 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Cognitive Graphs Meet LLMs: BDEI Cognitive Pathways for Panic Emotional Arousal Prediction
Jun 16, 2026Predicting individual panic emotional arousal timing before manifestation is essential for proactive emergency intervention. Existing methods incorporate cognitive elements but none explicitly model the emotional arousal process, making them ill-suited for emotional arousal timing prediction. We argue that grounding prediction in appraisal emotion theory is necessary because it explicitly models this process, but three problems must be solved. (1) Appraisal theory posits that emotion arises from simultaneous evaluation across multiple threat dimensions, yet no prior work fuses these inputs into risk perception. (2) Existing cognitive models lack an Emotion node, decoupling threat appraisal from emotional arousal and forcing emotions to be inferred indirectly from behaviors. (3) Given their generalizable cognitive reasoning, current approaches adopt LLMs as the primary decision-maker, yet overlook the fragility and hallucination-proneness of their outputs. To address these issues, we introduce PanicCognitivePath (PCP), a framework that addresses all three. A Psychological Safety Distance (PSD) model, grounded in psychological distance theory, maps four-domain signals into a unified risk metric as the entry condition for subsequent cognitive reasoning. An explicit Emotion node grounded in appraisal emotion theory is introduced into BDI, forming a Belief-Desire-Emotion-Intention (BDEI) pathway. Agents whose risk metric exceeds the PSD threshold enter this pathway, coupling threat appraisal directly to emotional arousal. The BDEI pathway governs all state transitions while the LLM is confined to parameter estimation for the Belief-to-Desire transition, confining hallucinations to a single step and preventing error propagation. Experiments on Hurricane Sandy show PCP improves arousal timing accuracy by 10.68% over baselines, reduces peak count error to 7.07%.
SnapGuard: Lightweight Prompt Injection Detection for Screenshot-Based Web Agents
Apr 28, 2026Web agents have emerged as an effective paradigm for automating interactions with complex web environments, yet remain vulnerable to prompt injection attacks that embed malicious instructions into webpage content to induce unintended actions. This threat is further amplified for screenshot-based web agents, which operate on rendered visual webpages rather than structured textual representations, making predominant text-centric defenses ineffective. Although multimodal detection methods have been explored, they often rely on large vision-language models (VLMs), incurring significant computational overhead. The bottleneck lies in the complexity of modern webpages: VLMs must comprehend the global semantics of an entire page, resulting in substantial inference time and GPU memory usage. This raises a critical question: can we detect prompt injection attacks from screenshots in a lightweight manner? In this paper, we observe that injected webpages exhibit distinct characteristics compared to benign ones from both visual and textual perspectives. Building on this insight, we propose SnapGuard, a lightweight yet accurate method that reformulates prompt injection detection as multimodal representation analysis over webpage screenshots. SnapGuard leverages two complementary signals: a visual stability indicator that identifies abnormally smooth gradient distributions induced by malicious content, and action-oriented textual signals recovered via contrast-polarity reversal. Extensive evaluations across eight attacks and two benign settings demonstrate that SnapGuard achieves an F1 score of 0.75, outperforming GPT-4o-prompt while being 8x faster (1.81s vs. 14.50s) and introducing no additional memory overhead.
Understanding Model Merging: A Unified Generalization Framework for Heterogeneous Experts
Jan 29, 2026Model merging efficiently aggregates capabilities from multiple fine-tuned models into a single one, operating purely in parameter space without original data or expensive re-computation. Despite empirical successes, a unified theory for its effectiveness under heterogeneous finetuning hyperparameters (e.g., varying learning rates, batch sizes) remains missing. Moreover, the lack of hyperparameter transparency in open-source fine-tuned models makes it difficult to predict merged-model performance, leaving practitioners without guidance on how to fine-tune merge-friendly experts. To address those two challenges, we employ $L_2$-Stability theory under heterogeneous hyperparameter environments to analyze the generalization of the merged model $\boldsymbol{x}_{avg}$. This pioneering analysis yields two key contributions: (i) \textit{A unified theoretical framework} is provided to explain existing merging algorithms, revealing how they optimize specific terms in our bound, thus offering a strong theoretical foundation for empirical observations. (ii) \textit{Actionable recommendations} are proposed for practitioners to strategically fine-tune expert models, enabling the construction of merge-friendly models within the pretraining-to-finetuning pipeline. Extensive experiments on the ResNet/Vit family across 20/8 visual classification tasks, involving thousands of finetuning models, robustly confirm the impact of different hyperparameters on the generalization of $\boldsymbol{x}_{avg}$ predicted by our theoretical results.
