 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Electro-communication and Electro-sensing in Weakly Electric Fish using Multi-Agent Deep Reinforcement Learning
Nov 11, 2025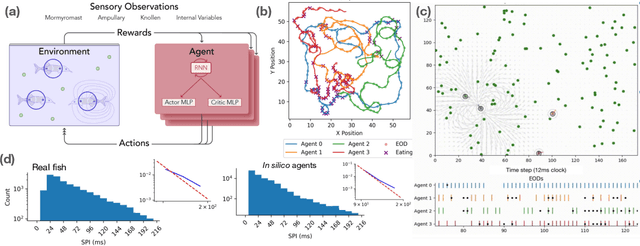
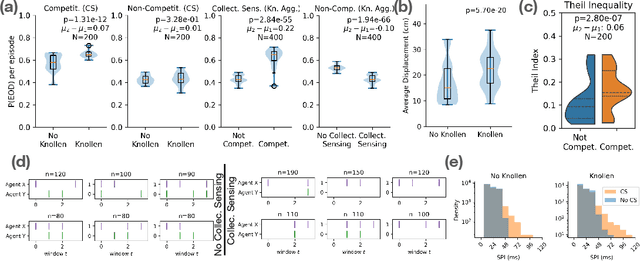
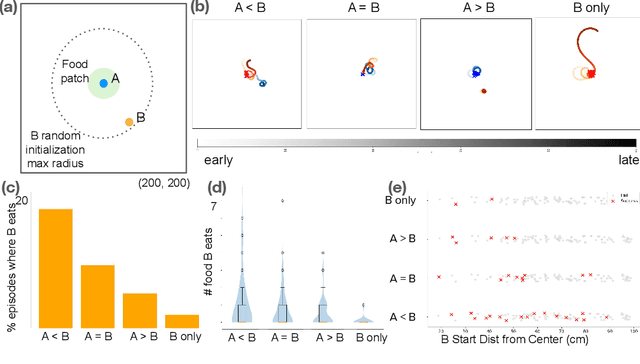
Weakly electric fish, like Gnathonemus petersii, use a remarkable electrical modality for active sensing and communication, but studying their rich electrosensing and electrocommunication behavior and associated neural activity in naturalistic settings remains experimentally challenging. Here, we present a novel biologically-inspired computational framework to study these behaviors, where recurrent neural network (RNN) based artificial agents trained via multi-agent reinforcement learning (MARL) learn to modulate their electric organ discharges (EODs) and movement patterns to collectively forage in virtual environments. Trained agents demonstrate several emergent features consistent with real fish collectives, including heavy tailed EOD interval distributions, environmental context dependent shifts in EOD interval distributions, and social interaction patterns like freeloading, where agents reduce their EOD rates while benefiting from neighboring agents' active sensing. A minimal two-fish assay further isolates the role of electro-communication, showing that access to conspecific EODs and relative dominance jointly shape foraging success. Notably, these behaviors emerge through evolution-inspired rewards for individual fitness and emergent inter-agent interactions, rather than through rewarding agents explicitly for social interactions. Our work has broad implications for the neuroethology of weakly electric fish, as well as other social, communicating animals in which extensive recordings from multiple individuals, and thus traditional data-driven modeling, are infeasible.
Do Natural Language Descriptions of Model Activations Convey Privileged Information?
Sep 16, 2025Recent interpretability methods have proposed to translate LLM internal representations into natural language descriptions using a second verbalizer LLM. This is intended to illuminate how the target model represents and operates on inputs. But do such activation verbalization approaches actually provide privileged knowledge about the internal workings of the target model, or do they merely convey information about its inputs? We critically evaluate popular verbalization methods across datasets used in prior work and find that they succeed at benchmarks without any access to target model internals, suggesting that these datasets are not ideal for evaluating verbalization methods. We then run controlled experiments which reveal that verbalizations often reflect the parametric knowledge of the verbalizer LLM which generated them, rather than the activations of the target LLM being decoded. Taken together, our results indicate a need for targeted benchmarks and experimental controls to rigorously assess whether verbalization methods provide meaningful insights into the operations of LLMs.
