 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeElijah: Eliminating Backdoors Injected in Diffusion Models via Distribution Shift
Nov 27, 2023Diffusion models (DM) have become state-of-the-art generative models because of their capability to generate high-quality images from noises without adversarial training. However, they are vulnerable to backdoor attacks as reported by recent studies. When a data input (e.g., some Gaussian noise) is stamped with a trigger (e.g., a white patch), the backdoored model always generates the target image (e.g., an improper photo). However, effective defense strategies to mitigate backdoors from DMs are underexplored. To bridge this gap, we propose the first backdoor detection and removal framework for DMs. We evaluate our framework Elijah on hundreds of DMs of 3 types including DDPM, NCSN and LDM, with 13 samplers against 3 existing backdoor attacks. Extensive experiments show that our approach can have close to 100% detection accuracy and reduce the backdoor effects to close to zero without significantly sacrificing the model utility.
POSIT: Promotion of Semantic Item Tail via Adversarial Learning
Aug 07, 2023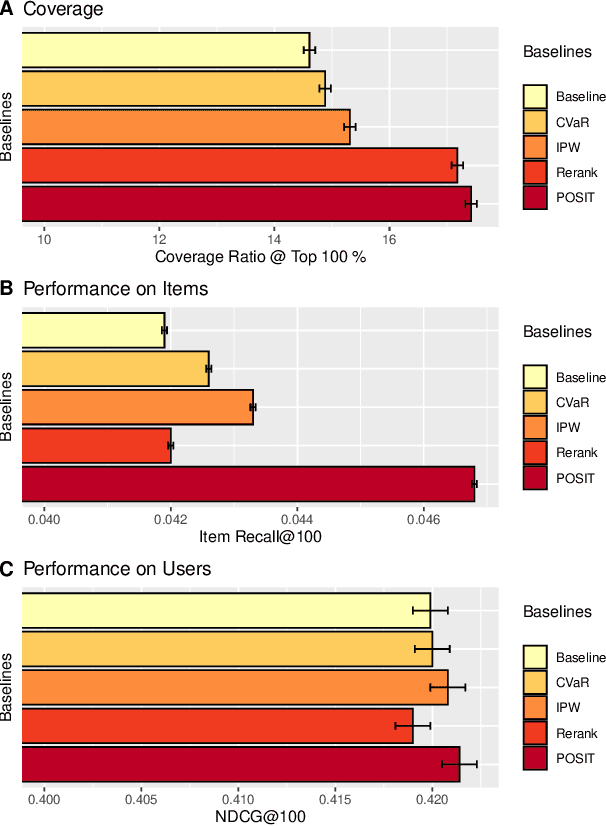
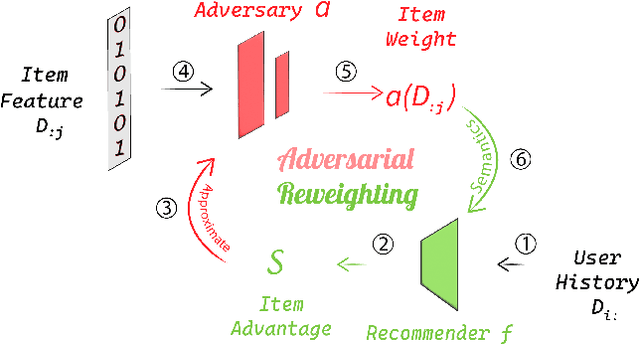
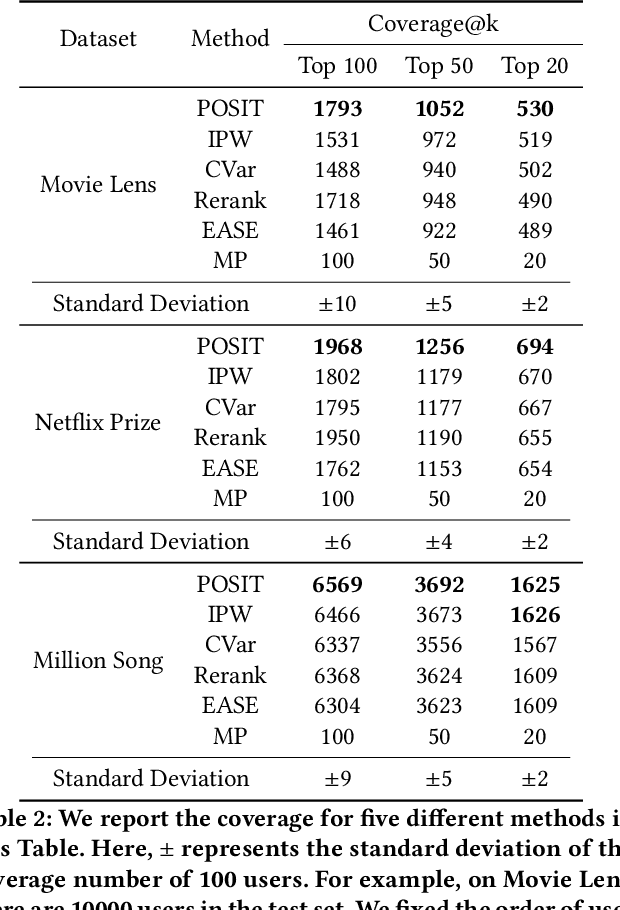
In many recommender problems, a handful of popular items (e.g. movies/TV shows, news etc.) can be dominant in recommendations for many users. However, we know that in a large catalog of items, users are likely interested in more than what is popular. The dominance of popular items may mean that users will not see items they would likely enjoy. In this paper, we propose a technique to overcome this problem using adversarial machine learning. We define a metric to translate user-level utility metric in terms of an advantage/disadvantage