 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparseGrasp: Robotic Grasping via 3D Semantic Gaussian Splatting from Sparse Multi-View RGB Images
Dec 03, 2024Language-guided robotic grasping is a rapidly advancing field where robots are instructed using human language to grasp specific objects. However, existing methods often depend on dense camera views and struggle to quickly update scenes, limiting their effectiveness in changeable environments. In contrast, we propose SparseGrasp, a novel open-vocabulary robotic grasping system that operates efficiently with sparse-view RGB images and handles scene updates fastly. Our system builds upon and significantly enhances existing computer vision modules in robotic learning. Specifically, SparseGrasp utilizes DUSt3R to generate a dense point cloud as the initialization for 3D Gaussian Splatting (3DGS), maintaining high fidelity even under sparse supervision. Importantly, SparseGrasp incorporates semantic awareness from recent vision foundation models. To further improve processing efficiency, we repurpose Principal Component Analysis (PCA) to compress features from 2D models. Additionally, we introduce a novel render-and-compare strategy that ensures rapid scene updates, enabling multi-turn grasping in changeable environments. Experimental results show that SparseGrasp significantly outperforms state-of-the-art methods in terms of both speed and adaptability, providing a robust solution for multi-turn grasping in changeable environment.
Improving Neural Surface Reconstruction with Feature Priors from Multi-View Image
Aug 04, 2024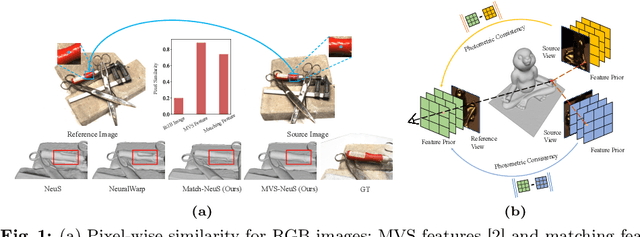
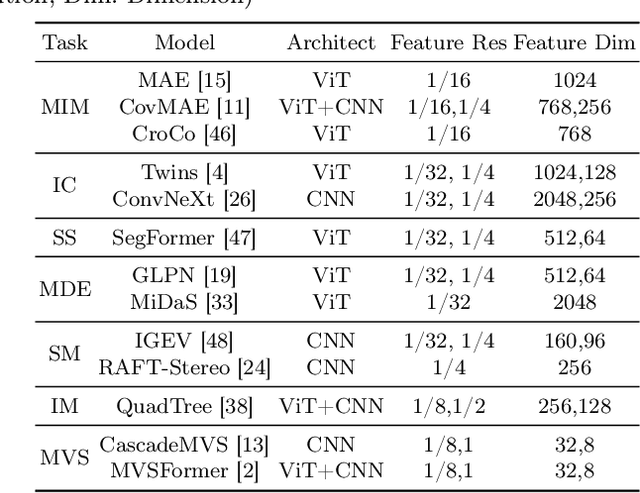
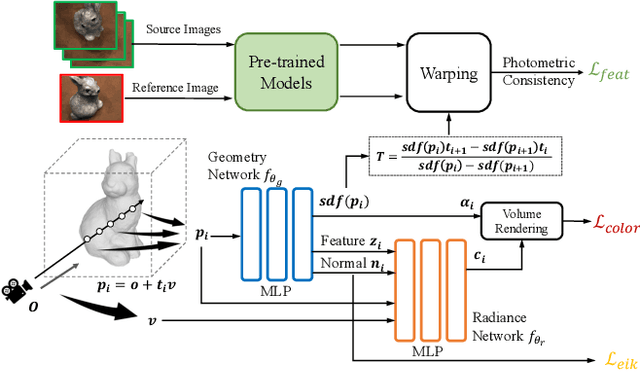

Recent advancements in Neural Surface Reconstruction (NSR) have significantly improved multi-view reconstruction when coupled with volume rendering. However, relying solely on photometric consistency in image space falls short of addressing complexities posed by real-world data, including occlusions and non-Lambertian surfaces. To tackle these challenges, we propose an investigation into feature-level consistent loss, aiming to harness valuable feature priors from diverse pretext visual tasks and overcome current limitations. It is crucial to note the existing gap in determining the most effective pretext visual task for enhancing NSR. In this study, we comprehensively explore multi-view feature priors from seven pretext visual tasks, comprising thirteen methods. Our main goal is to strengthen NSR training by considering a wide range of possibilities. Additionally, we examine the impact of varying feature resolutions and evaluate both pixel-wise and patch-wise consistent losses, providing insights into effective strategies for improving NSR performance. By incorporating pre-trained representations from MVSFormer and QuadTree, our approach can generate variations of MVS-NeuS and Match-NeuS, respectively. Our results, analyzed on DTU and EPFL datasets, reveal that feature priors from image matching and multi-view stereo outperform other pretext tasks. Moreover, we discover that extending patch-wise photometric consistency to the feature level surpasses the performance of pixel-wise approaches. These findings underscore the effectiveness of these techniques in enhancing NSR outcomes.
