 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnveiling the Power of Multiple Gossip Steps: A Stability-Based Generalization Analysis in Decentralized Training
Oct 09, 2025Decentralized training removes the centralized server, making it a communication-efficient approach that can significantly improve training efficiency, but it often suffers from degraded performance compared to centralized training. Multi-Gossip Steps (MGS) serve as a simple yet effective bridge between decentralized and centralized training, significantly reducing experiment performance gaps. However, the theoretical reasons for its effectiveness and whether this gap can be fully eliminated by MGS remain open questions. In this paper, we derive upper bounds on the generalization error and excess error of MGS using stability analysis, systematically answering these two key questions. 1). Optimization Error Reduction: MGS reduces the optimization error bound at an exponential rate, thereby exponentially tightening the generalization error bound and enabling convergence to better solutions. 2). Gap to Centralization: Even as MGS approaches infinity, a non-negligible gap in generalization error remains compared to centralized mini-batch SGD ($\mathcal{O}(T^{\frac{c\beta}{c\beta +1}}/{n m})$ in centralized and $\mathcal{O}(T^{\frac{2c\beta}{2c\beta +2}}/{n m^{\frac{1}{2c\beta +2}}})$ in decentralized). Furthermore, we provide the first unified analysis of how factors like learning rate, data heterogeneity, node count, per-node sample size, and communication topology impact the generalization of MGS under non-convex settings without the bounded gradients assumption, filling a critical theoretical gap in decentralized training. Finally, promising experiments on CIFAR datasets support our theoretical findings.
SecEncoder: Logs are All You Need in Security
Nov 12, 2024

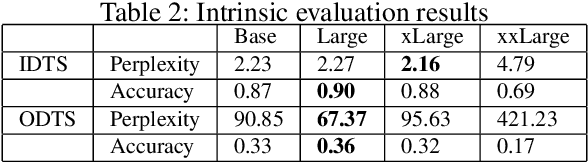

Large and Small Language Models (LMs) are typically pretrained using extensive volumes of text, which are sourced from publicly accessible platforms such as Wikipedia, Book Corpus, or through web scraping. These models, due to their exposure to a wide range of language data, exhibit impressive generalization capabilities and can perform a multitude of tasks simultaneously. However, they often fall short when it comes to domain-specific tasks due to their broad training data. This paper introduces SecEncoder, a specialized small language model that is pretrained using security logs. SecEncoder is designed to address the domain-specific limitations of general LMs by focusing on the unique language and patterns found in security logs. Experimental results indicate that SecEncoder outperforms other LMs, such as BERTlarge, DeBERTa-v3-large and OpenAI's Embedding (textembedding-ada-002) models, which are pretrained mainly on natural language, across various tasks. Furthermore, although SecEncoder is primarily pretrained on log data, it outperforms models pretrained on natural language for a range of tasks beyond log analysis, such as incident prioritization and threat intelligence document retrieval. This suggests that domain specific pretraining with logs can significantly enhance the performance of LMs in security. These findings pave the way for future research into security-specific LMs and their potential applications.
TIPS: Threat Actor Informed Prioritization of Applications using SecEncoder
Nov 12, 2024This paper introduces TIPS: Threat Actor Informed Prioritization using SecEncoder, a specialized language model for security. TIPS combines the strengths of both encoder and decoder language models to detect and prioritize compromised applications. By integrating threat actor intelligence, TIPS enhances the accuracy and relevance of its detections. Extensive experiments with a real-world benchmark dataset of applications demonstrate TIPS's high efficacy, achieving an F-1 score of 0.90 in identifying malicious applications. Additionally, in real-world scenarios, TIPS significantly reduces the backlog of investigations for security analysts by 87%, thereby streamlining the threat response process and improving overall security posture.
Boosting the Performance of Decentralized Federated Learning via Catalyst Acceleration
Oct 09, 2024



