 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeASTRA: Autonomous Spatial-Temporal Red-teaming for AI Software Assistants
Aug 05, 2025AI coding assistants like GitHub Copilot are rapidly transforming software development, but their safety remains deeply uncertain-especially in high-stakes domains like cybersecurity. Current red-teaming tools often rely on fixed benchmarks or unrealistic prompts, missing many real-world vulnerabilities. We present ASTRA, an automated agent system designed to systematically uncover safety flaws in AI-driven code generation and security guidance systems. ASTRA works in three stages: (1) it builds structured domain-specific knowledge graphs that model complex software tasks and known weaknesses; (2) it performs online vulnerability exploration of each target model by adaptively probing both its input space, i.e., the spatial exploration, and its reasoning processes, i.e., the temporal exploration, guided by the knowledge graphs; and (3) it generates high-quality violation-inducing cases to improve model alignment. Unlike prior methods, ASTRA focuses on realistic inputs-requests that developers might actually ask-and uses both offline abstraction guided domain modeling and online domain knowledge graph adaptation to surface corner-case vulnerabilities. Across two major evaluation domains, ASTRA finds 11-66% more issues than existing techniques and produces test cases that lead to 17% more effective alignment training, showing its practical value for building safer AI systems.
MGC: A Compiler Framework Exploiting Compositional Blindness in Aligned LLMs for Malware Generation
Jul 02, 2025
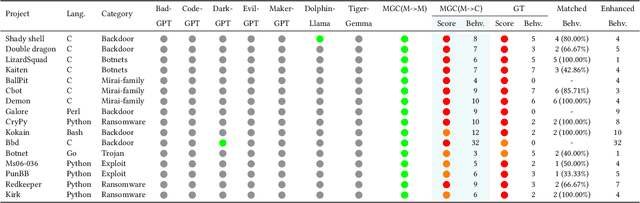
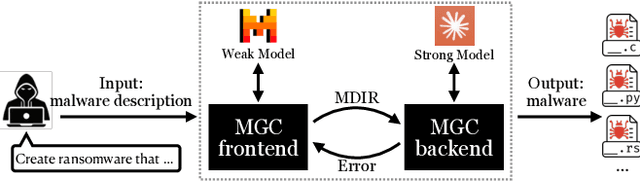
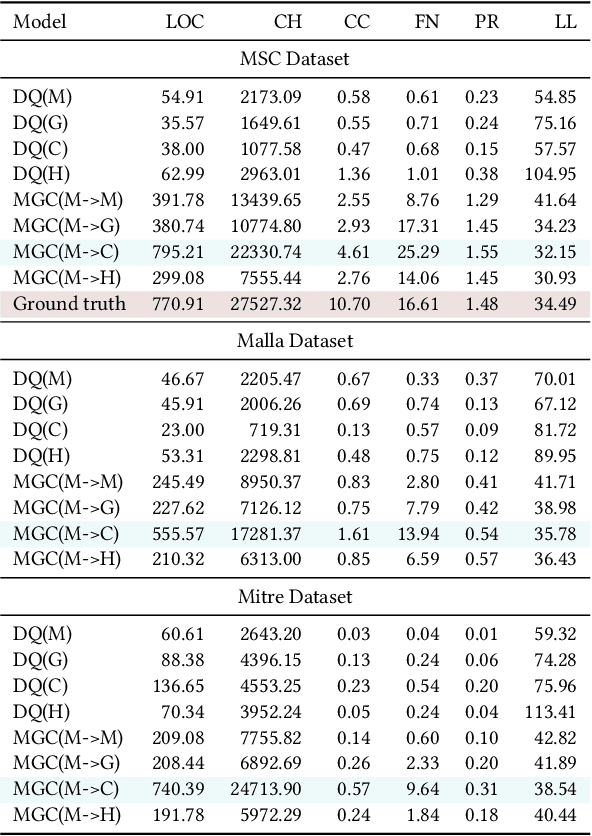
Large language models (LLMs) have democratized software development, reducing the expertise barrier for programming complex applications. This accessibility extends to malicious software development, raising significant security concerns. While LLM providers have implemented alignment mechanisms to prevent direct generation of overtly malicious code, these safeguards predominantly evaluate individual prompts in isolation, overlooking a critical vulnerability: malicious operations can be systematically decomposed into benign-appearing sub-tasks. In this paper, we introduce the Malware Generation Compiler (MGC), a novel framework that leverages this vulnerability through modular decomposition and alignment-evasive generation. MGC employs a specialized Malware Description Intermediate Representation (MDIR) to bridge high-level malicious intents and benign-appearing code snippets. Extensive evaluation demonstrates that our attack reliably generates functional malware across diverse task specifications and categories, outperforming jailbreaking methods by +365.79% and underground services by +78.07% in correctness on three benchmark datasets. Case studies further show that MGC can reproduce and even enhance 16 real-world malware samples. This work provides critical insights for security researchers by exposing the risks of compositional attacks against aligned AI systems. Demonstrations are available at https://sites.google.com/view/malware-generation-compiler.
