 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralist Foundation Models Are Not Clinical Enough for Hospital Operations
Nov 17, 2025Hospitals and healthcare systems rely on operational decisions that determine patient flow, cost, and quality of care. Despite strong performance on medical knowledge and conversational benchmarks, foundation models trained on general text may lack the specialized knowledge required for these operational decisions. We introduce Lang1, a family of models (100M-7B parameters) pretrained on a specialized corpus blending 80B clinical tokens from NYU Langone Health's EHRs and 627B tokens from the internet. To rigorously evaluate Lang1 in real-world settings, we developed the REalistic Medical Evaluation (ReMedE), a benchmark derived from 668,331 EHR notes that evaluates five critical tasks: 30-day readmission prediction, 30-day mortality prediction, length of stay, comorbidity coding, and predicting insurance claims denial. In zero-shot settings, both general-purpose and specialized models underperform on four of five tasks (36.6%-71.7% AUROC), with mortality prediction being an exception. After finetuning, Lang1-1B outperforms finetuned generalist models up to 70x larger and zero-shot models up to 671x larger, improving AUROC by 3.64%-6.75% and 1.66%-23.66% respectively. We also observed cross-task scaling with joint finetuning on multiple tasks leading to improvement on other tasks. Lang1-1B effectively transfers to out-of-distribution settings, including other clinical tasks and an external health system. Our findings suggest that predictive capabilities for hospital operations require explicit supervised finetuning, and that this finetuning process is made more efficient by in-domain pretraining on EHR. Our findings support the emerging view that specialized LLMs can compete with generalist models in specialized tasks, and show that effective healthcare systems AI requires the combination of in-domain pretraining, supervised finetuning, and real-world evaluation beyond proxy benchmarks.
Bridging Offline and Online Reinforcement Learning for LLMs
Jun 26, 2025We investigate the effectiveness of reinforcement learning methods for finetuning large language models when transitioning from offline to semi-online to fully online regimes for both verifiable and non-verifiable tasks. Our experiments cover training on verifiable math as well as non-verifiable instruction following with a set of benchmark evaluations for both. Across these settings, we extensively compare online and semi-online Direct Preference Optimization and Group Reward Policy Optimization objectives, and surprisingly find similar performance and convergence between these variants, which all strongly outperform offline methods. We provide a detailed analysis of the training dynamics and hyperparameter selection strategies to achieve optimal results. Finally, we show that multi-tasking with verifiable and non-verifiable rewards jointly yields improved performance across both task types.
Diverse Preference Optimization
Jan 31, 2025



