 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFormal Synthesis of Certifiably Robust Neural Lyapunov-Barrier Certificates
Feb 05, 2026Neural Lyapunov and barrier certificates have recently been used as powerful tools for verifying the safety and stability properties of deep reinforcement learning (RL) controllers. However, existing methods offer guarantees only under fixed ideal unperturbed dynamics, limiting their reliability in real-world applications where dynamics may deviate due to uncertainties. In this work, we study the problem of synthesizing \emph{robust neural Lyapunov barrier certificates} that maintain their guarantees under perturbations in system dynamics. We formally define a robust Lyapunov barrier function and specify sufficient conditions based on Lipschitz continuity that ensure robustness against bounded perturbations. We propose practical training objectives that enforce these conditions via adversarial training, Lipschitz neighborhood bound, and global Lipschitz regularization. We validate our approach in two practically relevant environments, Inverted Pendulum and 2D Docking. The former is a widely studied benchmark, while the latter is a safety-critical task in autonomous systems. We show that our methods significantly improve both certified robustness bounds (up to $4.6$ times) and empirical success rates under strong perturbations (up to $2.4$ times) compared to the baseline. Our results demonstrate effectiveness of training robust neural certificates for safe RL under perturbations in dynamics.
Towards Formal Verification of LLM-Generated Code from Natural Language Prompts
Jul 17, 2025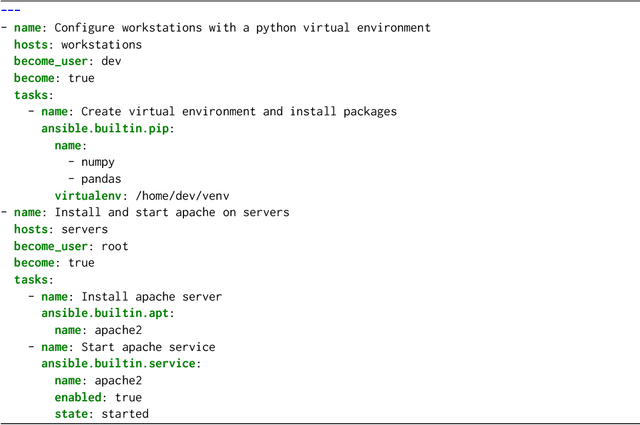
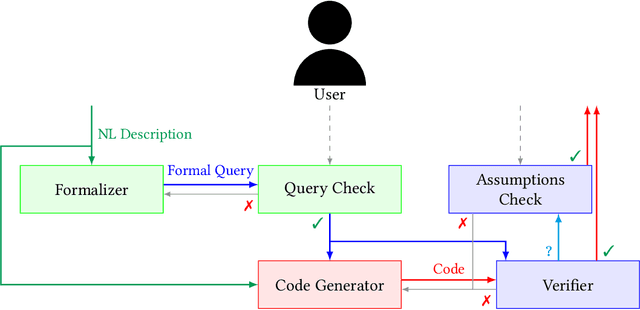
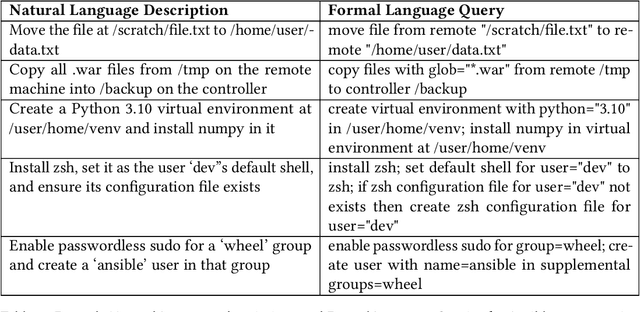
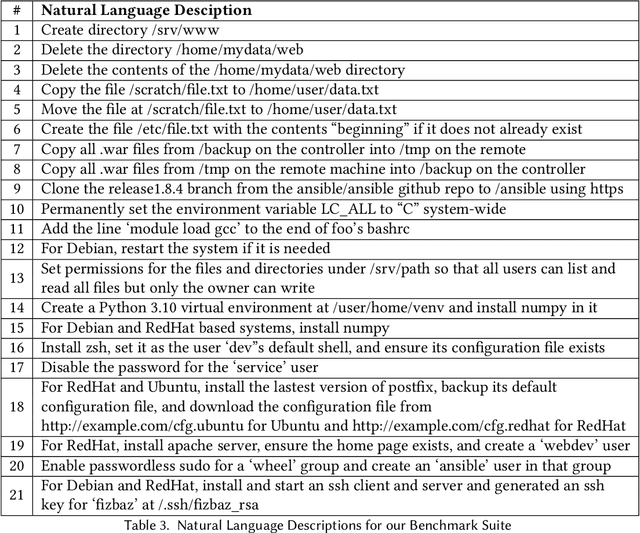
In the past few years LLMs have emerged as a tool that can aid programmers by taking natural language descriptions and generating code based on it. However, LLMs often generate incorrect code that users need to fix and the literature suggests users often struggle to detect these errors. In this work we seek to offer formal guarantees of correctness to LLM generated code; such guarantees could improve the experience of using AI Code Assistants and potentially enable natural language programming for users with little or no programming knowledge. To address this challenge we propose to incorporate a formal query language that can represent a user's intent in a formally defined but natural language-like manner that a user can confirm matches their intent. Then, using such a query we propose to verify LLM generated code to ensure it matches the user's intent. We implement these ideas in our system, Astrogator, for the Ansible programming language which includes such a formal query language, a calculus for representing the behavior of Ansible programs, and a symbolic interpreter which is used for the verification. On a benchmark suite of 21 code-generation tasks, our verifier is able to verify correct code in 83% of cases and identify incorrect code in 92%.
