 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysCodeBench: Benchmarking Physics-Aware Symbolic Simulation of 3D Scenes via Self-Corrective Multi-Agent Refinement
Apr 26, 2026Physics-aware symbolic simulation of 3D scenes is critical for robotics, embodied AI, and scientific computing, requiring models to understand natural language descriptions of physical phenomena and translate them into executable simulation environments. While large language models (LLMs) excel at general code generation, they struggle with the semantic gap between physical descriptions and simulation implementation. We introduce PhysCodeBench, the first comprehensive benchmark for evaluating physics-aware symbolic simulation, comprising 700 manually-crafted diverse samples across mechanics, fluid dynamics, and soft-body physics with expert annotations. Our evaluation framework measures both code executability and physical accuracy through automated and visual assessment. Building on this, we propose a Self-Corrective Multi-Agent Refinement Framework (SMRF) with three specialized agents (simulation generator, error corrector, and simulation refiner) that collaborate iteratively with domain-specific validation to produce physically accurate simulations. SMRF achieves 67.7 points overall performance compared to 36.3 points for the best baseline among evaluated SOTA models, representing a 31.4-point improvement. Our analysis demonstrates that error correction is critical for accurate physics-aware symbolic simulation and that specialized multi-agent approaches significantly outperform single-agent methods across the tested physical domains.
LUVE : Latent-Cascaded Ultra-High-Resolution Video Generation with Dual Frequency Experts
Feb 12, 2026Recent advances in video diffusion models have significantly improved visual quality, yet ultra-high-resolution (UHR) video generation remains a formidable challenge due to the compounded difficulties of motion modeling, semantic planning, and detail synthesis. To address these limitations, we propose \textbf{LUVE}, a \textbf{L}atent-cascaded \textbf{U}HR \textbf{V}ideo generation framework built upon dual frequency \textbf{E}xperts. LUVE employs a three-stage architecture comprising low-resolution motion generation for motion-consistent latent synthesis, video latent upsampling that performs resolution upsampling directly in the latent space to mitigate memory and computational overhead, and high-resolution content refinement that integrates low-frequency and high-frequency experts to jointly enhance semantic coherence and fine-grained detail generation. Extensive experiments demonstrate that our LUVE achieves superior photorealism and content fidelity in UHR video generation, and comprehensive ablation studies further validate the effectiveness of each component. The project is available at \href{https://unicornanrocinu.github.io/LUVE_web/}{https://github.io/LUVE/}.
Muses: Designing, Composing, Generating Nonexistent Fantasy 3D Creatures without Training
Jan 06, 2026We present Muses, the first training-free method for fantastic 3D creature generation in a feed-forward paradigm. Previous methods, which rely on part-aware optimization, manual assembly, or 2D image generation, often produce unrealistic or incoherent 3D assets due to the challenges of intricate part-level manipulation and limited out-of-domain generation. In contrast, Muses leverages the 3D skeleton, a fundamental representation of biological forms, to explicitly and rationally compose diverse elements. This skeletal foundation formalizes 3D content creation as a structure-aware pipeline of design, composition, and generation. Muses begins by constructing a creatively composed 3D skeleton with coherent layout and scale through graph-constrained reasoning. This skeleton then guides a voxel-based assembly process within a structured latent space, integrating regions from different objects. Finally, image-guided appearance modeling under skeletal conditions is applied to generate a style-consistent and harmonious texture for the assembled shape. Extensive experiments establish Muses' state-of-the-art performance in terms of visual fidelity and alignment with textual descriptions, and potential on flexible 3D object editing. Project page: https://luhexiao.github.io/Muses.github.io/.
