 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePaperBench: Evaluating AI's Ability to Replicate AI Research
Apr 02, 2025We introduce PaperBench, a benchmark evaluating the ability of AI agents to replicate state-of-the-art AI research. Agents must replicate 20 ICML 2024 Spotlight and Oral papers from scratch, including understanding paper contributions, developing a codebase, and successfully executing experiments. For objective evaluation, we develop rubrics that hierarchically decompose each replication task into smaller sub-tasks with clear grading criteria. In total, PaperBench contains 8,316 individually gradable tasks. Rubrics are co-developed with the author(s) of each ICML paper for accuracy and realism. To enable scalable evaluation, we also develop an LLM-based judge to automatically grade replication attempts against rubrics, and assess our judge's performance by creating a separate benchmark for judges. We evaluate several frontier models on PaperBench, finding that the best-performing tested agent, Claude 3.5 Sonnet (New) with open-source scaffolding, achieves an average replication score of 21.0\%. Finally, we recruit top ML PhDs to attempt a subset of PaperBench, finding that models do not yet outperform the human baseline. We \href{https://github.com/openai/preparedness}{open-source our code} to facilitate future research in understanding the AI engineering capabilities of AI agents.
MLE-bench: Evaluating Machine Learning Agents on Machine Learning Engineering
Oct 09, 2024



We introduce MLE-bench, a benchmark for measuring how well AI agents perform at machine learning engineering. To this end, we curate 75 ML engineering-related competitions from Kaggle, creating a diverse set of challenging tasks that test real-world ML engineering skills such as training models, preparing datasets, and running experiments. We establish human baselines for each competition using Kaggle's publicly available leaderboards. We use open-source agent scaffolds to evaluate several frontier language models on our benchmark, finding that the best-performing setup--OpenAI's o1-preview with AIDE scaffolding--achieves at least the level of a Kaggle bronze medal in 16.9% of competitions. In addition to our main results, we investigate various forms of resource scaling for AI agents and the impact of contamination from pre-training. We open-source our benchmark code (github.com/openai/mle-bench/) to facilitate future research in understanding the ML engineering capabilities of AI agents.
Training Language Models with Language Feedback at Scale
Apr 09, 2023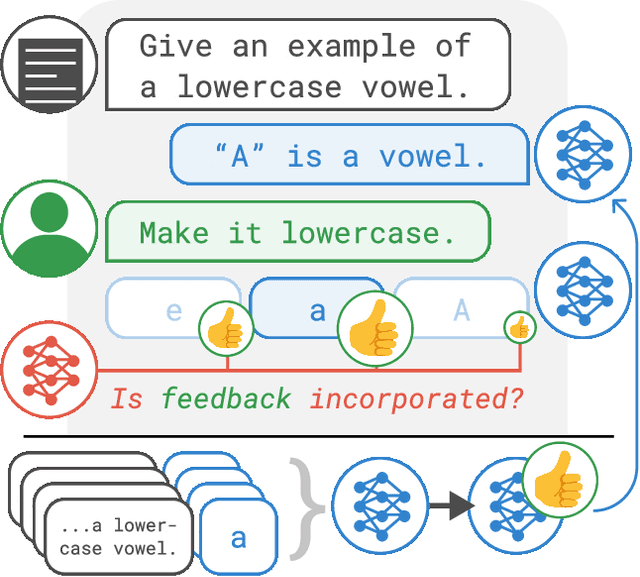


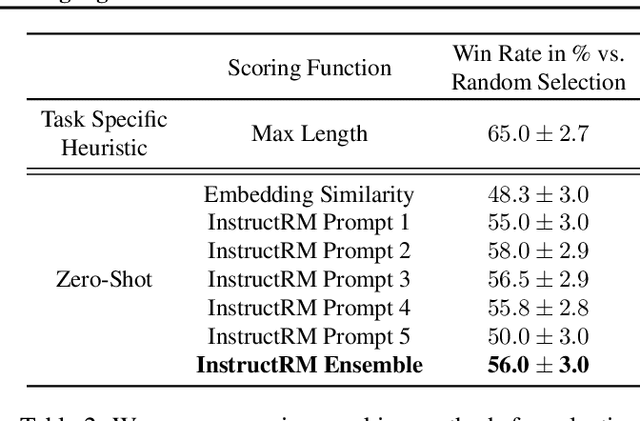
