 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpiking Pyramid Wavelet Transformation for High-efficient and Low-energy Image Restoration
Jun 17, 2026Spiking neural networks (SNNs) have garnered significant interest in computer vision due to their potential for efficiency and biological inspiration. While spiking CNN-based methods have shown promise for image restoration (IR) tasks, their performance is constrained by the inherent receptive field limitations of CNN operations. In the paper, we explore the benefits of discrete wavelet transformation and propose a spiking pyramid wavelet-based model (SPWM) for high-efficient and low-energy target. Specifically, we develop a spiking dual pyramid wavelet (SDPW) block to model long-range dependency and exploit the properties of the degradation in the wavelet domain. Experimental results on several benchmarks demonstrate that SPWM significantly lowers computational costs and energy consumption while maintaining image quality. Our method showcases the potential of SNNs in the field of IR, offering new insights for future applications of resource-limited devices.
Dual-branch Distilled Transformer for Efficient Asymmetric UAV Tracking
May 27, 2026Given the real-time demands of UAV tracking, many methods simplify the backbone to reduce computation, but this often weakens feature representation and degrades performance in complex scenarios. To alleviate this issue, we propose EATrack, an efficient and asymmetric UAV tracking framework centered around a teacher-guided dual-branch distillation strategy that enhances the feature expressiveness of the lightweight student model. Specifically, EATrack investigates two complementary perspectives of knowledge transfer: spatially focused feature-level distillation that compensates for weakened representations by guiding the student to learn strong target representations, and prediction-level distillation that enhances spatial localization by learning the teacher's capability for accurate target localization. Furthermore, to enhance robustness against appearance variations, we introduce a fine-grained target-aware distillation strategy that selectively transfers the teacher's target modeling capacity to the student. A temporal adaptation module is incorporated at inference to enhance robustness over time. Experiments on five UAV benchmarks demonstrate that EATrack achieves a favorable balance between accuracy and speed. Code: https://github.com/GXNU-ZhongLab/EATrack
An Effective End-to-End Solution for Multimodal Action Recognition
Jun 11, 2025Recently, multimodal tasks have strongly advanced the field of action recognition with their rich multimodal information. However, due to the scarcity of tri-modal data, research on tri-modal action recognition tasks faces many challenges. To this end, we have proposed a comprehensive multimodal action recognition solution that effectively utilizes multimodal information. First, the existing data are transformed and expanded by optimizing data enhancement techniques to enlarge the training scale. At the same time, more RGB datasets are used to pre-train the backbone network, which is better adapted to the new task by means of transfer learning. Secondly, multimodal spatial features are extracted with the help of 2D CNNs and combined with the Temporal Shift Module (TSM) to achieve multimodal spatial-temporal feature extraction comparable to 3D CNNs and improve the computational efficiency. In addition, common prediction enhancement methods, such as Stochastic Weight Averaging (SWA), Ensemble and Test-Time augmentation (TTA), are used to integrate the knowledge of models from different training periods of the same architecture and different architectures, so as to predict the actions from different perspectives and fully exploit the target information. Ultimately, we achieved the Top-1 accuracy of 99% and the Top-5 accuracy of 100% on the competition leaderboard, demonstrating the superiority of our solution.
Fast Adversarial Training with Weak-to-Strong Spatial-Temporal Consistency in the Frequency Domain on Videos
Apr 21, 2025Adversarial Training (AT) has been shown to significantly enhance adversarial robustness via a min-max optimization approach. However, its effectiveness in video recognition tasks is hampered by two main challenges. First, fast adversarial training for video models remains largely unexplored, which severely impedes its practical applications. Specifically, most video adversarial training methods are computationally costly, with long training times and high expenses. Second, existing methods struggle with the trade-off between clean accuracy and adversarial robustness. To address these challenges, we introduce Video Fast Adversarial Training with Weak-to-Strong consistency (VFAT-WS), the first fast adversarial training method for video data. Specifically, VFAT-WS incorporates the following key designs: First, it integrates a straightforward yet effective temporal frequency augmentation (TF-AUG), and its spatial-temporal enhanced form STF-AUG, along with a single-step PGD attack to boost training efficiency and robustness. Second, it devises a weak-to-strong spatial-temporal consistency regularization, which seamlessly integrates the simpler TF-AUG and the more complex STF-AUG. Leveraging the consistency regularization, it steers the learning process from simple to complex augmentations. Both of them work together to achieve a better trade-off between clean accuracy and robustness. Extensive experiments on UCF-101 and HMDB-51 with both CNN and Transformer-based models demonstrate that VFAT-WS achieves great improvements in adversarial robustness and corruption robustness, while accelerating training by nearly 490%.
