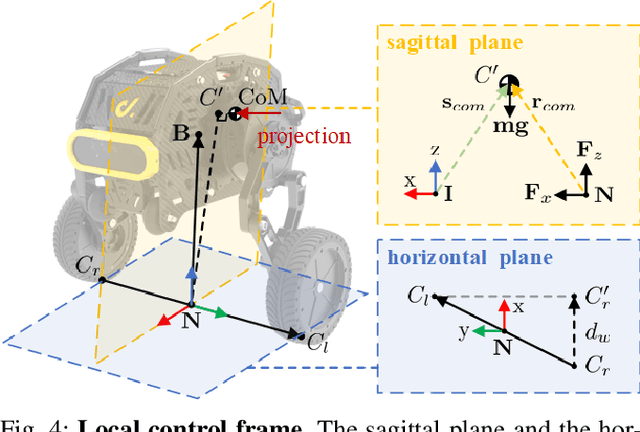
Wheeled bipedal robots have garnered increasing attention in exploration and inspection. However, most research simplifies calculations by ignoring leg dynamics, thereby restricting the robot's full motion potential. Additionally, robots face challenges when traversing uneven terrain. To address the aforementioned issue, we develop a complete dynamics model and design a whole-body control framework with terrain estimation for a novel 6 degrees of freedom wheeled bipedal robot. This model incorporates the closed-loop dynamics of the robot and a ground contact model based on the estimated ground normal vector. We use a LiDAR inertial odometry framework and improved Principal Component Analysis for terrain estimation. Task controllers, including PD control law and LQR, are employed for pose control and centroidal dynamics-based balance control, respectively. Furthermore, a hierarchical optimization approach is used to solve the whole-body control problem. We validate the performance of the terrain estimation algorithm and demonstrate the algorithm's robustness and ability to traverse uneven terrain through both simulation and real-world experiments.
OneTrans: Unified Feature Interaction and Sequence Modeling with One Transformer in Industrial Recommender
Oct 30, 2025In recommendation systems, scaling up feature-interaction modules (e.g., Wukong, RankMixer) or user-behavior sequence modules (e.g., LONGER) has achieved notable success. However, these efforts typically proceed on separate tracks, which not only hinders bidirectional information exchange but also prevents unified optimization and scaling. In this paper, we propose OneTrans, a unified Transformer backbone that simultaneously performs user-behavior sequence modeling and feature interaction. OneTrans employs a unified tokenizer to convert both sequential and non-sequential attributes into a single token sequence. The stacked OneTrans blocks share parameters across similar sequential tokens while assigning token-specific parameters to non-sequential tokens. Through causal attention and cross-request KV caching, OneTrans enables precomputation and caching of intermediate representations, significantly reducing computational costs during both training and inference. Experimental results on industrial-scale datasets demonstrate that OneTrans scales efficiently with increasing parameters, consistently outperforms strong baselines, and yields a 5.68% lift in per-user GMV in online A/B tests.
An Experimental Approach for Running-Time Estimation of Multi-objective Evolutionary Algorithms in Numerical Optimization
Jul 03, 2025Multi-objective evolutionary algorithms (MOEAs) have become essential tools for solving multi-objective optimization problems (MOPs), making their running time analysis crucial for assessing algorithmic efficiency and guiding practical applications. While significant theoretical advances have been achieved for combinatorial optimization, existing studies for numerical optimization primarily rely on algorithmic or problem simplifications, limiting their applicability to real-world scenarios. To address this gap, we propose an experimental approach for estimating upper bounds on the running time of MOEAs in numerical optimization without simplification assumptions. Our approach employs an average gain model that characterizes algorithmic progress through the Inverted Generational Distance metric. To handle the stochastic nature of MOEAs, we use statistical methods to estimate the probabilistic distribution of gains. Recognizing that gain distributions in numerical optimization exhibit irregular patterns with varying densities across different regions, we introduce an adaptive sampling method that dynamically adjusts sampling density to ensure accurate surface fitting for running time estimation. We conduct comprehensive experiments on five representative MOEAs (NSGA-II, MOEA/D, AR-MOEA, AGEMOEA-II, and PREA) using the ZDT and DTLZ benchmark suites. The results demonstrate the effectiveness of our approach in estimating upper bounds on the running time without requiring algorithmic or problem simplifications. Additionally, we provide a web-based implementation to facilitate broader adoption of our methodology. This work provides a practical complement to theoretical research on MOEAs in numerical optimization.
RAG-6DPose: Retrieval-Augmented 6D Pose Estimation via Leveraging CAD as Knowledge Base
Jun 23, 2025Accurate 6D pose estimation is key for robotic manipulation, enabling precise object localization for tasks like grasping. We present RAG-6DPose, a retrieval-augmented approach that leverages 3D CAD models as a knowledge base by integrating both visual and geometric cues. Our RAG-6DPose roughly contains three stages: 1) Building a Multi-Modal CAD Knowledge Base by extracting 2D visual features from multi-view CAD rendered images and also attaching 3D points; 2) Retrieving relevant CAD features from the knowledge base based on the current query image via our ReSPC module; and 3) Incorporating retrieved CAD information to refine pose predictions via retrieval-augmented decoding. Experimental results on standard benchmarks and real-world robotic tasks demonstrate the effectiveness and robustness of our approach, particularly in handling occlusions and novel viewpoints. Supplementary material is available on our project website: https://sressers.github.io/RAG-6DPose .
You Only Estimate Once: Unified, One-stage, Real-Time Category-level Articulated Object 6D Pose Estimation for Robotic Grasping
Jun 06, 2025This paper addresses the problem of category-level pose estimation for articulated objects in robotic manipulation tasks. Recent works have shown promising results in estimating part pose and size at the category level. However, these approaches primarily follow a complex multi-stage pipeline that first segments part instances in the point cloud and then estimates the Normalized Part Coordinate Space (NPCS) representation for 6D poses. These approaches suffer from high computational costs and low performance in real-time robotic tasks. To address these limitations, we propose YOEO, a single-stage method that simultaneously outputs instance segmentation and NPCS representations in an end-to-end manner. We use a unified network to generate point-wise semantic labels and centroid offsets, allowing points from the same part instance to vote for the same centroid. We further utilize a clustering algorithm to distinguish points based on their estimated centroid distances. Finally, we first separate the NPCS region of each instance. Then, we align the separated regions with the real point cloud to recover the final pose and size. Experimental results on the GAPart dataset demonstrate the pose estimation capabilities of our proposed single-shot method. We also deploy our synthetically-trained model in a real-world setting, providing real-time visual feedback at 200Hz, enabling a physical Kinova robot to interact with unseen articulated objects. This showcases the utility and effectiveness of our proposed method.
DRO: A Python Library for Distributionally Robust Optimization in Machine Learning
May 29, 2025



We introduce dro, an open-source Python library for distributionally robust optimization (DRO) for regression and classification problems. The library implements 14 DRO formulations and 9 backbone models, enabling 79 distinct DRO methods. Furthermore, dro is compatible with both scikit-learn and PyTorch. Through vectorization and optimization approximation techniques, dro reduces runtime by 10x to over 1000x compared to baseline implementations on large-scale datasets. Comprehensive documentation is available at https://python-dro.org.