DiffProxy: Multi-View Human Mesh Recovery via Diffusion-Generated Dense Proxies
Jan 05, 2026Human mesh recovery from multi-view images faces a fundamental challenge: real-world datasets contain imperfect ground-truth annotations that bias the models' training, while synthetic data with precise supervision suffers from domain gap. In this paper, we propose DiffProxy, a novel framework that generates multi-view consistent human proxies for mesh recovery. Central to DiffProxy is leveraging the diffusion-based generative priors to bridge the synthetic training and real-world generalization. Its key innovations include: (1) a multi-conditional mechanism for generating multi-view consistent, pixel-aligned human proxies; (2) a hand refinement module that incorporates flexible visual prompts to enhance local details; and (3) an uncertainty-aware test-time scaling method that increases robustness to challenging cases during optimization. These designs ensure that the mesh recovery process effectively benefits from the precise synthetic ground truth and generative advantages of the diffusion-based pipeline. Trained entirely on synthetic data, DiffProxy achieves state-of-the-art performance across five real-world benchmarks, demonstrating strong zero-shot generalization particularly on challenging scenarios with occlusions and partial views. Project page: https://wrk226.github.io/DiffProxy.html
MorphAny3D: Unleashing the Power of Structured Latent in 3D Morphing
Jan 01, 20263D morphing remains challenging due to the difficulty of generating semantically consistent and temporally smooth deformations, especially across categories. We present MorphAny3D, a training-free framework that leverages Structured Latent (SLAT) representations for high-quality 3D morphing. Our key insight is that intelligently blending source and target SLAT features within the attention mechanisms of 3D generators naturally produces plausible morphing sequences. To this end, we introduce Morphing Cross-Attention (MCA), which fuses source and target information for structural coherence, and Temporal-Fused Self-Attention (TFSA), which enhances temporal consistency by incorporating features from preceding frames. An orientation correction strategy further mitigates the pose ambiguity within the morphing steps. Extensive experiments show that our method generates state-of-the-art morphing sequences, even for challenging cross-category cases. MorphAny3D further supports advanced applications such as decoupled morphing and 3D style transfer, and can be generalized to other SLAT-based generative models. Project page: https://xiaokunsun.github.io/MorphAny3D.github.io/.
UltraHR-100K: Enhancing UHR Image Synthesis with A Large-Scale High-Quality Dataset
Oct 23, 2025

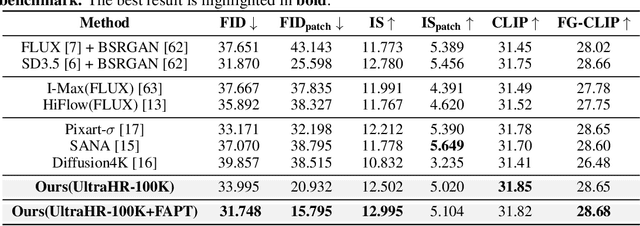
Ultra-high-resolution (UHR) text-to-image (T2I) generation has seen notable progress. However, two key challenges remain : 1) the absence of a large-scale high-quality UHR T2I dataset, and (2) the neglect of tailored training strategies for fine-grained detail synthesis in UHR scenarios. To tackle the first challenge, we introduce \textbf{UltraHR-100K}, a high-quality dataset of 100K UHR images with rich captions, offering diverse content and strong visual fidelity. Each image exceeds 3K resolution and is rigorously curated based on detail richness, content complexity, and aesthetic quality. To tackle the second challenge, we propose a frequency-aware post-training method that enhances fine-detail generation in T2I diffusion models. Specifically, we design (i) \textit{Detail-Oriented Timestep Sampling (DOTS)} to focus learning on detail-critical denoising steps, and (ii) \textit{Soft-Weighting Frequency Regularization (SWFR)}, which leverages Discrete Fourier Transform (DFT) to softly constrain frequency components, encouraging high-frequency detail preservation. Extensive experiments on our proposed UltraHR-eval4K benchmarks demonstrate that our approach significantly improves the fine-grained detail quality and overall fidelity of UHR image generation. The code is available at \href{https://github.com/NJU-PCALab/UltraHR-100k}{here}.