MVSFormer++: Revealing the Devil in Transformer's Details for Multi-View Stereo
Jan 22, 2024Recent advancements in learning-based Multi-View Stereo (MVS) methods have prominently featured transformer-based models with attention mechanisms. However, existing approaches have not thoroughly investigated the profound influence of transformers on different MVS modules, resulting in limited depth estimation capabilities. In this paper, we introduce MVSFormer++, a method that prudently maximizes the inherent characteristics of attention to enhance various components of the MVS pipeline. Formally, our approach involves infusing cross-view information into the pre-trained DINOv2 model to facilitate MVS learning. Furthermore, we employ different attention mechanisms for the feature encoder and cost volume regularization, focusing on feature and spatial aggregations respectively. Additionally, we uncover that some design details would substantially impact the performance of transformer modules in MVS, including normalized 3D positional encoding, adaptive attention scaling, and the position of layer normalization. Comprehensive experiments on DTU, Tanks-and-Temples, BlendedMVS, and ETH3D validate the effectiveness of the proposed method. Notably, MVSFormer++ achieves state-of-the-art performance on the challenging DTU and Tanks-and-Temples benchmarks.
* Accepted to ICLR2024
Rethinking the Multi-view Stereo from the Perspective of Rendering-based Augmentation
Mar 11, 2023GigaMVS presents several challenges to existing Multi-View Stereo (MVS) algorithms for its large scale, complex occlusions, and gigapixel images. To address these problems, we first apply one of the state-of-the-art learning-based MVS methods, --MVSFormer, to overcome intractable scenarios such as textureless and reflections regions suffered by traditional PatchMatch methods, but it fails in a few large scenes' reconstructions. Moreover, traditional PatchMatch algorithms such as ACMMP, OpenMVS, and RealityCapture are leveraged to further improve the completeness in large scenes. Furthermore, to unify both advantages of deep learning methods and the traditional PatchMatch, we propose to render depth and color images to further fine-tune the MVSFormer model. Notably, we find that the MVS method could produce much better predictions through rendered images due to the coincident illumination, which we believe is significant for the MVS community. Thus, MVSFormer is capable of generalizing to large-scale scenes and complementarily solves the textureless reconstruction problem. Finally, we have assembled all point clouds mentioned above \textit{except ones from RealityCapture} and ranked Top-1 on the competitive GigaReconstruction.
LoRD: Local 4D Implicit Representation for High-Fidelity Dynamic Human Modeling
Aug 18, 2022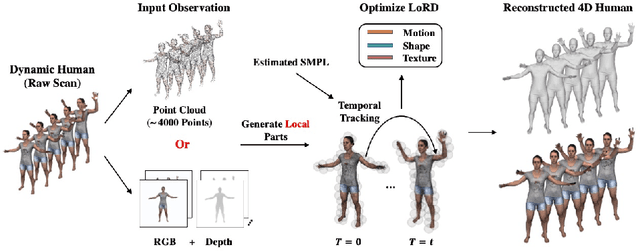

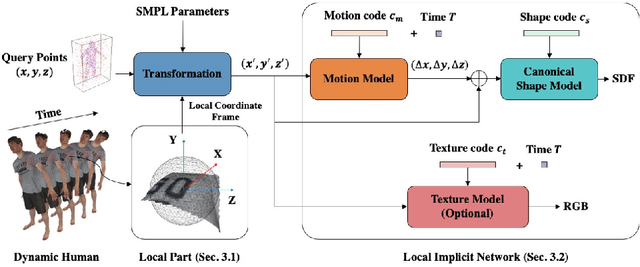
Recent progress in 4D implicit representation focuses on globally controlling the shape and motion with low dimensional latent vectors, which is prone to missing surface details and accumulating tracking error. While many deep local representations have shown promising results for 3D shape modeling, their 4D counterpart does not exist yet. In this paper, we fill this blank by proposing a novel Local 4D implicit Representation for Dynamic clothed human, named LoRD, which has the merits of both 4D human modeling and local representation, and enables high-fidelity reconstruction with detailed surface deformations, such as clothing wrinkles. Particularly, our key insight is to encourage the network to learn the latent codes of local part-level representation, capable of explaining the local geometry and temporal deformations. To make the inference at test-time, we first estimate the inner body skeleton motion to track local parts at each time step, and then optimize the latent codes for each part via auto-decoding based on different types of observed data. Extensive experiments demonstrate that the proposed method has strong capability for representing 4D human, and outperforms state-of-the-art methods on practical applications, including 4D reconstruction from sparse points, non-rigid depth fusion, both qualitatively and quantitatively.