over items. We subsequently use that metric in an adversarial learning framework to systematically promote disadvantaged items. The resulting algorithm identifies semantically meaningful items that get promoted in the learning algorithm. In the empirical study, we evaluate the proposed technique on three publicly available datasets and four competitive baselines. The result shows that our proposed method not only improves the coverage, but also, surprisingly, improves the overall performance.
BEAGLE: Forensics of Deep Learning Backdoor Attack for Better Defense
Jan 16, 2023
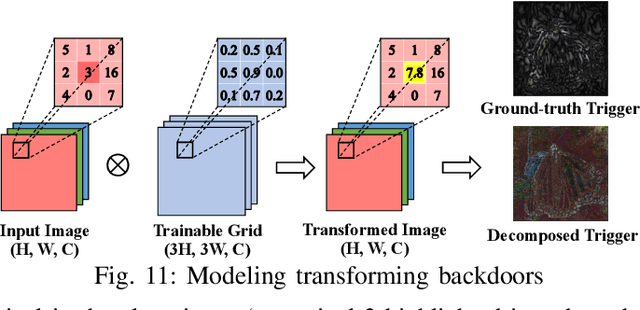
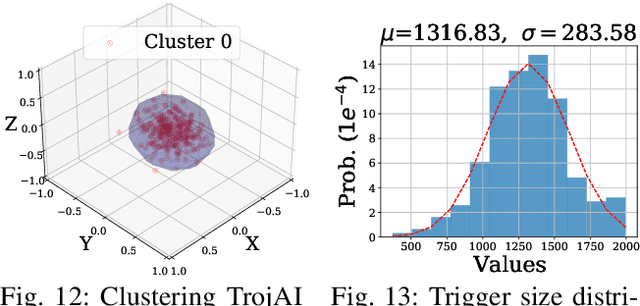
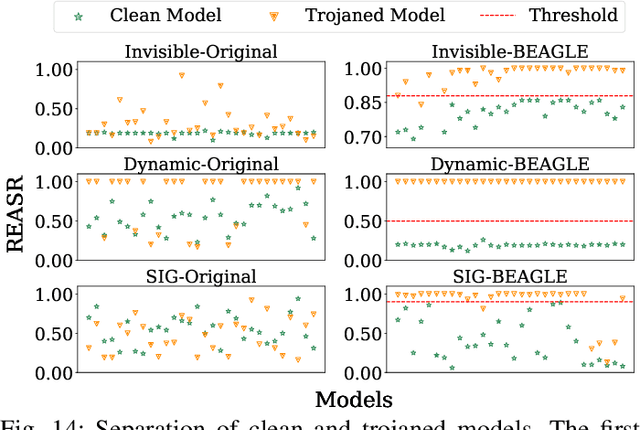
Deep Learning backdoor attacks have a threat model similar to traditional cyber attacks. Attack forensics, a critical counter-measure for traditional cyber attacks, is hence of importance for defending model backdoor attacks. In this paper, we propose a novel model backdoor forensics technique. Given a few attack samples such as inputs with backdoor triggers, which may represent different types of backdoors, our technique automatically decomposes them to clean inputs and the corresponding triggers. It then clusters the triggers based on their properties to allow automatic attack categorization and summarization. Backdoor scanners can then be automatically synthesized to find other instances of the same type of backdoor in other models. Our evaluation on 2,532 pre-trained models, 10 popular attacks, and comparison with 9 baselines show that our technique is highly effective. The decomposed clean inputs and triggers closely resemble the ground truth. The synthesized scanners substantially outperform the vanilla versions of existing scanners that can hardly generalize to different kinds of attacks.
