 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenesisTex: Adapting Image Denoising Diffusion to Texture Space
Mar 26, 2024



We present GenesisTex, a novel method for synthesizing textures for 3D geometries from text descriptions. GenesisTex adapts the pretrained image diffusion model to texture space by texture space sampling. Specifically, we maintain a latent texture map for each viewpoint, which is updated with predicted noise on the rendering of the corresponding viewpoint. The sampled latent texture maps are then decoded into a final texture map. During the sampling process, we focus on both global and local consistency across multiple viewpoints: global consistency is achieved through the integration of style consistency mechanisms within the noise prediction network, and low-level consistency is achieved by dynamically aligning latent textures. Finally, we apply reference-based inpainting and img2img on denser views for texture refinement. Our approach overcomes the limitations of slow optimization in distillation-based methods and instability in inpainting-based methods. Experiments on meshes from various sources demonstrate that our method surpasses the baseline methods quantitatively and qualitatively.
T-Pixel2Mesh: Combining Global and Local Transformer for 3D Mesh Generation from a Single Image
Mar 20, 2024



Pixel2Mesh (P2M) is a classical approach for reconstructing 3D shapes from a single color image through coarse-to-fine mesh deformation. Although P2M is capable of generating plausible global shapes, its Graph Convolution Network (GCN) often produces overly smooth results, causing the loss of fine-grained geometry details. Moreover, P2M generates non-credible features for occluded regions and struggles with the domain gap from synthetic data to real-world images, which is a common challenge for single-view 3D reconstruction methods. To address these challenges, we propose a novel Transformer-boosted architecture, named T-Pixel2Mesh, inspired by the coarse-to-fine approach of P2M. Specifically, we use a global Transformer to control the holistic shape and a local Transformer to progressively refine the local geometry details with graph-based point upsampling. To enhance real-world reconstruction, we present the simple yet effective Linear Scale Search (LSS), which serves as prompt tuning during the input preprocessing. Our experiments on ShapeNet demonstrate state-of-the-art performance, while results on real-world data show the generalization capability.
GeoVLN: Learning Geometry-Enhanced Visual Representation with Slot Attention for Vision-and-Language Navigation
May 26, 2023



Most existing works solving Room-to-Room VLN problem only utilize RGB images and do not consider local context around candidate views, which lack sufficient visual cues about surrounding environment. Moreover, natural language contains complex semantic information thus its correlations with visual inputs are hard to model merely with cross attention. In this paper, we propose GeoVLN, which learns Geometry-enhanced visual representation based on slot attention for robust Visual-and-Language Navigation. The RGB images are compensated with the corresponding depth maps and normal maps predicted by Omnidata as visual inputs. Technically, we introduce a two-stage module that combine local slot attention and CLIP model to produce geometry-enhanced representation from such input. We employ V&L BERT to learn a cross-modal representation that incorporate both language and vision informations. Additionally, a novel multiway attention module is designed, encouraging different phrases of input instruction to exploit the most related features from visual input. Extensive experiments demonstrate the effectiveness of our newly designed modules and show the compelling performance of the proposed method.
LoRD: Local 4D Implicit Representation for High-Fidelity Dynamic Human Modeling
Aug 18, 2022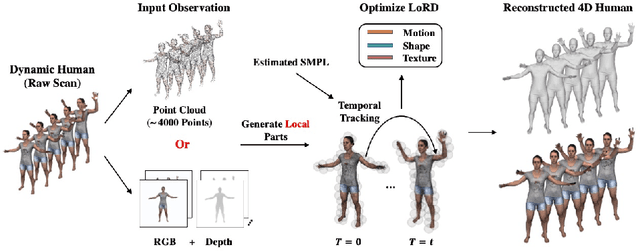

