 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePaperBench: Evaluating AI's Ability to Replicate AI Research
Apr 02, 2025We introduce PaperBench, a benchmark evaluating the ability of AI agents to replicate state-of-the-art AI research. Agents must replicate 20 ICML 2024 Spotlight and Oral papers from scratch, including understanding paper contributions, developing a codebase, and successfully executing experiments. For objective evaluation, we develop rubrics that hierarchically decompose each replication task into smaller sub-tasks with clear grading criteria. In total, PaperBench contains 8,316 individually gradable tasks. Rubrics are co-developed with the author(s) of each ICML paper for accuracy and realism. To enable scalable evaluation, we also develop an LLM-based judge to automatically grade replication attempts against rubrics, and assess our judge's performance by creating a separate benchmark for judges. We evaluate several frontier models on PaperBench, finding that the best-performing tested agent, Claude 3.5 Sonnet (New) with open-source scaffolding, achieves an average replication score of 21.0\%. Finally, we recruit top ML PhDs to attempt a subset of PaperBench, finding that models do not yet outperform the human baseline. We \href{https://github.com/openai/preparedness}{open-source our code} to facilitate future research in understanding the AI engineering capabilities of AI agents.
GPT-4o System Card
Oct 25, 2024GPT-4o is an autoregressive omni model that accepts as input any combination of text, audio, image, and video, and generates any combination of text, audio, and image outputs. It's trained end-to-end across text, vision, and audio, meaning all inputs and outputs are processed by the same neural network. GPT-4o can respond to audio inputs in as little as 232 milliseconds, with an average of 320 milliseconds, which is similar to human response time in conversation. It matches GPT-4 Turbo performance on text in English and code, with significant improvement on text in non-English languages, while also being much faster and 50\% cheaper in the API. GPT-4o is especially better at vision and audio understanding compared to existing models. In line with our commitment to building AI safely and consistent with our voluntary commitments to the White House, we are sharing the GPT-4o System Card, which includes our Preparedness Framework evaluations. In this System Card, we provide a detailed look at GPT-4o's capabilities, limitations, and safety evaluations across multiple categories, focusing on speech-to-speech while also evaluating text and image capabilities, and measures we've implemented to ensure the model is safe and aligned. We also include third-party assessments on dangerous capabilities, as well as discussion of potential societal impacts of GPT-4o's text and vision capabilities.
MLE-bench: Evaluating Machine Learning Agents on Machine Learning Engineering
Oct 09, 2024



We introduce MLE-bench, a benchmark for measuring how well AI agents perform at machine learning engineering. To this end, we curate 75 ML engineering-related competitions from Kaggle, creating a diverse set of challenging tasks that test real-world ML engineering skills such as training models, preparing datasets, and running experiments. We establish human baselines for each competition using Kaggle's publicly available leaderboards. We use open-source agent scaffolds to evaluate several frontier language models on our benchmark, finding that the best-performing setup--OpenAI's o1-preview with AIDE scaffolding--achieves at least the level of a Kaggle bronze medal in 16.9% of competitions. In addition to our main results, we investigate various forms of resource scaling for AI agents and the impact of contamination from pre-training. We open-source our benchmark code (github.com/openai/mle-bench/) to facilitate future research in understanding the ML engineering capabilities of AI agents.
Probing LLMs for Joint Encoding of Linguistic Categories
Oct 28, 2023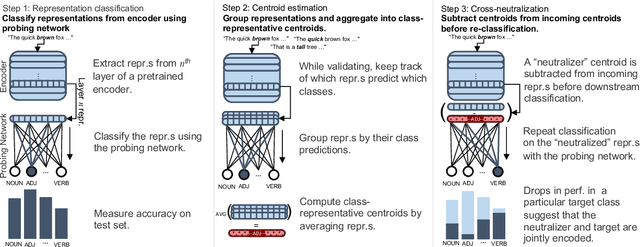


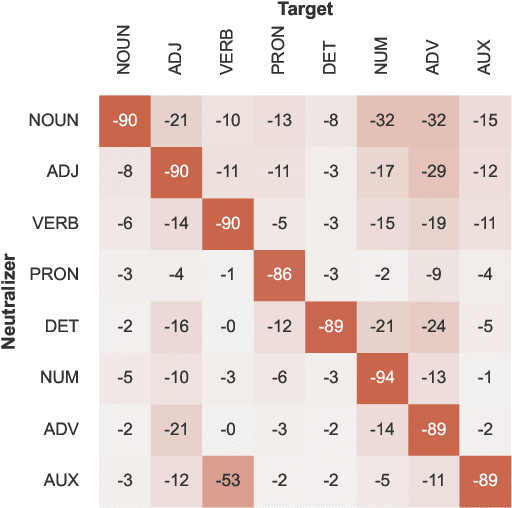
Large Language Models (LLMs) exhibit impressive performance on a range of NLP tasks, due to the general-purpose linguistic knowledge acquired during pretraining. Existing model interpretability research (Tenney et al., 2019) suggests that a linguistic hierarchy emerges in the LLM layers, with lower layers better suited to solving syntactic tasks and higher layers employed for semantic processing. Yet, little is known about how encodings of different linguistic phenomena interact within the models and to what extent processing of linguistically-related categories relies on the same, shared model representations. In this paper, we propose a framework for testing the joint encoding of linguistic categories in LLMs. Focusing on syntax, we find evidence of joint encoding both at the same (related part-of-speech (POS) classes) and different (POS classes and related syntactic dependency relations) levels of linguistic hierarchy. Our cross-lingual experiments show that the same patterns hold across languages in multilingual LLMs.
[Re] Badder Seeds: Reproducing the Evaluation of Lexical Methods for Bias Measurement
Jun 03, 2022![Figure 1 for [Re] Badder Seeds: Reproducing the Evaluation of Lexical Methods for Bias Measurement](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2F10dc8987b46b59843b3b68e04c1346bd1fa8bde0%2F6-Figure1-1.png&w=640&q=75)
![Figure 2 for [Re] Badder Seeds: Reproducing the Evaluation of Lexical Methods for Bias Measurement](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2F10dc8987b46b59843b3b68e04c1346bd1fa8bde0%2F6-Figure2-1.png&w=640&q=75)
![Figure 3 for [Re] Badder Seeds: Reproducing the Evaluation of Lexical Methods for Bias Measurement](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2F10dc8987b46b59843b3b68e04c1346bd1fa8bde0%2F7-Figure3-1.png&w=640&q=75)
![Figure 4 for [Re] Badder Seeds: Reproducing the Evaluation of Lexical Methods for Bias Measurement](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2F10dc8987b46b59843b3b68e04c1346bd1fa8bde0%2F7-Figure4-1.png&w=640&q=75)
Combating bias in NLP requires bias measurement. Bias measurement is almost always achieved by using lexicons of seed terms, i.e. sets of words specifying stereotypes or dimensions of interest. This reproducibility study focuses on the original authors' main claim that the rationale for the construction of these lexicons needs thorough checking before usage, as the seeds used for bias measurement can themselves exhibit biases. The study aims to evaluate the reproducibility of the quantitative and qualitative results presented in the paper and the conclusions drawn thereof. We reproduce most of the results supporting the original authors' general claim: seed sets often suffer from biases that affect their performance as a baseline for bias metrics. Generally, our results mirror the original paper's. They are slightly different on select occasions, but not in ways that undermine the paper's general intent to show the fragility of seed sets.
* 15 pages, 7 figures