Decentralized Federated Learning has emerged as an alternative to centralized architectures due to its faster training, privacy preservation, and reduced communication overhead. In decentralized communication, the server aggregation phase in Centralized Federated Learning shifts to the client side, which means that clients connect with each other in a peer-to-peer manner. However, compared to the centralized mode, data heterogeneity in Decentralized Federated Learning will cause larger variances between aggregated models, which leads to slow convergence in training and poor generalization performance in tests. To address these issues, we introduce Catalyst Acceleration and propose an acceleration Decentralized Federated Learning algorithm called DFedCata. It consists of two main components: the Moreau envelope function, which primarily addresses parameter inconsistencies among clients caused by data heterogeneity, and Nesterov's extrapolation step, which accelerates the aggregation phase. Theoretically, we prove the optimization error bound and generalization error bound of the algorithm, providing a further understanding of the nature of the algorithm and the theoretical perspectives on the hyperparameter choice. Empirically, we demonstrate the advantages of the proposed algorithm in both convergence speed and generalization performance on CIFAR10/100 with various non-iid data distributions. Furthermore, we also experimentally verify the theoretical properties of DFedCata.
Decentralized Directed Collaboration for Personalized Federated Learning
May 28, 2024Personalized Federated Learning (PFL) is proposed to find the greatest personalized models for each client. To avoid the central failure and communication bottleneck in the server-based FL, we concentrate on the Decentralized Personalized Federated Learning (DPFL) that performs distributed model training in a Peer-to-Peer (P2P) manner. Most personalized works in DPFL are based on undirected and symmetric topologies, however, the data, computation and communication resources heterogeneity result in large variances in the personalized models, which lead the undirected aggregation to suboptimal personalized performance and unguaranteed convergence. To address these issues, we propose a directed collaboration DPFL framework by incorporating stochastic gradient push and partial model personalized, called \textbf{D}ecentralized \textbf{Fed}erated \textbf{P}artial \textbf{G}radient \textbf{P}ush (\textbf{DFedPGP}). It personalizes the linear classifier in the modern deep model to customize the local solution and learns a consensus representation in a fully decentralized manner. Clients only share gradients with a subset of neighbors based on the directed and asymmetric topologies, which guarantees flexible choices for resource efficiency and better convergence. Theoretically, we show that the proposed DFedPGP achieves a superior convergence rate of $\mathcal{O}(\frac{1}{\sqrt{T}})$ in the general non-convex setting, and prove the tighter connectivity among clients will speed up the convergence. The proposed method achieves state-of-the-art (SOTA) accuracy in both data and computation heterogeneity scenarios, demonstrating the efficiency of the directed collaboration and partial gradient push.
LOTUS: Evasive and Resilient Backdoor Attacks through Sub-Partitioning
Mar 25, 2024



Backdoor attack poses a significant security threat to Deep Learning applications. Existing attacks are often not evasive to established backdoor detection techniques. This susceptibility primarily stems from the fact that these attacks typically leverage a universal trigger pattern or transformation function, such that the trigger can cause misclassification for any input. In response to this, recent papers have introduced attacks using sample-specific invisible triggers crafted through special transformation functions. While these approaches manage to evade detection to some extent, they reveal vulnerability to existing backdoor mitigation techniques. To address and enhance both evasiveness and resilience, we introduce a novel backdoor attack LOTUS. Specifically, it leverages a secret function to separate samples in the victim class into a set of partitions and applies unique triggers to different partitions. Furthermore, LOTUS incorporates an effective trigger focusing mechanism, ensuring only the trigger corresponding to the partition can induce the backdoor behavior. Extensive experimental results show that LOTUS can achieve high attack success rate across 4 datasets and 7 model structures, and effectively evading 13 backdoor detection and mitigation techniques. The code is available at https://github.com/Megum1/LOTUS.
Towards More Suitable Personalization in Federated Learning via Decentralized Partial Model Training
May 24, 2023
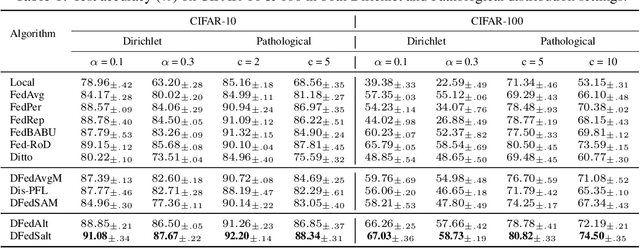