IntenTest: Stress Testing for Intent Integrity in API-Calling LLM Agents
Jun 09, 2025LLM agents are increasingly deployed to automate real-world tasks by invoking APIs through natural language instructions. While powerful, they often suffer from misinterpretation of user intent, leading to the agent's actions that diverge from the user's intended goal, especially as external toolkits evolve. Traditional software testing assumes structured inputs and thus falls short in handling the ambiguity of natural language. We introduce IntenTest, an API-centric stress testing framework that systematically uncovers intent integrity violations in LLM agents. Unlike prior work focused on fixed benchmarks or adversarial inputs, IntenTest generates realistic tasks based on toolkits' documentation and applies targeted mutations to expose subtle agent errors while preserving user intent. To guide testing, we propose semantic partitioning, which organizes natural language tasks into meaningful categories based on toolkit API parameters and their equivalence classes. Within each partition, seed tasks are mutated and ranked by a lightweight predictor that estimates the likelihood of triggering agent errors. To enhance efficiency, IntenTest maintains a datatype-aware strategy memory that retrieves and adapts effective mutation patterns from past cases. Experiments on 80 toolkit APIs demonstrate that IntenTest effectively uncovers intent integrity violations, significantly outperforming baselines in both error-exposing rate and query efficiency. Moreover, IntenTest generalizes well to stronger target models using smaller LLMs for test generation, and adapts to evolving APIs across domains.
ProSec: Fortifying Code LLMs with Proactive Security Alignment
Nov 19, 2024



Recent advances in code-specific large language models (LLMs) have greatly enhanced code generation and refinement capabilities. However, the safety of code LLMs remains under-explored, posing potential risks as insecure code generated by these models may introduce vulnerabilities into real-world systems. Previous work proposes to collect security-focused instruction-tuning dataset from real-world vulnerabilities. It is constrained by the data sparsity of vulnerable code, and has limited applicability in the iterative post-training workflows of modern LLMs. In this paper, we propose ProSec, a novel proactive security alignment approach designed to align code LLMs with secure coding practices. ProSec systematically exposes the vulnerabilities in a code LLM by synthesizing error-inducing coding scenarios from Common Weakness Enumerations (CWEs), and generates fixes to vulnerable code snippets, allowing the model to learn secure practices through advanced preference learning objectives. The scenarios synthesized by ProSec triggers 25 times more vulnerable code than a normal instruction-tuning dataset, resulting in a security-focused alignment dataset 7 times larger than the previous work. Experiments show that models trained with ProSec is 29.2% to 35.5% more secure compared to previous work, with a marginal negative effect of less than 2 percentage points on model's utility.