CityCube: Benchmarking Cross-view Spatial Reasoning on Vision-Language Models in Urban Environments
Jan 20, 2026Cross-view spatial reasoning is essential for embodied AI, underpinning spatial understanding, mental simulation and planning in complex environments. Existing benchmarks primarily emphasize indoor or street settings, overlooking the unique challenges of open-ended urban spaces characterized by rich semantics, complex geometries, and view variations. To address this, we introduce CityCube, a systematic benchmark designed to probe cross-view reasoning capabilities of current VLMs in urban settings. CityCube integrates four viewpoint dynamics to mimic camera movements and spans a wide spectrum of perspectives from multiple platforms, e.g., vehicles, drones and satellites. For a comprehensive assessment, it features 5,022 meticulously annotated multi-view QA pairs categorized into five cognitive dimensions and three spatial relation expressions. A comprehensive evaluation of 33 VLMs reveals a significant performance disparity with humans: even large-scale models struggle to exceed 54.1% accuracy, remaining 34.2% below human performance. By contrast, small-scale fine-tuned VLMs achieve over 60.0% accuracy, highlighting the necessity of our benchmark. Further analyses indicate the task correlations and fundamental cognitive disparity between VLMs and human-like reasoning.
Unveiling the Power of Multiple Gossip Steps: A Stability-Based Generalization Analysis in Decentralized Training
Oct 09, 2025Decentralized training removes the centralized server, making it a communication-efficient approach that can significantly improve training efficiency, but it often suffers from degraded performance compared to centralized training. Multi-Gossip Steps (MGS) serve as a simple yet effective bridge between decentralized and centralized training, significantly reducing experiment performance gaps. However, the theoretical reasons for its effectiveness and whether this gap can be fully eliminated by MGS remain open questions. In this paper, we derive upper bounds on the generalization error and excess error of MGS using stability analysis, systematically answering these two key questions. 1). Optimization Error Reduction: MGS reduces the optimization error bound at an exponential rate, thereby exponentially tightening the generalization error bound and enabling convergence to better solutions. 2). Gap to Centralization: Even as MGS approaches infinity, a non-negligible gap in generalization error remains compared to centralized mini-batch SGD ($\mathcal{O}(T^{\frac{c\beta}{c\beta +1}}/{n m})$ in centralized and $\mathcal{O}(T^{\frac{2c\beta}{2c\beta +2}}/{n m^{\frac{1}{2c\beta +2}}})$ in decentralized). Furthermore, we provide the first unified analysis of how factors like learning rate, data heterogeneity, node count, per-node sample size, and communication topology impact the generalization of MGS under non-convex settings without the bounded gradients assumption, filling a critical theoretical gap in decentralized training. Finally, promising experiments on CIFAR datasets support our theoretical findings.
Learn to Relax with Large Language Models: Solving Nonlinear Combinatorial Optimization Problems via Bidirectional Coevolution
Sep 16, 2025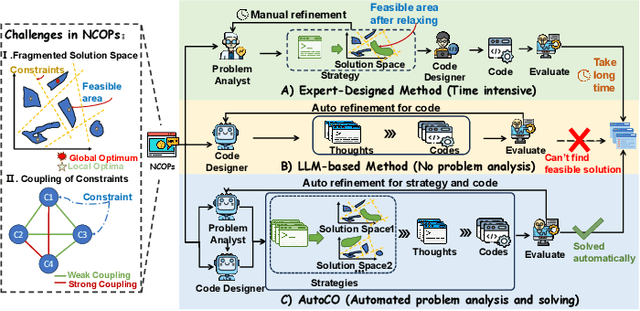



Nonlinear Combinatorial Optimization Problems (NCOPs) present a formidable computational hurdle in practice, as their nonconvex nature gives rise to multi-modal solution spaces that defy efficient optimization. Traditional constraint relaxation approaches rely heavily on expert-driven, iterative design processes that lack systematic automation and scalable adaptability. While recent Large Language Model (LLM)-based optimization methods show promise for autonomous problem-solving, they predominantly function as passive constraint validators rather than proactive strategy architects, failing to handle the sophisticated constraint interactions inherent to NCOPs.To address these limitations, we introduce the first end-to-end \textbf{Auto}mated \textbf{C}onstraint \textbf{O}ptimization (AutoCO) method, which revolutionizes NCOPs resolution through learning to relax with LLMs.Specifically, we leverage structured LLM reasoning to generate constraint relaxation strategies, which are dynamically evolving with algorithmic principles and executable code through a unified triple-representation scheme. We further establish a novel bidirectional (global-local) coevolution mechanism that synergistically integrates Evolutionary Algorithms for intensive local refinement with Monte Carlo Tree Search for systematic global strategy space exploration, ensuring optimal balance between intensification and diversification in fragmented solution spaces. Finally, comprehensive experiments on three challenging NCOP benchmarks validate AutoCO's consistent effectiveness and superior performance over the baselines.
Psychology-driven LLM Agents for Explainable Panic Prediction on Social Media during Sudden Disaster Events
May 22, 2025During sudden disaster events, accurately predicting public panic sentiment on social media is crucial for proactive governance and crisis management. Current efforts on this problem face three main challenges: lack of finely annotated data hinders emotion prediction studies, unmodeled risk perception causes prediction inaccuracies, and insufficient interpretability of panic formation mechanisms. We address these issues by proposing a Psychology-driven generative Agent framework (PsychoAgent) for explainable panic prediction based on emotion arousal theory. Specifically, we first construct a fine-grained open panic emotion dataset (namely COPE) via human-large language models (LLMs) collaboration to mitigate semantic bias. Then, we develop a framework integrating cross-domain heterogeneous data grounded in psychological mechanisms to model risk perception and cognitive differences in emotion generation. To enhance interpretability, we design an LLM-based role-playing agent that simulates individual psychological chains through dedicatedly designed prompts. Experimental results on our annotated dataset show that PsychoAgent improves panic emotion prediction performance by 12.6% to 21.7% compared to baseline models. Furthermore, the explainability and generalization of our approach is validated. Crucially, this represents a paradigm shift from opaque "data-driven fitting" to transparent "role-based simulation with mechanistic interpretation" for panic emotion prediction during emergencies. Our implementation is publicly available at: https://anonymous.4open.science/r/PsychoAgent-19DD.