TextCrafter: Accurately Rendering Multiple Texts in Complex Visual Scenes
Apr 01, 2025This paper explores the task of Complex Visual Text Generation (CVTG), which centers on generating intricate textual content distributed across diverse regions within visual images. In CVTG, image generation models often rendering distorted and blurred visual text or missing some visual text. To tackle these challenges, we propose TextCrafter, a novel multi-visual text rendering method. TextCrafter employs a progressive strategy to decompose complex visual text into distinct components while ensuring robust alignment between textual content and its visual carrier. Additionally, it incorporates a token focus enhancement mechanism to amplify the prominence of visual text during the generation process. TextCrafter effectively addresses key challenges in CVTG tasks, such as text confusion, omissions, and blurriness. Moreover, we present a new benchmark dataset, CVTG-2K, tailored to rigorously evaluate the performance of generative models on CVTG tasks. Extensive experiments demonstrate that our method surpasses state-of-the-art approaches.
From Zero to Detail: Deconstructing Ultra-High-Definition Image Restoration from Progressive Spectral Perspective
Mar 17, 2025Ultra-high-definition (UHD) image restoration faces significant challenges due to its high resolution, complex content, and intricate details. To cope with these challenges, we analyze the restoration process in depth through a progressive spectral perspective, and deconstruct the complex UHD restoration problem into three progressive stages: zero-frequency enhancement, low-frequency restoration, and high-frequency refinement. Building on this insight, we propose a novel framework, ERR, which comprises three collaborative sub-networks: the zero-frequency enhancer (ZFE), the low-frequency restorer (LFR), and the high-frequency refiner (HFR). Specifically, the ZFE integrates global priors to learn global mapping, while the LFR restores low-frequency information, emphasizing reconstruction of coarse-grained content. Finally, the HFR employs our designed frequency-windowed kolmogorov-arnold networks (FW-KAN) to refine textures and details, producing high-quality image restoration. Our approach significantly outperforms previous UHD methods across various tasks, with extensive ablation studies validating the effectiveness of each component. The code is available at \href{https://github.com/NJU-PCALab/ERR}{here}.
Image Inversion: A Survey from GANs to Diffusion and Beyond
Feb 17, 2025Image inversion is a fundamental task in generative models, aiming to map images back to their latent representations to enable downstream applications such as editing, restoration, and style transfer. This paper provides a comprehensive review of the latest advancements in image inversion techniques, focusing on two main paradigms: Generative Adversarial Network (GAN) inversion and diffusion model inversion. We categorize these techniques based on their optimization methods. For GAN inversion, we systematically classify existing methods into encoder-based approaches, latent optimization approaches, and hybrid approaches, analyzing their theoretical foundations, technical innovations, and practical trade-offs. For diffusion model inversion, we explore training-free strategies, fine-tuning methods, and the design of additional trainable modules, highlighting their unique advantages and limitations. Additionally, we discuss several popular downstream applications and emerging applications beyond image tasks, identifying current challenges and future research directions. By synthesizing the latest developments, this paper aims to provide researchers and practitioners with a valuable reference resource, promoting further advancements in the field of image inversion. We keep track of the latest works at https://github.com/RyanChenYN/ImageInversion
Adaptive Perception for Unified Visual Multi-modal Object Tracking
Feb 10, 2025Recently, many multi-modal trackers prioritize RGB as the dominant modality, treating other modalities as auxiliary, and fine-tuning separately various multi-modal tasks. This imbalance in modality dependence limits the ability of methods to dynamically utilize complementary information from each modality in complex scenarios, making it challenging to fully perceive the advantages of multi-modal. As a result, a unified parameter model often underperforms in various multi-modal tracking tasks. To address this issue, we propose APTrack, a novel unified tracker designed for multi-modal adaptive perception. Unlike previous methods, APTrack explores a unified representation through an equal modeling strategy. This strategy allows the model to dynamically adapt to various modalities and tasks without requiring additional fine-tuning between different tasks. Moreover, our tracker integrates an adaptive modality interaction (AMI) module that efficiently bridges cross-modality interactions by generating learnable tokens. Experiments conducted on five diverse multi-modal datasets (RGBT234, LasHeR, VisEvent, DepthTrack, and VOT-RGBD2022) demonstrate that APTrack not only surpasses existing state-of-the-art unified multi-modal trackers but also outperforms trackers designed for specific multi-modal tasks.