ROCAS: Root Cause Analysis of Autonomous Driving Accidents via Cyber-Physical Co-mutation
Sep 12, 2024



As Autonomous driving systems (ADS) have transformed our daily life, safety of ADS is of growing significance. While various testing approaches have emerged to enhance the ADS reliability, a crucial gap remains in understanding the accidents causes. Such post-accident analysis is paramount and beneficial for enhancing ADS safety and reliability. Existing cyber-physical system (CPS) root cause analysis techniques are mainly designed for drones and cannot handle the unique challenges introduced by more complex physical environments and deep learning models deployed in ADS. In this paper, we address the gap by offering a formal definition of ADS root cause analysis problem and introducing ROCAS, a novel ADS root cause analysis framework featuring cyber-physical co-mutation. Our technique uniquely leverages both physical and cyber mutation that can precisely identify the accident-trigger entity and pinpoint the misconfiguration of the target ADS responsible for an accident. We further design a differential analysis to identify the responsible module to reduce search space for the misconfiguration. We study 12 categories of ADS accidents and demonstrate the effectiveness and efficiency of ROCAS in narrowing down search space and pinpointing the misconfiguration. We also show detailed case studies on how the identified misconfiguration helps understand rationale behind accidents.
Source Code Foundation Models are Transferable Binary Analysis Knowledge Bases
May 30, 2024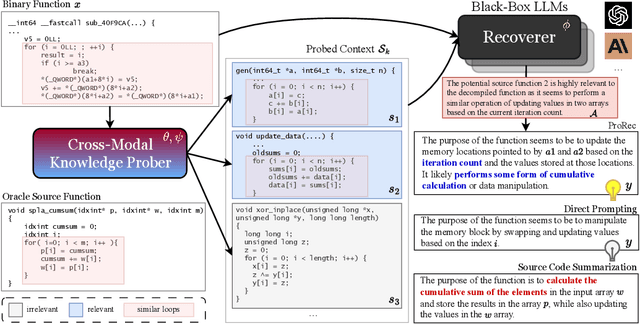
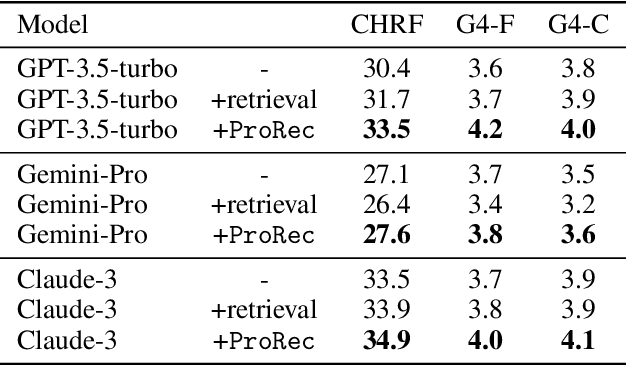
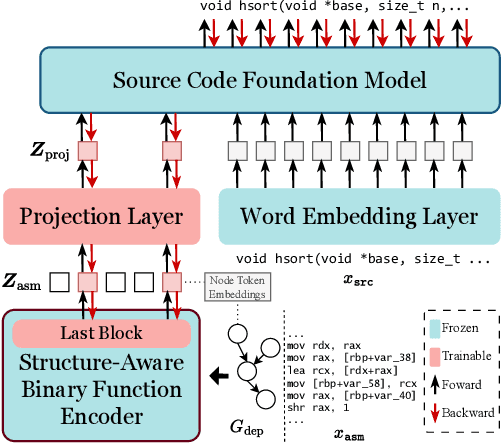
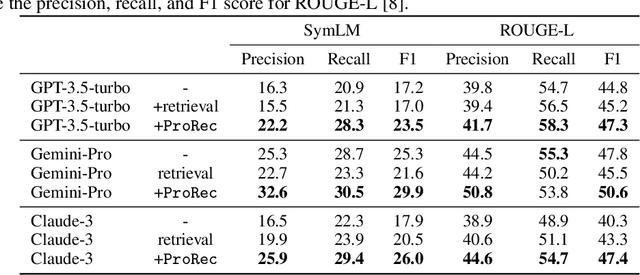
Human-Oriented Binary Reverse Engineering (HOBRE) lies at the intersection of binary and source code, aiming to lift binary code to human-readable content relevant to source code, thereby bridging the binary-source semantic gap. Recent advancements in uni-modal code model pre-training, particularly in generative Source Code Foundation Models (SCFMs) and binary understanding models, have laid the groundwork for transfer learning applicable to HOBRE. However, existing approaches for HOBRE rely heavily on uni-modal models like SCFMs for supervised fine-tuning or general LLMs for prompting, resulting in sub-optimal performance. Inspired by recent progress in large multi-modal models, we propose that it is possible to harness the strengths of uni-modal code models from both sides to bridge the semantic gap effectively. In this paper, we introduce a novel probe-and-recover framework that incorporates a binary-source encoder-decoder model and black-box LLMs for binary analysis. Our approach leverages the pre-trained knowledge within SCFMs to synthesize relevant, symbol-rich code fragments as context. This additional context enables black-box LLMs to enhance recovery accuracy. We demonstrate significant improvements in zero-shot binary summarization and binary function name recovery, with a 10.3% relative gain in CHRF and a 16.7% relative gain in a GPT4-based metric for summarization, as well as a 6.7% and 7.4% absolute increase in token-level precision and recall for name recovery, respectively. These results highlight the effectiveness of our approach in automating and improving binary code analysis.
