 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNova$^+$: Generative Language Models for Binaries
Paper and Code
Nov 27, 2023
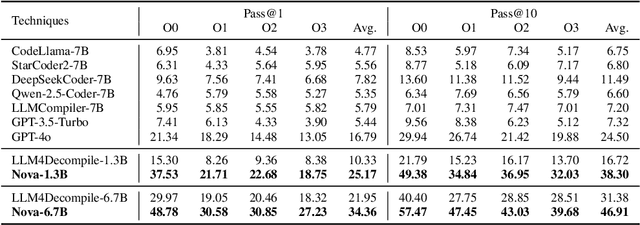
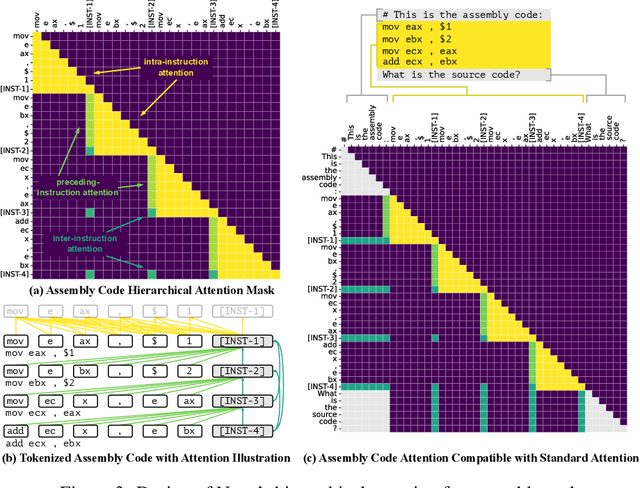

Generative large language models (LLMs) pre-trained on code have shown impressive effectiveness in code generation, program repair, and document analysis. However, existing generative LLMs focus on source code and are not specialized for binaries. There are three main challenges for LLMs to model and learn binary code: hex-decimal values, complex global dependencies, and compiler optimization levels. To bring the benefit of LLMs to the binary domain, we develop Nova and Nova$^+$, which are LLMs pre-trained on binary corpora. Nova is pre-trained with the standard language modeling task, showing significantly better capability on five benchmarks for three downstream tasks: binary code similarity detection (BCSD), binary code translation (BCT), and binary code recovery (BCR), over GPT-3.5 and other existing techniques. We build Nova$^+$ to further boost Nova using two new pre-training tasks, i.e., optimization generation and optimization level prediction, which are designed to learn binary optimization and align equivalent binaries. Nova$^+$ shows overall the best performance for all three downstream tasks on five benchmarks, demonstrating the contributions of the new pre-training tasks.