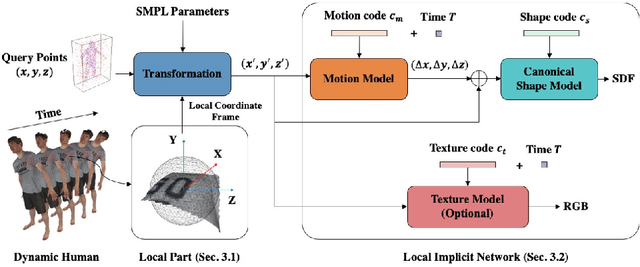
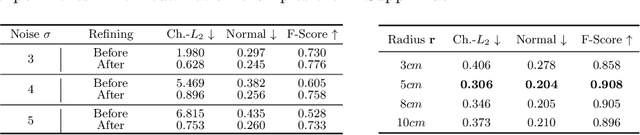
Recent progress in 4D implicit representation focuses on globally controlling the shape and motion with low dimensional latent vectors, which is prone to missing surface details and accumulating tracking error. While many deep local representations have shown promising results for 3D shape modeling, their 4D counterpart does not exist yet. In this paper, we fill this blank by proposing a novel Local 4D implicit Representation for Dynamic clothed human, named LoRD, which has the merits of both 4D human modeling and local representation, and enables high-fidelity reconstruction with detailed surface deformations, such as clothing wrinkles. Particularly, our key insight is to encourage the network to learn the latent codes of local part-level representation, capable of explaining the local geometry and temporal deformations. To make the inference at test-time, we first estimate the inner body skeleton motion to track local parts at each time step, and then optimize the latent codes for each part via auto-decoding based on different types of observed data. Extensive experiments demonstrate that the proposed method has strong capability for representing 4D human, and outperforms state-of-the-art methods on practical applications, including 4D reconstruction from sparse points, non-rigid depth fusion, both qualitatively and quantitatively.
H4D: Human 4D Modeling by Learning Neural Compositional Representation
Mar 02, 2022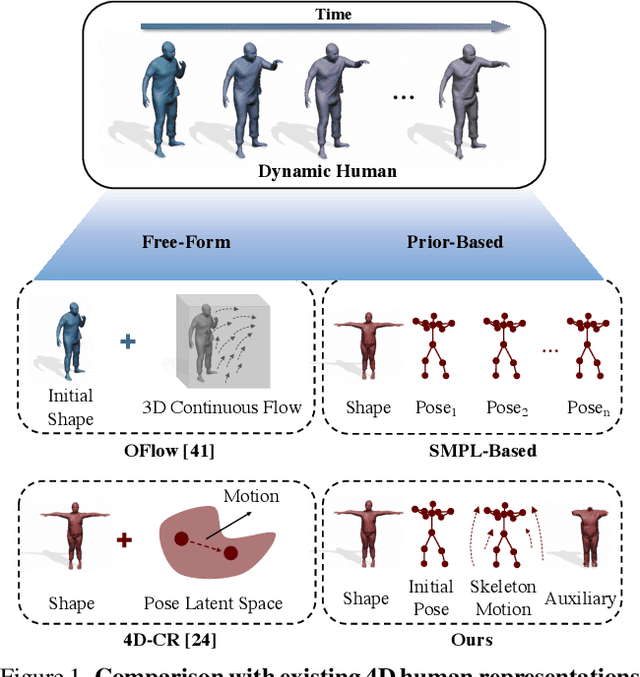
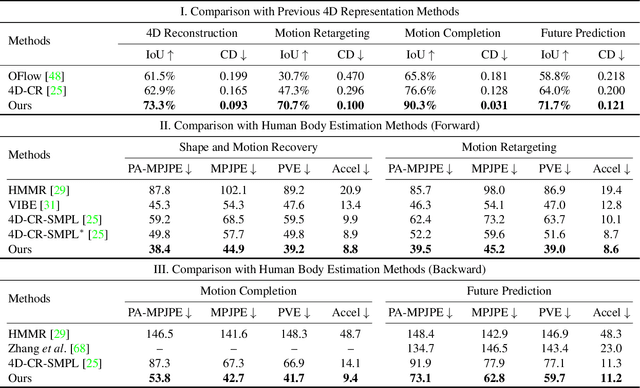
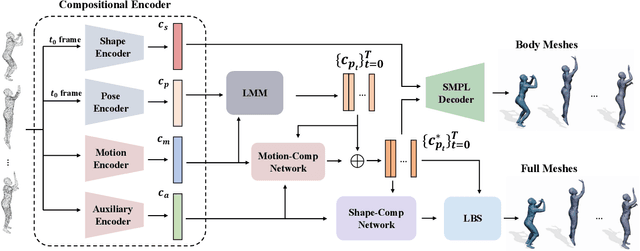
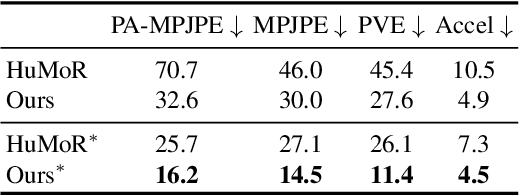
Despite the impressive results achieved by deep learning based 3D reconstruction, the techniques of directly learning to model the 4D human captures with detailed geometry have been less studied. This work presents a novel framework that can effectively learn a compact and compositional representation for dynamic human by exploiting the human body prior from the widely-used SMPL parametric model. Particularly, our representation, named H4D, represents dynamic 3D human over a temporal span into the latent spaces encoding shape, initial pose, motion and auxiliary information. A simple yet effective linear motion model is proposed to provide a rough and regularized motion estimation, followed by per-frame compensation for pose and geometry details with the residual encoded in the auxiliary code. Technically, we introduce novel GRU-based architectures to facilitate learning and improve the representation capability. Extensive experiments demonstrate our method is not only efficacy in recovering dynamic human with accurate motion and detailed geometry, but also amenable to various 4D human related tasks, including motion retargeting, motion completion and future prediction.
Learning Compositional Representation for 4D Captures with Neural ODE
Mar 15, 2021



Learning based representation has become the key to the success of many computer vision systems. While many 3D representations have been proposed, it is still an unaddressed problem for how to represent a dynamically changing 3D object. In this paper, we introduce a compositional representation for 4D captures, i.e. a deforming 3D object over a temporal span, that disentangles shape, initial state, and motion respectively. Each component is represented by a latent code via a trained encoder. To model the motion, a neural Ordinary Differential Equation (ODE) is trained to update the initial state conditioned on the learned motion code, and a decoder takes the shape code and the updated pose code to reconstruct 4D captures at each time stamp. To this end, we propose an Identity Exchange Training (IET) strategy to encourage the network to learn effectively decoupling each component. Extensive experiments demonstrate that the proposed method outperforms existing state-of-the-art deep learning based methods on 4D reconstruction, and significantly improves on various tasks, including motion transfer and completion.