FLIP: A Provable Defense Framework for Backdoor Mitigation in Federated Learning
Oct 23, 2022

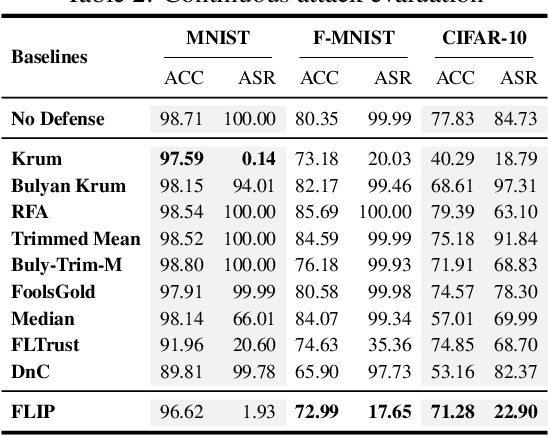

Federated Learning (FL) is a distributed learning paradigm that enables different parties to train a model together for high quality and strong privacy protection. In this scenario, individual participants may get compromised and perform backdoor attacks by poisoning the data (or gradients). Existing work on robust aggregation and certified FL robustness does not study how hardening benign clients can affect the global model (and the malicious clients). In this work, we theoretically analyze the connection among cross-entropy loss, attack success rate, and clean accuracy in this setting. Moreover, we propose a trigger reverse engineering based defense and show that our method can achieve robustness improvement with guarantee (i.e., reducing the attack success rate) without affecting benign accuracy. We conduct comprehensive experiments across different datasets and attack settings. Our results on eight competing SOTA defense methods show the empirical superiority of our method on both single-shot and continuous FL backdoor attacks.
DECK: Model Hardening for Defending Pervasive Backdoors
Jun 18, 2022


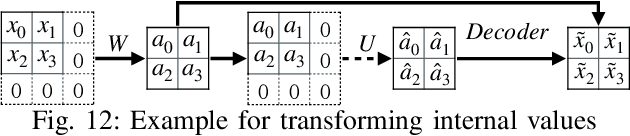
Pervasive backdoors are triggered by dynamic and pervasive input perturbations. They can be intentionally injected by attackers or naturally exist in normally trained models. They have a different nature from the traditional static and localized backdoors that can be triggered by perturbing a small input area with some fixed pattern, e.g., a patch with solid color. Existing defense techniques are highly effective for traditional backdoors. However, they may not work well for pervasive backdoors, especially regarding backdoor removal and model hardening. In this paper, we propose a novel model hardening technique against pervasive backdoors, including both natural and injected backdoors. We develop a general pervasive attack based on an encoder-decoder architecture enhanced with a special transformation layer. The attack can model a wide range of existing pervasive backdoor attacks and quantify them by class distances. As such, using the samples derived from our attack in adversarial training can harden a model against these backdoor vulnerabilities. Our evaluation on 9 datasets with 15 model structures shows that our technique can enlarge class distances by 59.65% on average with less than 1% accuracy degradation and no robustness loss, outperforming five hardening techniques such as adversarial training, universal adversarial training, MOTH, etc. It can reduce the attack success rate of six pervasive backdoor attacks from 99.06% to 1.94%, surpassing seven state-of-the-art backdoor removal techniques.
