 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
OpenAI o1 System Card
Dec 21, 2024



The o1 model series is trained with large-scale reinforcement learning to reason using chain of thought. These advanced reasoning capabilities provide new avenues for improving the safety and robustness of our models. In particular, our models can reason about our safety policies in context when responding to potentially unsafe prompts, through deliberative alignment. This leads to state-of-the-art performance on certain benchmarks for risks such as generating illicit advice, choosing stereotyped responses, and succumbing to known jailbreaks. Training models to incorporate a chain of thought before answering has the potential to unlock substantial benefits, while also increasing potential risks that stem from heightened intelligence. Our results underscore the need for building robust alignment methods, extensively stress-testing their efficacy, and maintaining meticulous risk management protocols. This report outlines the safety work carried out for the OpenAI o1 and OpenAI o1-mini models, including safety evaluations, external red teaming, and Preparedness Framework evaluations.
GPT-4o System Card
Oct 25, 2024GPT-4o is an autoregressive omni model that accepts as input any combination of text, audio, image, and video, and generates any combination of text, audio, and image outputs. It's trained end-to-end across text, vision, and audio, meaning all inputs and outputs are processed by the same neural network. GPT-4o can respond to audio inputs in as little as 232 milliseconds, with an average of 320 milliseconds, which is similar to human response time in conversation. It matches GPT-4 Turbo performance on text in English and code, with significant improvement on text in non-English languages, while also being much faster and 50\% cheaper in the API. GPT-4o is especially better at vision and audio understanding compared to existing models. In line with our commitment to building AI safely and consistent with our voluntary commitments to the White House, we are sharing the GPT-4o System Card, which includes our Preparedness Framework evaluations. In this System Card, we provide a detailed look at GPT-4o's capabilities, limitations, and safety evaluations across multiple categories, focusing on speech-to-speech while also evaluating text and image capabilities, and measures we've implemented to ensure the model is safe and aligned. We also include third-party assessments on dangerous capabilities, as well as discussion of potential societal impacts of GPT-4o's text and vision capabilities.
MLE-bench: Evaluating Machine Learning Agents on Machine Learning Engineering
Oct 09, 2024



We introduce MLE-bench, a benchmark for measuring how well AI agents perform at machine learning engineering. To this end, we curate 75 ML engineering-related competitions from Kaggle, creating a diverse set of challenging tasks that test real-world ML engineering skills such as training models, preparing datasets, and running experiments. We establish human baselines for each competition using Kaggle's publicly available leaderboards. We use open-source agent scaffolds to evaluate several frontier language models on our benchmark, finding that the best-performing setup--OpenAI's o1-preview with AIDE scaffolding--achieves at least the level of a Kaggle bronze medal in 16.9% of competitions. In addition to our main results, we investigate various forms of resource scaling for AI agents and the impact of contamination from pre-training. We open-source our benchmark code (github.com/openai/mle-bench/) to facilitate future research in understanding the ML engineering capabilities of AI agents.