Pretrained language models often generate outputs that are not in line with human preferences, such as harmful text or factually incorrect summaries. Recent work approaches the above issues by learning from a simple form of human feedback: comparisons between pairs of model-generated outputs. However, comparison feedback only conveys limited information about human preferences. In this paper, we introduce Imitation learning from Language Feedback (ILF), a new approach that utilizes more informative language feedback. ILF consists of three steps that are applied iteratively: first, conditioning the language model on the input, an initial LM output, and feedback to generate refinements. Second, selecting the refinement incorporating the most feedback. Third, finetuning the language model to maximize the likelihood of the chosen refinement given the input. We show theoretically that ILF can be viewed as Bayesian Inference, similar to Reinforcement Learning from human feedback. We evaluate ILF's effectiveness on a carefully-controlled toy task and a realistic summarization task. Our experiments demonstrate that large language models accurately incorporate feedback and that finetuning with ILF scales well with the dataset size, even outperforming finetuning on human summaries. Learning from both language and comparison feedback outperforms learning from each alone, achieving human-level summarization performance.
Improving Code Generation by Training with Natural Language Feedback
Mar 28, 2023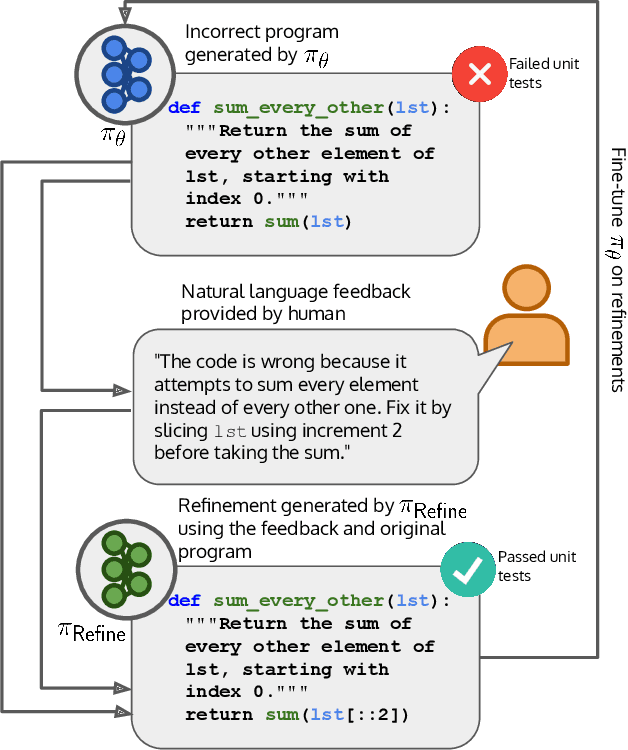



The potential for pre-trained large language models (LLMs) to use natural language feedback at inference time has been an exciting recent development. We build upon this observation by formalizing an algorithm for learning from natural language feedback at training time instead, which we call Imitation learning from Language Feedback (ILF). ILF requires only a small amount of human-written feedback during training and does not require the same feedback at test time, making it both user-friendly and sample-efficient. We further show that ILF can be seen as a form of minimizing the KL divergence to the ground truth distribution and demonstrate a proof-of-concept on a neural program synthesis task. We use ILF to improve a Codegen-Mono 6.1B model's pass@1 rate by 38% relative (and 10% absolute) on the Mostly Basic Python Problems (MBPP) benchmark, outperforming both fine-tuning on MBPP and fine-tuning on repaired programs written by humans. Overall, our results suggest that learning from human-written natural language feedback is both more effective and sample-efficient than training exclusively on demonstrations for improving an LLM's performance on code generation tasks.