Towards Autonomous UAV Visual Object Search in City Space: Benchmark and Agentic Methodology
May 14, 2025Aerial Visual Object Search (AVOS) tasks in urban environments require Unmanned Aerial Vehicles (UAVs) to autonomously search for and identify target objects using visual and textual cues without external guidance. Existing approaches struggle in complex urban environments due to redundant semantic processing, similar object distinction, and the exploration-exploitation dilemma. To bridge this gap and support the AVOS task, we introduce CityAVOS, the first benchmark dataset for autonomous search of common urban objects. This dataset comprises 2,420 tasks across six object categories with varying difficulty levels, enabling comprehensive evaluation of UAV agents' search capabilities. To solve the AVOS tasks, we also propose PRPSearcher (Perception-Reasoning-Planning Searcher), a novel agentic method powered by multi-modal large language models (MLLMs) that mimics human three-tier cognition. Specifically, PRPSearcher constructs three specialized maps: an object-centric dynamic semantic map enhancing spatial perception, a 3D cognitive map based on semantic attraction values for target reasoning, and a 3D uncertainty map for balanced exploration-exploitation search. Also, our approach incorporates a denoising mechanism to mitigate interference from similar objects and utilizes an Inspiration Promote Thought (IPT) prompting mechanism for adaptive action planning. Experimental results on CityAVOS demonstrate that PRPSearcher surpasses existing baselines in both success rate and search efficiency (on average: +37.69% SR, +28.96% SPL, -30.69% MSS, and -46.40% NE). While promising, the performance gap compared to humans highlights the need for better semantic reasoning and spatial exploration capabilities in AVOS tasks. This work establishes a foundation for future advances in embodied target search. Dataset and source code are available at https://anonymous.4open.science/r/CityAVOS-3DF8.
GeoNav: Empowering MLLMs with Explicit Geospatial Reasoning Abilities for Language-Goal Aerial Navigation
Apr 13, 2025Language-goal aerial navigation is a critical challenge in embodied AI, requiring UAVs to localize targets in complex environments such as urban blocks based on textual specification. Existing methods, often adapted from indoor navigation, struggle to scale due to limited field of view, semantic ambiguity among objects, and lack of structured spatial reasoning. In this work, we propose GeoNav, a geospatially aware multimodal agent to enable long-range navigation. GeoNav operates in three phases-landmark navigation, target search, and precise localization-mimicking human coarse-to-fine spatial strategies. To support such reasoning, it dynamically builds two different types of spatial memory. The first is a global but schematic cognitive map, which fuses prior textual geographic knowledge and embodied visual cues into a top-down, annotated form for fast navigation to the landmark region. The second is a local but delicate scene graph representing hierarchical spatial relationships between blocks, landmarks, and objects, which is used for definite target localization. On top of this structured representation, GeoNav employs a spatially aware, multimodal chain-of-thought prompting mechanism to enable multimodal large language models with efficient and interpretable decision-making across stages. On the CityNav urban navigation benchmark, GeoNav surpasses the current state-of-the-art by up to 12.53% in success rate and significantly improves navigation efficiency, even in hard-level tasks. Ablation studies highlight the importance of each module, showcasing how geospatial representations and coarse-to-fine reasoning enhance UAV navigation.
SwimVG: Step-wise Multimodal Fusion and Adaption for Visual Grounding
Feb 24, 2025



Visual grounding aims to ground an image region through natural language, which heavily relies on cross-modal alignment. Most existing methods transfer visual/linguistic knowledge separately by fully fine-tuning uni-modal pre-trained models, followed by a simple stack of visual-language transformers for multimodal fusion. However, these approaches not only limit adequate interaction between visual and linguistic contexts, but also incur significant computational costs. Therefore, to address these issues, we explore a step-wise multimodal fusion and adaption framework, namely SwimVG. Specifically, SwimVG proposes step-wise multimodal prompts (Swip) and cross-modal interactive adapters (CIA) for visual grounding, replacing the cumbersome transformer stacks for multimodal fusion. Swip can improve {the} alignment between the vision and language representations step by step, in a token-level fusion manner. In addition, weight-level CIA further promotes multimodal fusion by cross-modal interaction. Swip and CIA are both parameter-efficient paradigms, and they fuse the cross-modal features from shallow to deep layers gradually. Experimental results on four widely-used benchmarks demonstrate that SwimVG achieves remarkable abilities and considerable benefits in terms of efficiency. Our code is available at https://github.com/liuting20/SwimVG.