Constrained Optimization with Dynamic Bound-scaling for Effective NLPBackdoor Defense
Feb 11, 2022


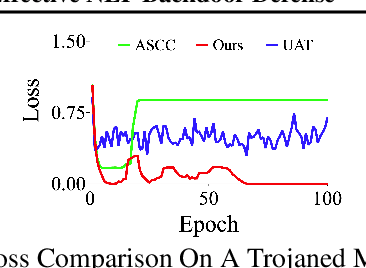
We develop a novel optimization method for NLPbackdoor inversion. We leverage a dynamically reducing temperature coefficient in the softmax function to provide changing loss landscapes to the optimizer such that the process gradually focuses on the ground truth trigger, which is denoted as a one-hot value in a convex hull. Our method also features a temperature rollback mechanism to step away from local optimals, exploiting the observation that local optimals can be easily deter-mined in NLP trigger inversion (while not in general optimization). We evaluate the technique on over 1600 models (with roughly half of them having injected backdoors) on 3 prevailing NLP tasks, with 4 different backdoor attacks and 7 architectures. Our results show that the technique is able to effectively and efficiently detect and remove backdoors, outperforming 4 baseline methods.
Backdoor Scanning for Deep Neural Networks through K-Arm Optimization
Feb 09, 2021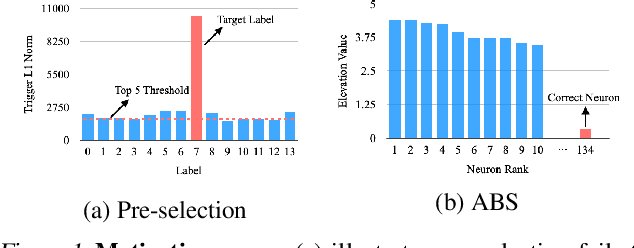

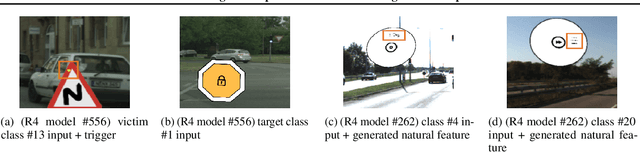

Back-door attack poses a severe threat to deep learning systems. It injects hidden malicious behaviors to a model such that any input stamped with a special pattern can trigger such behaviors. Detecting back-door is hence of pressing need. Many existing defense techniques use optimization to generate the smallest input pattern that forces the model to misclassify a set of benign inputs injected with the pattern to a target label. However, the complexity is quadratic to the number of class labels such that they can hardly handle models with many classes. Inspired by Multi-Arm Bandit in Reinforcement Learning, we propose a K-Arm optimization method for backdoor detection. By iteratively and stochastically selecting the most promising labels for optimization with the guidance of an objective function, we substantially reduce the complexity, allowing to handle models with many classes. Moreover, by iteratively refining the selection of labels to optimize, it substantially mitigates the uncertainty in choosing the right labels, improving detection accuracy. At the time of submission, the evaluation of our method on over 4000 models in the IARPA TrojAI competition from round 1 to the latest round 4 achieves top performance on the leaderboard. Our technique also supersedes three state-of-the-art techniques in terms of accuracy and the scanning time needed.
Fundamental Limits of Adversarial Learning
Jul 01, 2020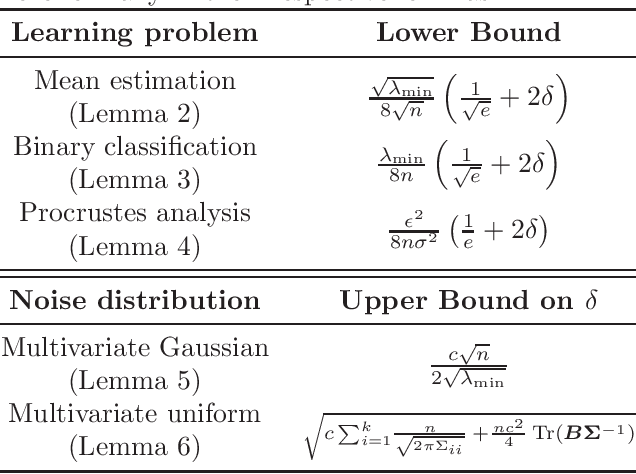
Robustness of machine learning methods is essential for modern practical applications. Given the arms race between attack and defense methods, one may be curious regarding the fundamental limits of any defense mechanism. In this work, we focus on the problem of learning from noise-injected data, where the existing literature falls short by either assuming a specific attack method or by over-specifying the learning problem. We shed light on the information-theoretic limits of adversarial learning without assuming a particular learning process or attacker. Finally, we apply our general bounds to a canonical set of non-trivial learning problems and provide examples of common types of attacks.