How Would The Viewer Feel? Estimating Wellbeing From Video Scenarios
Oct 18, 2022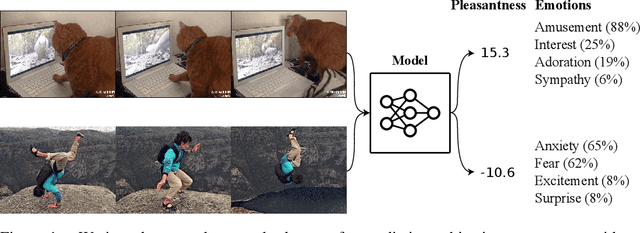
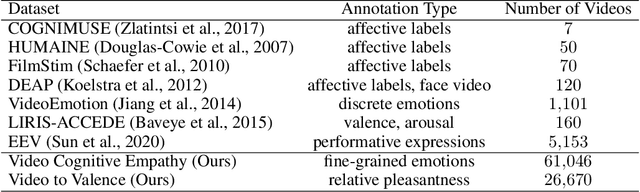


In recent years, deep neural networks have demonstrated increasingly strong abilities to recognize objects and activities in videos. However, as video understanding becomes widely used in real-world applications, a key consideration is developing human-centric systems that understand not only the content of the video but also how it would affect the wellbeing and emotional state of viewers. To facilitate research in this setting, we introduce two large-scale datasets with over 60,000 videos manually annotated for emotional response and subjective wellbeing. The Video Cognitive Empathy (VCE) dataset contains annotations for distributions of fine-grained emotional responses, allowing models to gain a detailed understanding of affective states. The Video to Valence (V2V) dataset contains annotations of relative pleasantness between videos, which enables predicting a continuous spectrum of wellbeing. In experiments, we show how video models that are primarily trained to recognize actions and find contours of objects can be repurposed to understand human preferences and the emotional content of videos. Although there is room for improvement, predicting wellbeing and emotional response is on the horizon for state-of-the-art models. We hope our datasets can help foster further advances at the intersection of commonsense video understanding and human preference learning.
Few-shot Adaptation Works with UnpredicTable Data
Aug 08, 2022
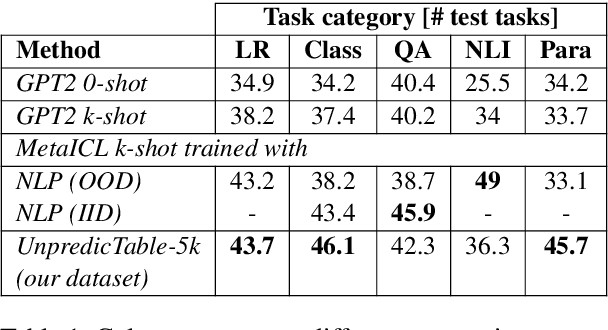
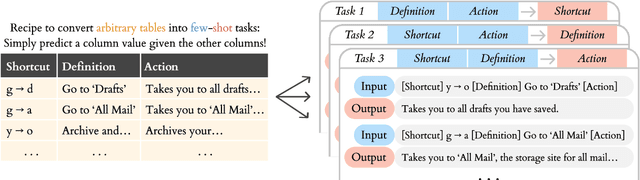

Prior work on language models (LMs) shows that training on a large number of diverse tasks improves few-shot learning (FSL) performance on new tasks. We take this to the extreme, automatically extracting 413,299 tasks from internet tables - orders of magnitude more than the next-largest public datasets. Finetuning on the resulting dataset leads to improved FSL performance on Natural Language Processing (NLP) tasks, but not proportionally to dataset scale. In fact, we find that narrow subsets of our dataset sometimes outperform more diverse datasets. For example, finetuning on software documentation from support.google.com raises FSL performance by a mean of +7.5% on 52 downstream tasks, which beats training on 40 human-curated NLP datasets (+6.7%). Finetuning on various narrow datasets leads to similar broad improvements across test tasks, suggesting that the gains are not from domain adaptation but adapting to FSL in general. We do not observe clear patterns between the datasets that lead to FSL gains, leaving open questions about why certain data helps with FSL.