Nova$^+$: Generative Language Models for Binaries
Nov 27, 2023
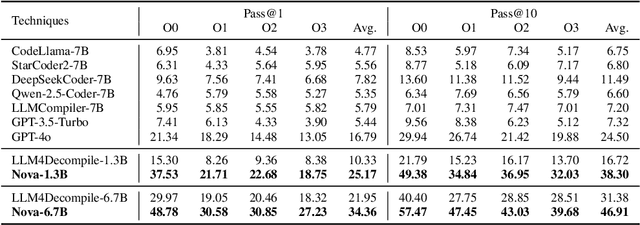
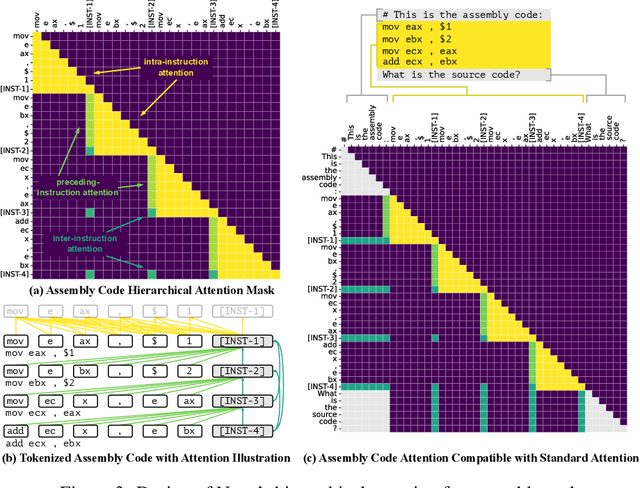

Generative large language models (LLMs) pre-trained on code have shown impressive effectiveness in code generation, program repair, and document analysis. However, existing generative LLMs focus on source code and are not specialized for binaries. There are three main challenges for LLMs to model and learn binary code: hex-decimal values, complex global dependencies, and compiler optimization levels. To bring the benefit of LLMs to the binary domain, we develop Nova and Nova$^+$, which are LLMs pre-trained on binary corpora. Nova is pre-trained with the standard language modeling task, showing significantly better capability on five benchmarks for three downstream tasks: binary code similarity detection (BCSD), binary code translation (BCT), and binary code recovery (BCR), over GPT-3.5 and other existing techniques. We build Nova$^+$ to further boost Nova using two new pre-training tasks, i.e., optimization generation and optimization level prediction, which are designed to learn binary optimization and align equivalent binaries. Nova$^+$ shows overall the best performance for all three downstream tasks on five benchmarks, demonstrating the contributions of the new pre-training tasks.
Cognitive Dissonance: Why Do Language Model Outputs Disagree with Internal Representations of Truthfulness?
Nov 27, 2023Neural language models (LMs) can be used to evaluate the truth of factual statements in two ways: they can be either queried for statement probabilities, or probed for internal representations of truthfulness. Past work has found that these two procedures sometimes disagree, and that probes tend to be more accurate than LM outputs. This has led some researchers to conclude that LMs "lie" or otherwise encode non-cooperative communicative intents. Is this an accurate description of today's LMs, or can query-probe disagreement arise in other ways? We identify three different classes of disagreement, which we term confabulation, deception, and heterogeneity. In many cases, the superiority of probes is simply attributable to better calibration on uncertain answers rather than a greater fraction of correct, high-confidence answers. In some cases, queries and probes perform better on different subsets of inputs, and accuracy can further be improved by ensembling the two. Code is available at github.com/lingo-mit/lm-truthfulness.
Model-agnostic Measure of Generalization Difficulty
May 01, 2023The measure of a machine learning algorithm is the difficulty of the tasks it can perform, and sufficiently difficult tasks are critical drivers of strong machine learning models. However, quantifying the generalization difficulty of machine learning benchmarks has remained challenging. We propose what is to our knowledge the first model-agnostic measure of the inherent generalization difficulty of tasks. Our inductive bias complexity measure quantifies the total information required to generalize well on a task minus the information provided by the data. It does so by measuring the fractional volume occupied by hypotheses that generalize on a task given that they fit the training data. It scales exponentially with the intrinsic dimensionality of the space over which the model must generalize but only polynomially in resolution per dimension, showing that tasks which require generalizing over many dimensions are drastically more difficult than tasks involving more detail in fewer dimensions. Our measure can be applied to compute and compare supervised learning, reinforcement learning and meta-learning generalization difficulties against each other. We show that applied empirically, it formally quantifies intuitively expected trends, e.g. that in terms of required inductive bias, MNIST < CIFAR10 < Imagenet and fully observable Markov decision processes (MDPs) < partially observable MDPs. Further, we show that classification of complex images $<$ few-shot meta-learning with simple images. Our measure provides a quantitative metric to guide the construction of more complex tasks requiring greater inductive bias, and thereby encourages the development of more sophisticated architectures and learning algorithms with more powerful generalization capabilities.