SwimVG: Step-wise Multimodal Fusion and Adaption for Visual Grounding
Feb 24, 2025



Visual grounding aims to ground an image region through natural language, which heavily relies on cross-modal alignment. Most existing methods transfer visual/linguistic knowledge separately by fully fine-tuning uni-modal pre-trained models, followed by a simple stack of visual-language transformers for multimodal fusion. However, these approaches not only limit adequate interaction between visual and linguistic contexts, but also incur significant computational costs. Therefore, to address these issues, we explore a step-wise multimodal fusion and adaption framework, namely SwimVG. Specifically, SwimVG proposes step-wise multimodal prompts (Swip) and cross-modal interactive adapters (CIA) for visual grounding, replacing the cumbersome transformer stacks for multimodal fusion. Swip can improve {the} alignment between the vision and language representations step by step, in a token-level fusion manner. In addition, weight-level CIA further promotes multimodal fusion by cross-modal interaction. Swip and CIA are both parameter-efficient paradigms, and they fuse the cross-modal features from shallow to deep layers gradually. Experimental results on four widely-used benchmarks demonstrate that SwimVG achieves remarkable abilities and considerable benefits in terms of efficiency. Our code is available at https://github.com/liuting20/SwimVG.
Adaptive Perception for Unified Visual Multi-modal Object Tracking
Feb 10, 2025Recently, many multi-modal trackers prioritize RGB as the dominant modality, treating other modalities as auxiliary, and fine-tuning separately various multi-modal tasks. This imbalance in modality dependence limits the ability of methods to dynamically utilize complementary information from each modality in complex scenarios, making it challenging to fully perceive the advantages of multi-modal. As a result, a unified parameter model often underperforms in various multi-modal tracking tasks. To address this issue, we propose APTrack, a novel unified tracker designed for multi-modal adaptive perception. Unlike previous methods, APTrack explores a unified representation through an equal modeling strategy. This strategy allows the model to dynamically adapt to various modalities and tasks without requiring additional fine-tuning between different tasks. Moreover, our tracker integrates an adaptive modality interaction (AMI) module that efficiently bridges cross-modality interactions by generating learnable tokens. Experiments conducted on five diverse multi-modal datasets (RGBT234, LasHeR, VisEvent, DepthTrack, and VOT-RGBD2022) demonstrate that APTrack not only surpasses existing state-of-the-art unified multi-modal trackers but also outperforms trackers designed for specific multi-modal tasks.
Exploiting Multimodal Spatial-temporal Patterns for Video Object Tracking
Dec 20, 2024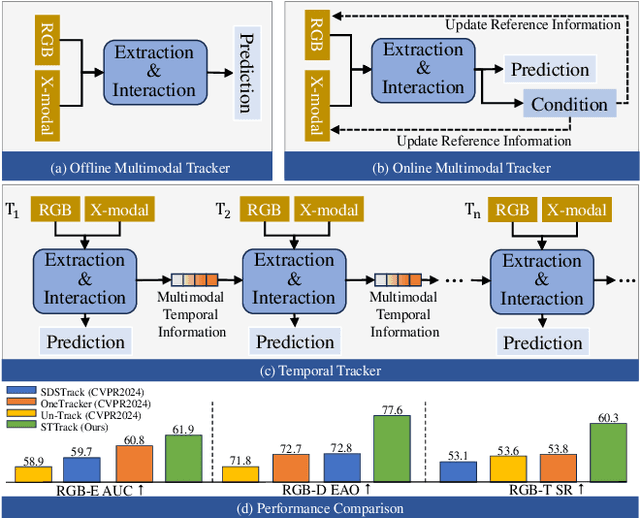
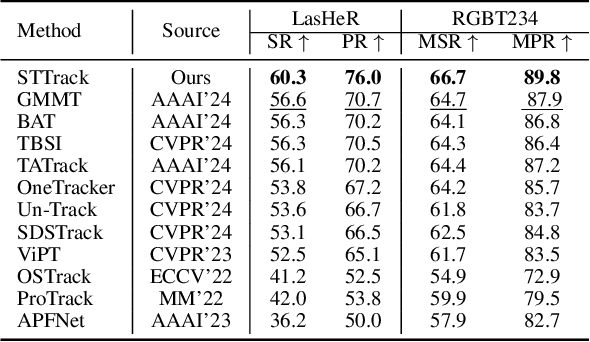
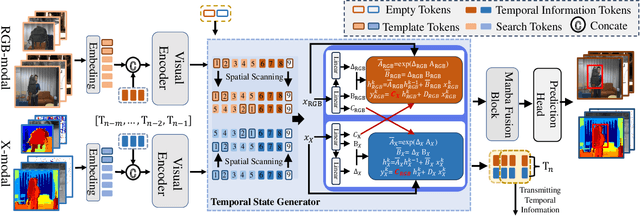
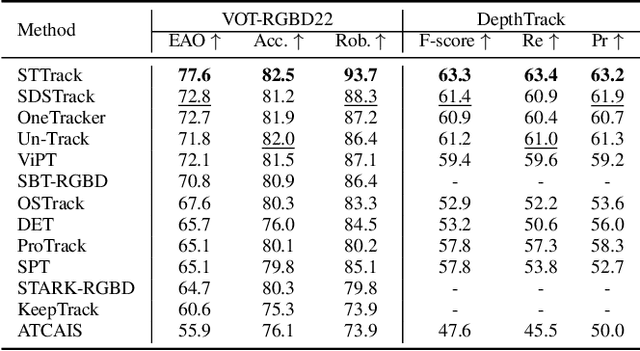
Multimodal tracking has garnered widespread attention as a result of its ability to effectively address the inherent limitations of traditional RGB tracking. However, existing multimodal trackers mainly focus on the fusion and enhancement of spatial features or merely leverage the sparse temporal relationships between video frames. These approaches do not fully exploit the temporal correlations in multimodal videos, making it difficult to capture the dynamic changes and motion information of targets in complex scenarios. To alleviate this problem, we propose a unified multimodal spatial-temporal tracking approach named STTrack. In contrast to previous paradigms that solely relied on updating reference information, we introduced a temporal state generator (TSG) that continuously generates a sequence of tokens containing multimodal temporal information. These temporal information tokens are used to guide the localization of the target in the next time state, establish long-range contextual relationships between video frames, and capture the temporal trajectory of the target. Furthermore, at the spatial level, we introduced the mamba fusion and background suppression interactive (BSI) modules. These modules establish a dual-stage mechanism for coordinating information interaction and fusion between modalities. Extensive comparisons on five benchmark datasets illustrate that STTrack achieves state-of-the-art performance across various multimodal tracking scenarios. Code is available at: https://github.com/NJU-PCALab/STTrack.