Post-training of language models, either through reinforcement learning, preference optimization or supervised finetuning, tends to sharpen the output probability distribution and reduce the diversity of generated responses. This is particularly a problem for creative generative tasks where varied responses are desired. In this work we introduce Diverse Preference Optimization (DivPO), an optimization method which learns to generate much more diverse responses than standard pipelines, while maintaining the quality of the generations. In DivPO, preference pairs are selected by first considering a pool of responses, and a measure of diversity among them, and selecting chosen examples as being more rare but high quality, while rejected examples are more common, but low quality. DivPO results in generating 45.6% more diverse persona attributes, and an 74.6% increase in story diversity, while maintaining similar win rates as standard baselines.
LLMs are Highly-Constrained Biophysical Sequence Optimizers
Oct 29, 2024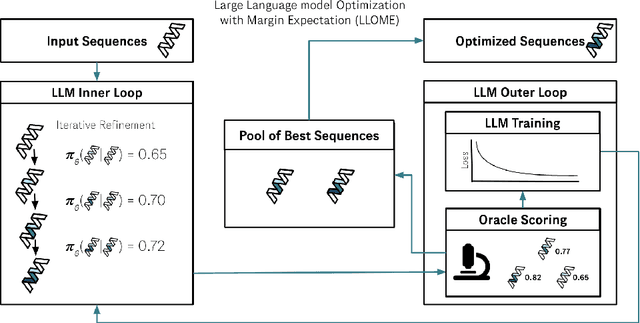
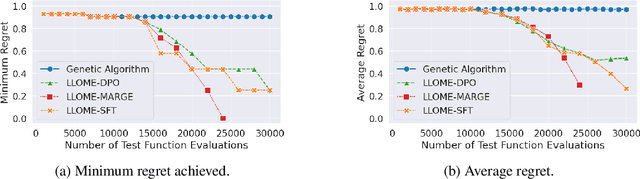
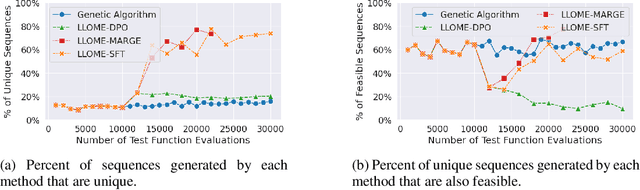
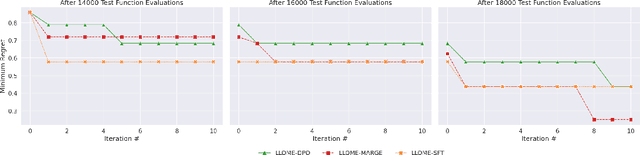
Large language models (LLMs) have recently shown significant potential in various biological tasks such as protein engineering and molecule design. These tasks typically involve black-box discrete sequence optimization, where the challenge lies in generating sequences that are not only biologically feasible but also adhere to hard fine-grained constraints. However, LLMs often struggle with such constraints, especially in biological contexts where verifying candidate solutions is costly and time-consuming. In this study, we explore the possibility of employing LLMs as highly-constrained bilevel optimizers through a methodology we refer to as Language Model Optimization with Margin Expectation (LLOME). This approach combines both offline and online optimization, utilizing limited oracle evaluations to iteratively enhance the sequences generated by the LLM. We additionally propose a novel training objective -- Margin-Aligned Expectation (MargE) -- that trains the LLM to smoothly interpolate between the reward and reference distributions. Lastly, we introduce a synthetic test suite that bears strong geometric similarity to real biophysical problems and enables rapid evaluation of LLM optimizers without time-consuming lab validation. Our findings reveal that, in comparison to genetic algorithm baselines, LLMs achieve significantly lower regret solutions while requiring fewer test function evaluations. However, we also observe that LLMs exhibit moderate miscalibration, are susceptible to generator collapse, and have difficulty finding the optimal solution when no explicit ground truth rewards are available.
Preference Learning Algorithms Do Not Learn Preference Rankings
May 29, 2024Preference learning algorithms (e.g., RLHF and DPO) are frequently used to steer LLMs to produce generations that are more preferred by humans, but our understanding of their inner workings is still limited. In this work, we study the conventional wisdom that preference learning trains models to assign higher likelihoods to more preferred outputs than less preferred outputs, measured via $\textit{ranking accuracy}$. Surprisingly, we find that most state-of-the-art preference-tuned models achieve a ranking accuracy of less than 60% on common preference datasets. We furthermore derive the $\textit{idealized ranking accuracy}$ that a preference-tuned LLM would achieve if it optimized the DPO or RLHF objective perfectly. We demonstrate that existing models exhibit a significant $\textit{alignment gap}$ -- $\textit{i.e.}$, a gap between the observed and idealized ranking accuracies. We attribute this discrepancy to the DPO objective, which is empirically and theoretically ill-suited to fix even mild ranking errors in the reference model, and derive a simple and efficient formula for quantifying the difficulty of learning a given preference datapoint. Finally, we demonstrate that ranking accuracy strongly correlates with the empirically popular win rate metric when the model is close to the reference model used in the objective, shedding further light on the differences between on-policy (e.g., RLHF) and off-policy (e.g., DPO) preference learning algorithms.
AI safety by debate via regret minimization
Dec 08, 2023



We consider the setting of AI safety by debate as a repeated game. We consider the question of efficient regret minimization in this setting, when the players are either AIs or humans, equipped with access to computationally superior AIs. In such a setting, we characterize when internal and external regret can be minimized efficiently. We conclude with conditions in which a sequence of strategies converges to a correlated equilibrium.
Sudden Drops in the Loss: Syntax Acquisition, Phase Transitions, and Simplicity Bias in MLMs
Sep 28, 2023



Most interpretability research in NLP focuses on understanding the behavior and features of a fully trained model. However, certain insights into model behavior may only be accessible by observing the trajectory of the training process. We present a case study of syntax acquisition in masked language models (MLMs) that demonstrates how analyzing the evolution of interpretable artifacts throughout training deepens our understanding of emergent behavior. In particular, we study Syntactic Attention Structure (SAS), a naturally emerging property of MLMs wherein specific Transformer heads tend to focus on specific syntactic relations. We identify a brief window in pretraining when models abruptly acquire SAS, concurrent with a steep drop in loss. This breakthrough precipitates the subsequent acquisition of linguistic capabilities. We then examine the causal role of SAS by manipulating SAS during training, and demonstrate that SAS is necessary for the development of grammatical capabilities. We further find that SAS competes with other beneficial traits during training, and that briefly suppressing SAS improves model quality. These findings offer an interpretation of a real-world example of both simplicity bias and breakthrough training dynamics.
Latent State Models of Training Dynamics
Aug 18, 2023