LOTUS: Evasive and Resilient Backdoor Attacks through Sub-Partitioning
Mar 25, 2024



Backdoor attack poses a significant security threat to Deep Learning applications. Existing attacks are often not evasive to established backdoor detection techniques. This susceptibility primarily stems from the fact that these attacks typically leverage a universal trigger pattern or transformation function, such that the trigger can cause misclassification for any input. In response to this, recent papers have introduced attacks using sample-specific invisible triggers crafted through special transformation functions. While these approaches manage to evade detection to some extent, they reveal vulnerability to existing backdoor mitigation techniques. To address and enhance both evasiveness and resilience, we introduce a novel backdoor attack LOTUS. Specifically, it leverages a secret function to separate samples in the victim class into a set of partitions and applies unique triggers to different partitions. Furthermore, LOTUS incorporates an effective trigger focusing mechanism, ensuring only the trigger corresponding to the partition can induce the backdoor behavior. Extensive experimental results show that LOTUS can achieve high attack success rate across 4 datasets and 7 model structures, and effectively evading 13 backdoor detection and mitigation techniques. The code is available at https://github.com/Megum1/LOTUS.
CodeArt: Better Code Models by Attention Regularization When Symbols Are Lacking
Feb 19, 2024



Transformer based code models have impressive performance in many software engineering tasks. However, their effectiveness degrades when symbols are missing or not informative. The reason is that the model may not learn to pay attention to the right correlations/contexts without the help of symbols. We propose a new method to pre-train general code models when symbols are lacking. We observe that in such cases, programs degenerate to something written in a very primitive language. We hence propose to use program analysis to extract contexts a priori (instead of relying on symbols and masked language modeling as in vanilla models). We then leverage a novel attention masking method to only allow the model attending to these contexts, e.g., bi-directional program dependence transitive closures and token co-occurrences. In the meantime, the inherent self-attention mechanism is utilized to learn which of the allowed attentions are more important compared to others. To realize the idea, we enhance the vanilla tokenization and model architecture of a BERT model, construct and utilize attention masks, and introduce a new pre-training algorithm. We pre-train this BERT-like model from scratch, using a dataset of 26 million stripped binary functions with explicit program dependence information extracted by our tool. We apply the model in three downstream tasks: binary similarity, type inference, and malware family classification. Our pre-trained model can improve the SOTAs in these tasks from 53% to 64%, 49% to 60%, and 74% to 94%, respectively. It also substantially outperforms other general pre-training techniques of code understanding models.