Training Language Models with Natural Language Feedback
May 02, 2022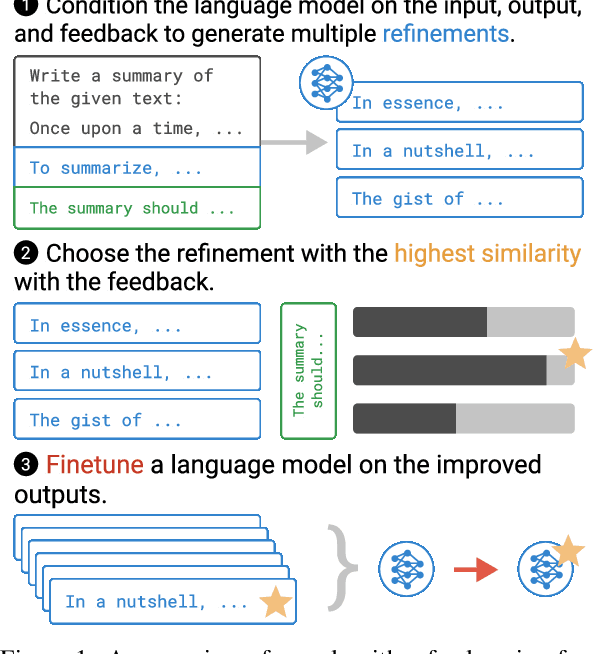
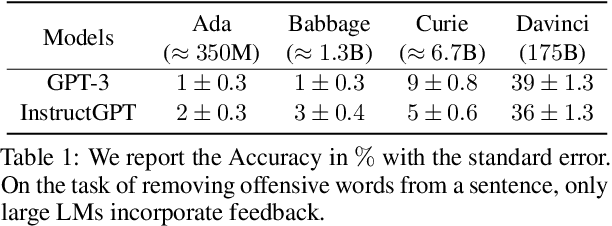
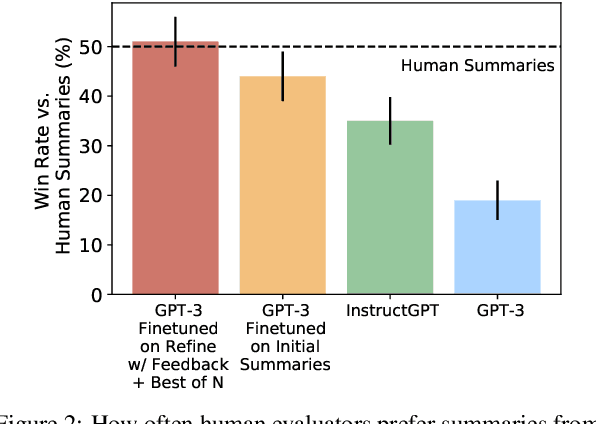
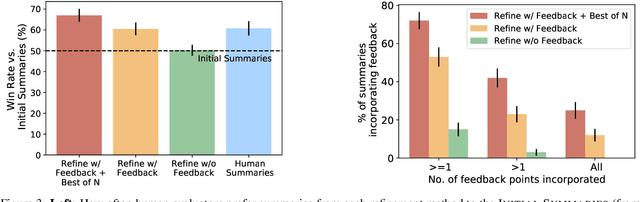
Pretrained language models often do not perform tasks in ways that are in line with our preferences, e.g., generating offensive text or factually incorrect summaries. Recent work approaches the above issue by learning from a simple form of human evaluation: comparisons between pairs of model-generated task outputs. Comparison feedback conveys limited information about human preferences per human evaluation. Here, we propose to learn from natural language feedback, which conveys more information per human evaluation. We learn from language feedback on model outputs using a three-step learning algorithm. First, we condition the language model on the initial output and feedback to generate many refinements. Second, we choose the refinement with the highest similarity to the feedback. Third, we finetune a language model to maximize the likelihood of the chosen refinement given the input. In synthetic experiments, we first evaluate whether language models accurately incorporate feedback to produce refinements, finding that only large language models (175B parameters) do so. Using only 100 samples of human-written feedback, our learning algorithm finetunes a GPT-3 model to roughly human-level summarization.