MVSFormer: Multi-View Stereo with Pre-trained Vision Transformers and Temperature-based Depth
Aug 08, 2022Feature representation learning is the key recipe for learning-based Multi-View Stereo (MVS). As the common feature extractor of learning-based MVS, vanilla Feature Pyramid Networks (FPN) suffers from discouraged feature representations for reflection and texture-less areas, which limits the generalization of MVS. Even FPNs worked with pre-trained Convolutional Neural Networks (CNNs) fail to tackle these issues. On the other hand, Vision Transformers (ViTs) have achieved prominent success in many 2D vision tasks. Thus we ask whether ViTs can facilitate feature learning in MVS? In this paper, we propose a pre-trained ViT enhanced MVS network called MVSFormer, which can learn more reliable feature representations benefited by informative priors from ViT. Then MVSFormer-P and MVSFormer-H are further proposed with freezed ViT weights and trainable ones respectively. MVSFormer-P is more efficient while MVSFormer-H can achieve superior performance. MVSFormer can be generalized to various input resolutions with the efficient multi-scale training strengthened by gradient accumulation. Moreover, we discuss the merits and drawbacks of classification and regression-based MVS methods, and further propose to unify them with a temperature-based strategy. MVSFormer achieves state-of-the-art performance on the DTU dataset. Particularly, our anonymous submission of MVSFormer is ranked in the Top-1 position on both intermediate and advanced sets of the highly competitive Tanks-and-Temples leaderboard on the day of submission compared with other published works. Codes and models will be released soon.
Density-preserving Deep Point Cloud Compression
Apr 27, 2022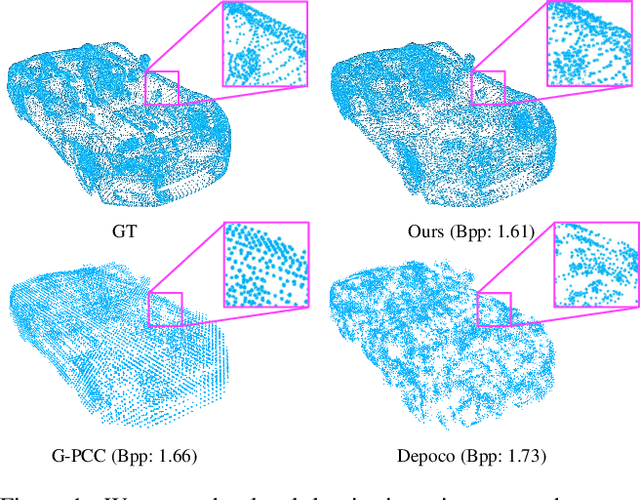
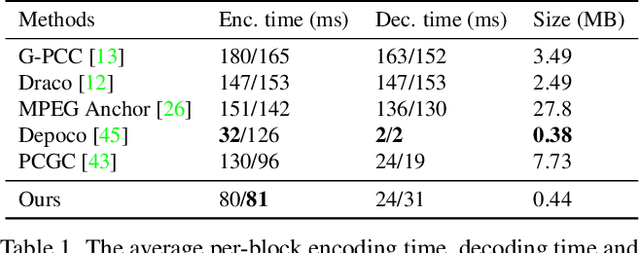
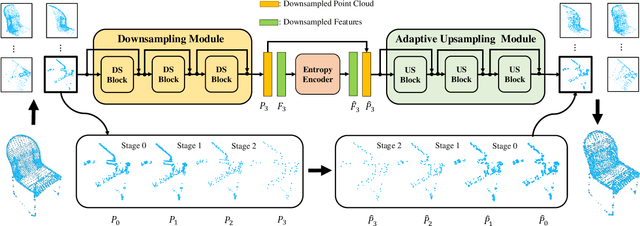
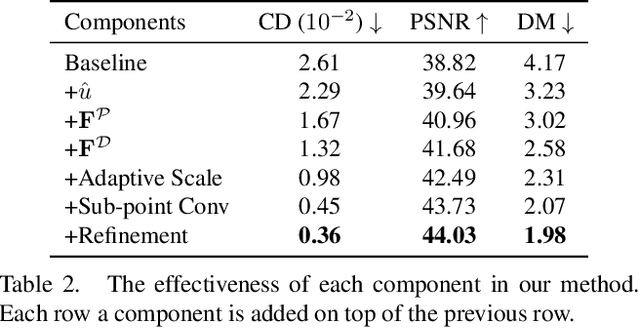
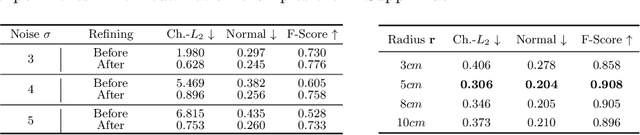
Local density of point clouds is crucial for representing local details, but has been overlooked by existing point cloud compression methods. To address this, we propose a novel deep point cloud compression method that preserves local density information. Our method works in an auto-encoder fashion: the encoder downsamples the points and learns point-wise features, while the decoder upsamples the points using these features. Specifically, we propose to encode local geometry and density with three embeddings: density embedding, local position embedding and ancestor embedding. During the decoding, we explicitly predict the upsampling factor for each point, and the directions and scales of the upsampled points. To mitigate the clustered points issue in existing methods, we design a novel sub-point convolution layer, and an upsampling block with adaptive scale. Furthermore, our method can also compress point-wise attributes, such as normal. Extensive qualitative and quantitative results on SemanticKITTI and ShapeNet demonstrate that our method achieves the state-of-the-art rate-distortion trade-off.