LATTE: Improving Latex Recognition for Tables and Formulae with Iterative Refinement
Sep 21, 2024



Portable Document Format (PDF) files are dominantly used for storing and disseminating scientific research, legal documents, and tax information. LaTeX is a popular application for creating PDF documents. Despite its advantages, LaTeX is not WYSWYG -- what you see is what you get, i.e., the LaTeX source and rendered PDF images look drastically different, especially for formulae and tables. This gap makes it hard to modify or export LaTeX sources for formulae and tables from PDF images, and existing work is still limited. First, prior work generates LaTeX sources in a single iteration and struggles with complex LaTeX formulae. Second, existing work mainly recognizes and extracts LaTeX sources for formulae; and is incapable or ineffective for tables. This paper proposes LATTE, the first iterative refinement framework for LaTeX recognition. Specifically, we propose delta-view as feedback, which compares and pinpoints the differences between a pair of rendered images of the extracted LaTeX source and the expected correct image. Such delta-view feedback enables our fault localization model to localize the faulty parts of the incorrect recognition more accurately and enables our LaTeX refinement model to repair the incorrect extraction more accurately. LATTE improves the LaTeX source extraction accuracy of both LaTeX formulae and tables, outperforming existing techniques as well as GPT-4V by at least 7.07% of exact match, with a success refinement rate of 46.08% (formula) and 25.51% (table).
Nova$^+$: Generative Language Models for Binaries
Nov 27, 2023
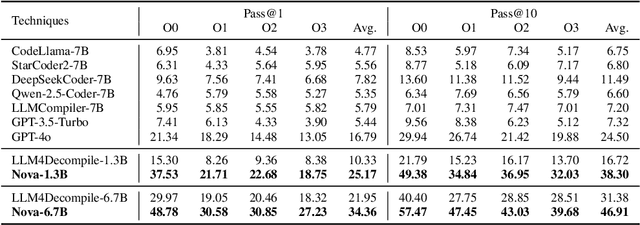
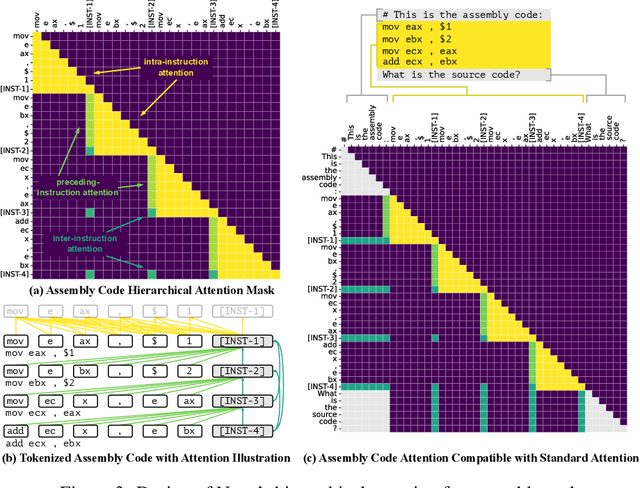

Generative large language models (LLMs) pre-trained on code have shown impressive effectiveness in code generation, program repair, and document analysis. However, existing generative LLMs focus on source code and are not specialized for binaries. There are three main challenges for LLMs to model and learn binary code: hex-decimal values, complex global dependencies, and compiler optimization levels. To bring the benefit of LLMs to the binary domain, we develop Nova and Nova$^+$, which are LLMs pre-trained on binary corpora. Nova is pre-trained with the standard language modeling task, showing significantly better capability on five benchmarks for three downstream tasks: binary code similarity detection (BCSD), binary code translation (BCT), and binary code recovery (BCR), over GPT-3.5 and other existing techniques. We build Nova$^+$ to further boost Nova using two new pre-training tasks, i.e., optimization generation and optimization level prediction, which are designed to learn binary optimization and align equivalent binaries. Nova$^+$ shows overall the best performance for all three downstream tasks on five benchmarks, demonstrating the contributions of the new pre-training tasks.