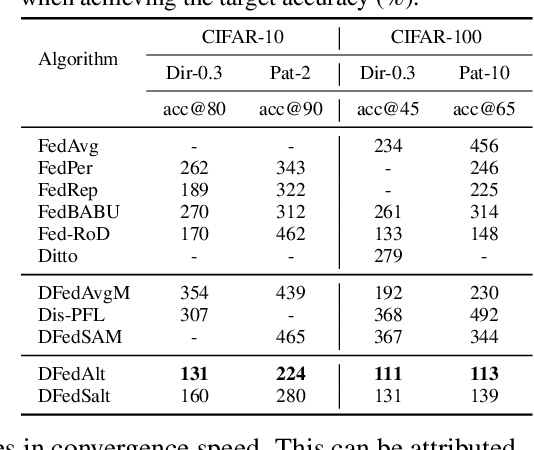
Personalized federated learning (PFL) aims to produce the greatest personalized model for each client to face an insurmountable problem--data heterogeneity in real FL systems. However, almost all existing works have to face large communication burdens and the risk of disruption if the central server fails. Only limited efforts have been used in a decentralized way but still suffers from inferior representation ability due to sharing the full model with its neighbors. Therefore, in this paper, we propose a personalized FL framework with a decentralized partial model training called DFedAlt. It personalizes the "right" components in the modern deep models by alternately updating the shared and personal parameters to train partially personalized models in a peer-to-peer manner. To further promote the shared parameters aggregation process, we propose DFedSalt integrating the local Sharpness Aware Minimization (SAM) optimizer to update the shared parameters. It adds proper perturbation in the direction of the gradient to overcome the shared model inconsistency across clients. Theoretically, we provide convergence analysis of both algorithms in the general non-convex setting for decentralized partial model training in PFL. Our experiments on several real-world data with various data partition settings demonstrate that (i) decentralized training is more suitable for partial personalization, which results in state-of-the-art (SOTA) accuracy compared with the SOTA PFL baselines; (ii) the shared parameters with proper perturbation make partial personalized FL more suitable for decentralized training, where DFedSalt achieves most competitive performance.
Towards the Flatter Landscape and Better Generalization in Federated Learning under Client-level Differential Privacy
May 02, 2023