Personalized federated learning based on feature fusion
Jun 24, 2024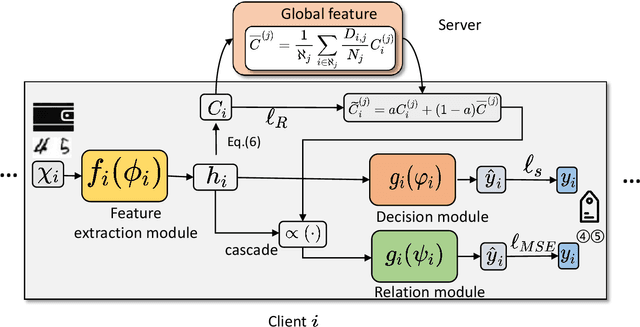
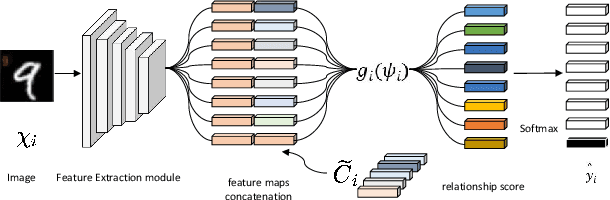
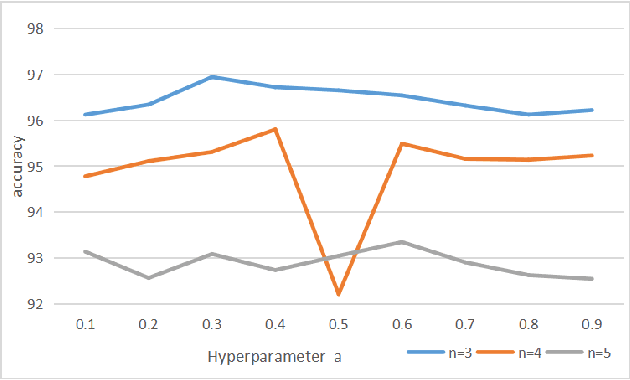
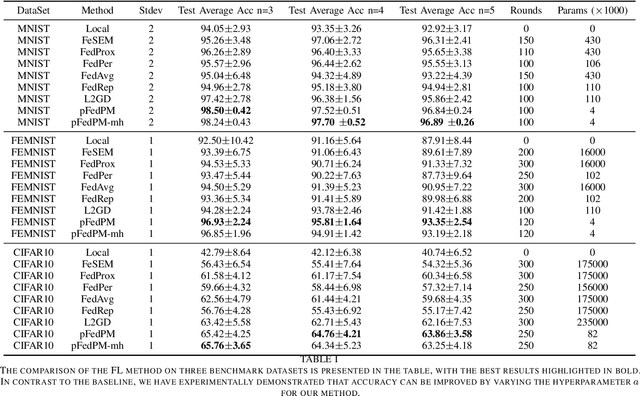
Federated learning enables distributed clients to collaborate on training while storing their data locally to protect client privacy. However, due to the heterogeneity of data, models, and devices, the final global model may need to perform better for tasks on each client. Communication bottlenecks, data heterogeneity, and model heterogeneity have been common challenges in federated learning. In this work, we considered a label distribution skew problem, a type of data heterogeneity easily overlooked. In the context of classification, we propose a personalized federated learning approach called pFedPM. In our process, we replace traditional gradient uploading with feature uploading, which helps reduce communication costs and allows for heterogeneous client models. These feature representations play a role in preserving privacy to some extent. We use a hyperparameter $a$ to mix local and global features, which enables us to control the degree of personalization. We also introduced a relation network as an additional decision layer, which provides a non-linear learnable classifier to predict labels. Experimental results show that, with an appropriate setting of $a$, our scheme outperforms several recent FL methods on MNIST, FEMNIST, and CRIFAR10 datasets and achieves fewer communications.