Deep Learning Predicts Prevalent and Incident Parkinson's Disease From UK Biobank Fundus Imaging
Feb 17, 2023Parkinson's disease is the world's fastest growing neurological disorder. Research to elucidate the mechanisms of Parkinson's disease and automate diagnostics would greatly improve the treatment of patients with Parkinson's disease. Current diagnostic methods are expensive with limited availability. Considering the long progression time of Parkinson's disease, a desirable screening should be diagnostically accurate even before the onset of symptoms to allow medical intervention. We promote attention for retinal fundus imaging, often termed a window to the brain, as a diagnostic screening modality for Parkinson's disease. We conduct a systematic evaluation of conventional machine learning and deep learning techniques to classify Parkinson's disease from UK Biobank fundus imaging. Our results suggest Parkinson's disease individuals can be differentiated from age and gender matched healthy subjects with 71% accuracy. This accuracy is maintained when predicting either prevalent or incident Parkinson's disease. Explainability and trustworthiness is enhanced by visual attribution maps of localized biomarkers and quantified metrics of model robustness to data perturbations.
Open Set Recognition For Music Genre Classification
Sep 15, 2022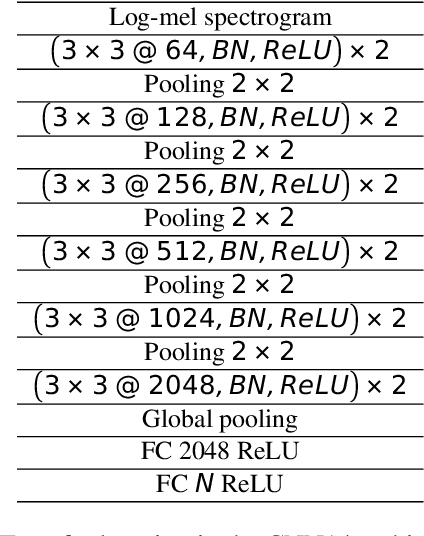
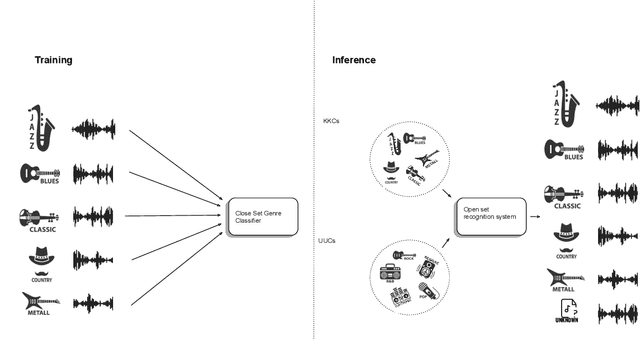

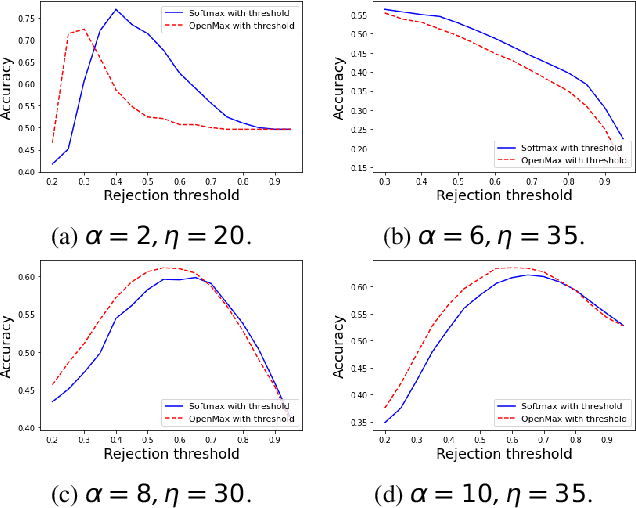
We explore segmentation of known and unknown genre classes using the open source GTZAN and FMA datasets. For each, we begin with best-case closed set genre classification, then we apply open set recognition methods. We offer an algorithm for the music genre classification task using OSR. We demonstrate the ability to retrieve known genres and as well identification of aural patterns for novel genres (not appearing in a training set). We conduct four experiments, each containing a different set of known and unknown classes, using the GTZAN and the FMA datasets to establish a baseline capacity for novel genre detection. We employ grid search on both OpenMax and softmax to determine the optimal total classification accuracy for each experimental setup, and illustrate interaction between genre labelling and open set recognition accuracy.