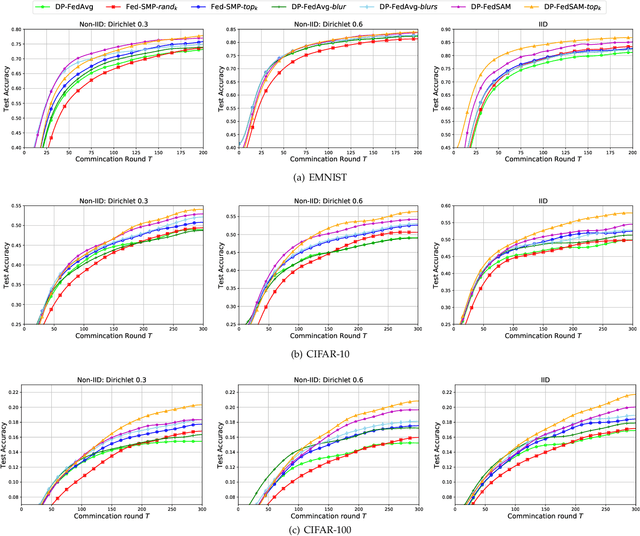

To defend the inference attacks and mitigate the sensitive information leakages in Federated Learning (FL), client-level Differentially Private FL (DPFL) is the de-facto standard for privacy protection by clipping local updates and adding random noise. However, existing DPFL methods tend to make a sharp loss landscape and have poor weight perturbation robustness, resulting in severe performance degradation. To alleviate these issues, we propose a novel DPFL algorithm named DP-FedSAM, which leverages gradient perturbation to mitigate the negative impact of DP. Specifically, DP-FedSAM integrates Sharpness Aware Minimization (SAM) optimizer to generate local flatness models with improved stability and weight perturbation robustness, which results in the small norm of local updates and robustness to DP noise, thereby improving the performance. To further reduce the magnitude of random noise while achieving better performance, we propose DP-FedSAM-$top_k$ by adopting the local update sparsification technique. From the theoretical perspective, we present the convergence analysis to investigate how our algorithms mitigate the performance degradation induced by DP. Meanwhile, we give rigorous privacy guarantees with R\'enyi DP, the sensitivity analysis of local updates, and generalization analysis. At last, we empirically confirm that our algorithms achieve state-of-the-art (SOTA) performance compared with existing SOTA baselines in DPFL.
Detecting Backdoors in Pre-trained Encoders
Mar 23, 2023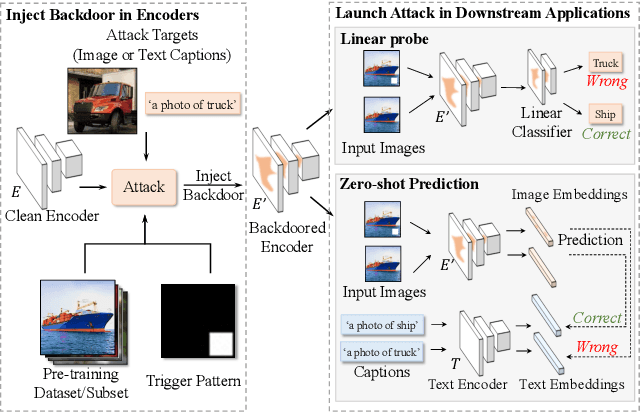



Self-supervised learning in computer vision trains on unlabeled data, such as images or (image, text) pairs, to obtain an image encoder that learns high-quality embeddings for input data. Emerging backdoor attacks towards encoders expose crucial vulnerabilities of self-supervised learning, since downstream classifiers (even further trained on clean data) may inherit backdoor behaviors from encoders. Existing backdoor detection methods mainly focus on supervised learning settings and cannot handle pre-trained encoders especially when input labels are not available. In this paper, we propose DECREE, the first backdoor detection approach for pre-trained encoders, requiring neither classifier headers nor input labels. We evaluate DECREE on over 400 encoders trojaned under 3 paradigms. We show the effectiveness of our method on image encoders pre-trained on ImageNet and OpenAI's CLIP 400 million image-text pairs. Our method consistently has a high detection accuracy even if we have only limited or no access to the pre-training dataset.
Make Landscape Flatter in Differentially Private Federated Learning
Mar 20, 2023



To defend the inference attacks and mitigate the sensitive information leakages in Federated Learning (FL), client-level Differentially Private FL (DPFL) is the de-facto standard for privacy protection by clipping local updates and adding random noise. However, existing DPFL methods tend to make a sharper loss landscape and have poorer weight perturbation robustness, resulting in severe performance degradation. To alleviate these issues, we propose a novel DPFL algorithm named DP-FedSAM, which leverages gradient perturbation to mitigate the negative impact of DP. Specifically, DP-FedSAM integrates Sharpness Aware Minimization (SAM) optimizer to generate local flatness models with better stability and weight perturbation robustness, which results in the small norm of local updates and robustness to DP noise, thereby improving the performance. From the theoretical perspective, we analyze in detail how DP-FedSAM mitigates the performance degradation induced by DP. Meanwhile, we give rigorous privacy guarantees with R\'enyi DP and present the sensitivity analysis of local updates. At last, we empirically confirm that our algorithm achieves state-of-the-art (SOTA) performance compared with existing SOTA baselines in DPFL.