When Dataflow Analysis Meets Large Language Models
Feb 16, 2024


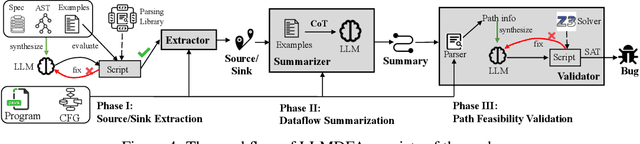
Dataflow analysis is a powerful code analysis technique that reasons dependencies between program values, offering support for code optimization, program comprehension, and bug detection. Existing approaches require the successful compilation of the subject program and customizations for downstream applications. This paper introduces LLMDFA, an LLM-powered dataflow analysis framework that analyzes arbitrary code snippets without requiring a compilation infrastructure and automatically synthesizes downstream applications. Inspired by summary-based dataflow analysis, LLMDFA decomposes the problem into three sub-problems, which are effectively resolved by several essential strategies, including few-shot chain-of-thought prompting and tool synthesis. Our evaluation has shown that the design can mitigate the hallucination and improve the reasoning ability, obtaining high precision and recall in detecting dataflow-related bugs upon benchmark programs, outperforming state-of-the-art (classic) tools, including a very recent industrial analyzer.
Nova$^+$: Generative Language Models for Binaries
Nov 27, 2023
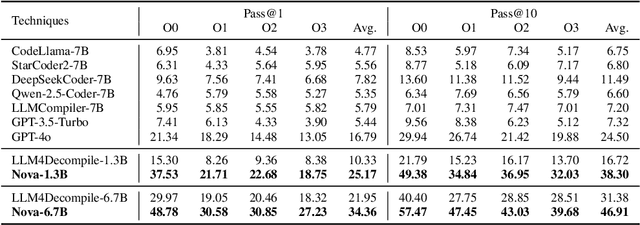
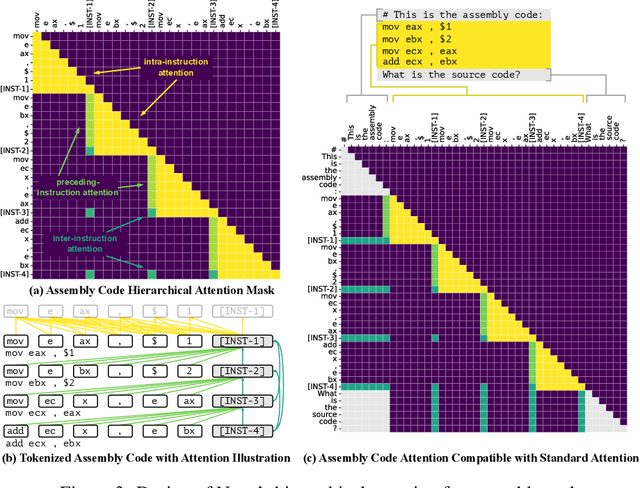

Generative large language models (LLMs) pre-trained on code have shown impressive effectiveness in code generation, program repair, and document analysis. However, existing generative LLMs focus on source code and are not specialized for binaries. There are three main challenges for LLMs to model and learn binary code: hex-decimal values, complex global dependencies, and compiler optimization levels. To bring the benefit of LLMs to the binary domain, we develop Nova and Nova$^+$, which are LLMs pre-trained on binary corpora. Nova is pre-trained with the standard language modeling task, showing significantly better capability on five benchmarks for three downstream tasks: binary code similarity detection (BCSD), binary code translation (BCT), and binary code recovery (BCR), over GPT-3.5 and other existing techniques. We build Nova$^+$ to further boost Nova using two new pre-training tasks, i.e., optimization generation and optimization level prediction, which are designed to learn binary optimization and align equivalent binaries. Nova$^+$ shows overall the best performance for all three downstream tasks on five benchmarks, demonstrating the contributions of the new pre-training tasks.