ZeroC: A Neuro-Symbolic Model for Zero-shot Concept Recognition and Acquisition at Inference Time
Jul 03, 2022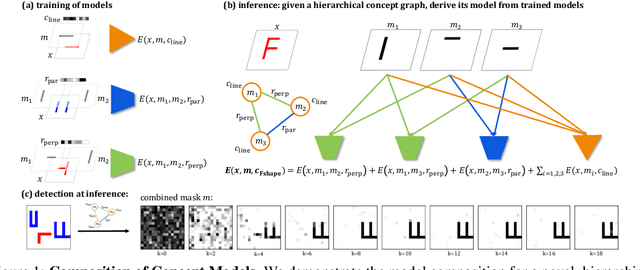
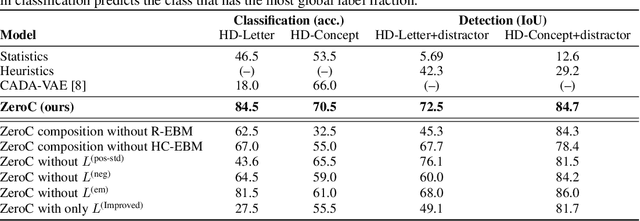
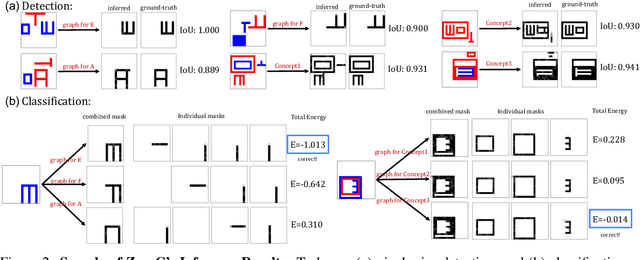
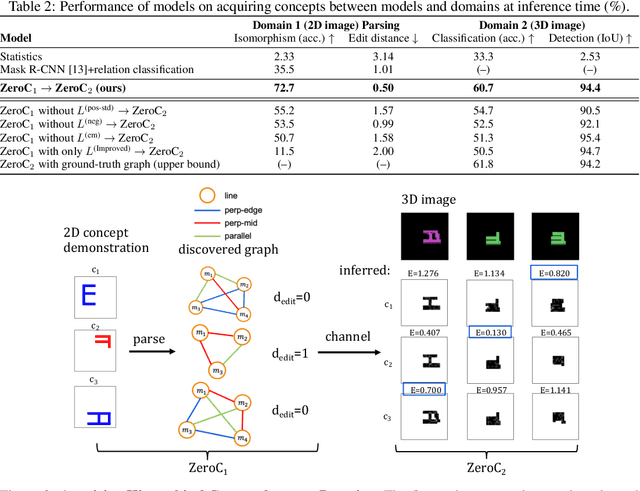
Humans have the remarkable ability to recognize and acquire novel visual concepts in a zero-shot manner. Given a high-level, symbolic description of a novel concept in terms of previously learned visual concepts and their relations, humans can recognize novel concepts without seeing any examples. Moreover, they can acquire new concepts by parsing and communicating symbolic structures using learned visual concepts and relations. Endowing these capabilities in machines is pivotal in improving their generalization capability at inference time. In this work, we introduce Zero-shot Concept Recognition and Acquisition (ZeroC), a neuro-symbolic architecture that can recognize and acquire novel concepts in a zero-shot way. ZeroC represents concepts as graphs of constituent concept models (as nodes) and their relations (as edges). To allow inference time composition, we employ energy-based models (EBMs) to model concepts and relations. We design ZeroC architecture so that it allows a one-to-one mapping between a symbolic graph structure of a concept and its corresponding EBM, which for the first time, allows acquiring new concepts, communicating its graph structure, and applying it to classification and detection tasks (even across domains) at inference time. We introduce algorithms for learning and inference with ZeroC. We evaluate ZeroC on a challenging grid-world dataset which is designed to probe zero-shot concept recognition and acquisition, and demonstrate its capability.