D-square-B: Deep Distribution Bound for Natural-looking Adversarial Attack
Jun 12, 2020

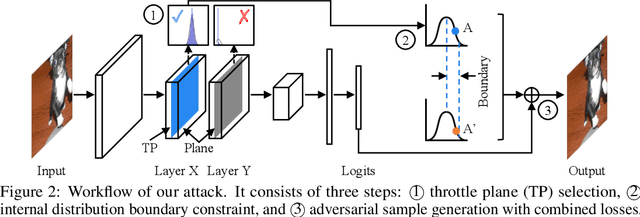
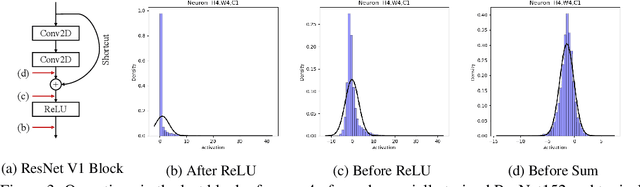
We propose a novel technique that can generate natural-looking adversarial examples by bounding the variations induced for internal activation values in some deep layer(s), through a distribution quantile bound and a polynomial barrier loss function. By bounding model internals instead of individual pixels, our attack admits perturbations closely coupled with the existing features of the original input, allowing the generated examples to be natural-looking while having diverse and often substantial pixel distances from the original input. Enforcing per-neuron distribution quantile bounds allows addressing the non-uniformity of internal activation values. Our evaluation on ImageNet and five different model architecture demonstrates that our attack is quite effective. Compared to the state-of-the-art pixel space attack, semantic attack, and feature space attack, our attack can achieve the same attack success/confidence level while having much more natural-looking adversarial perturbations. These perturbations piggy-back on existing local features and do not have any fixed pixel bounds.
Towards Feature Space Adversarial Attack
Apr 26, 2020

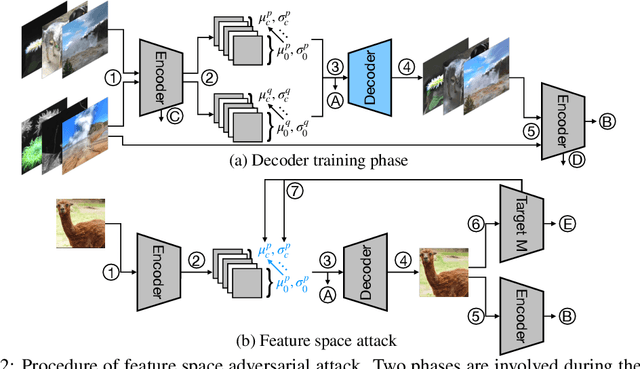
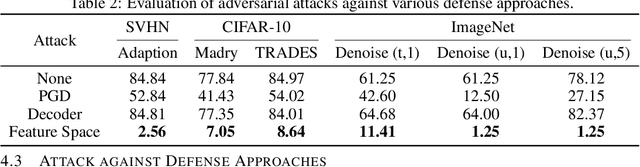
We propose a new type of adversarial attack to Deep Neural Networks (DNNs) for image classification. Different from most existing attacks that directly perturb input pixels. Our attack focuses on perturbing abstract features, more specifically, features that denote styles, including interpretable styles such as vivid colors and sharp outlines, and uninterpretable ones. It induces model misclassfication by injecting style changes insensitive for humans, through an optimization procedure. We show that state-of-the-art adversarial attack detection and defense techniques are ineffective in guarding against feature space attacks.