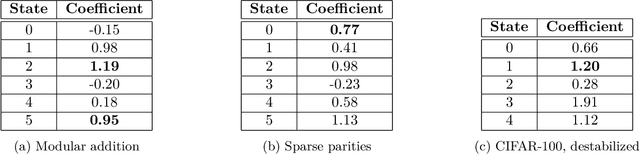
The impact of randomness on model training is poorly understood. How do differences in data order and initialization actually manifest in the model, such that some training runs outperform others or converge faster? Furthermore, how can we interpret the resulting training dynamics and the phase transitions that characterize different trajectories? To understand the effect of randomness on the dynamics and outcomes of neural network training, we train models multiple times with different random seeds and compute a variety of metrics throughout training, such as the $L_2$ norm, mean, and variance of the neural network's weights. We then fit a hidden Markov model (HMM) over the resulting sequences of metrics. The HMM represents training as a stochastic process of transitions between latent states, providing an intuitive overview of significant changes during training. Using our method, we produce a low-dimensional, discrete representation of training dynamics on grokking tasks, image classification, and masked language modeling. We use the HMM representation to study phase transitions and identify latent "detour" states that slow down convergence.
Two Failures of Self-Consistency in the Multi-Step Reasoning of LLMs
May 23, 2023



Large language models (LLMs) have achieved widespread success on a variety of in-context few-shot tasks, but this success is typically evaluated via correctness rather than consistency. We argue that self-consistency is an important criteria for valid multi-step reasoning and propose two types of self-consistency that are particularly important for multi-step logic -- hypothetical consistency (the ability for a model to predict what its output would be in a hypothetical other context) and compositional consistency (consistency of a model's outputs for a compositional task even when an intermediate step is replaced with the model's output for that step). We demonstrate that four sizes of the GPT-3 model exhibit poor consistency rates across both types of consistency on four different tasks (Wikipedia, DailyDialog, arithmetic, and GeoQuery).
Training Language Models with Language Feedback at Scale
Apr 09, 2023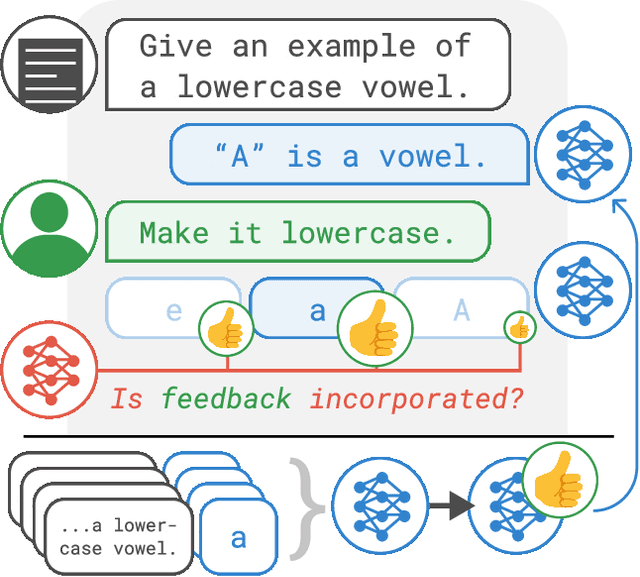


Pretrained language models often generate outputs that are not in line with human preferences, such as harmful text or factually incorrect summaries. Recent work approaches the above issues by learning from a simple form of human feedback: comparisons between pairs of model-generated outputs. However, comparison feedback only conveys limited information about human preferences. In this paper, we introduce Imitation learning from Language Feedback (ILF), a new approach that utilizes more informative language feedback. ILF consists of three steps that are applied iteratively: first, conditioning the language model on the input, an initial LM output, and feedback to generate refinements. Second, selecting the refinement incorporating the most feedback. Third, finetuning the language model to maximize the likelihood of the chosen refinement given the input. We show theoretically that ILF can be viewed as Bayesian Inference, similar to Reinforcement Learning from human feedback. We evaluate ILF's effectiveness on a carefully-controlled toy task and a realistic summarization task. Our experiments demonstrate that large language models accurately incorporate feedback and that finetuning with ILF scales well with the dataset size, even outperforming finetuning on human summaries. Learning from both language and comparison feedback outperforms learning from each alone, achieving human-level summarization performance.