A Taxonomy of Transcendence
Aug 25, 2025Although language models are trained to mimic humans, the resulting systems display capabilities beyond the scope of any one person. To understand this phenomenon, we use a controlled setting to identify properties of the training data that lead a model to transcend the performance of its data sources. We build on previous work to outline three modes of transcendence, which we call skill denoising, skill selection, and skill generalization. We then introduce a knowledge graph-based setting in which simulated experts generate data based on their individual expertise. We highlight several aspects of data diversity that help to enable the model's transcendent capabilities. Additionally, our data generation setting offers a controlled testbed that we hope is valuable for future research in the area.
Can Interpretation Predict Behavior on Unseen Data?
Jul 08, 2025Interpretability research often aims to predict how a model will respond to targeted interventions on specific mechanisms. However, it rarely predicts how a model will respond to unseen input data. This paper explores the promises and challenges of interpretability as a tool for predicting out-of-distribution (OOD) model behavior. Specifically, we investigate the correspondence between attention patterns and OOD generalization in hundreds of Transformer models independently trained on a synthetic classification task. These models exhibit several distinct systematic generalization rules OOD, forming a diverse population for correlational analysis. In this setting, we find that simple observational tools from interpretability can predict OOD performance. In particular, when in-distribution attention exhibits hierarchical patterns, the model is likely to generalize hierarchically on OOD data -- even when the rule's implementation does not rely on these hierarchical patterns, according to ablation tests. Our findings offer a proof-of-concept to motivate further interpretability work on predicting unseen model behavior.
Interpreting the Linear Structure of Vision-language Model Embedding Spaces
Apr 16, 2025



Vision-language models encode images and text in a joint space, minimizing the distance between corresponding image and text pairs. How are language and images organized in this joint space, and how do the models encode meaning and modality? To investigate this, we train and release sparse autoencoders (SAEs) on the embedding spaces of four vision-language models (CLIP, SigLIP, SigLIP2, and AIMv2). SAEs approximate model embeddings as sparse linear combinations of learned directions, or "concepts". We find that, compared to other methods of linear feature learning, SAEs are better at reconstructing the real embeddings, while also able to retain the most sparsity. Retraining SAEs with different seeds or different data diet leads to two findings: the rare, specific concepts captured by the SAEs are liable to change drastically, but we also show that the key commonly-activating concepts extracted by SAEs are remarkably stable across runs. Interestingly, while most concepts are strongly unimodal in activation, we find they are not merely encoding modality per se. Many lie close to - but not entirely within - the subspace defining modality, suggesting that they encode cross-modal semantics despite their unimodal usage. To quantify this bridging behavior, we introduce the Bridge Score, a metric that identifies concept pairs which are both co-activated across aligned image-text inputs and geometrically aligned in the shared space. This reveals that even unimodal concepts can collaborate to support cross-modal integration. We release interactive demos of the SAEs for all models, allowing researchers to explore the organization of the concept spaces. Overall, our findings uncover a sparse linear structure within VLM embedding spaces that is shaped by modality, yet stitched together through latent bridges-offering new insight into how multimodal meaning is constructed.
PolyPythias: Stability and Outliers across Fifty Language Model Pre-Training Runs
Mar 12, 2025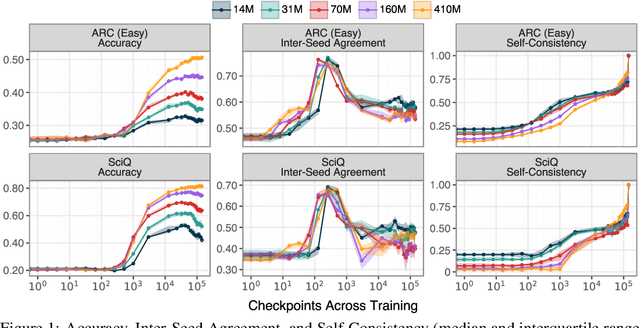

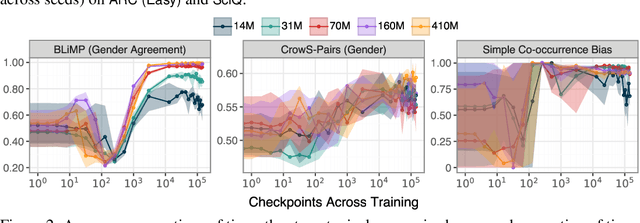
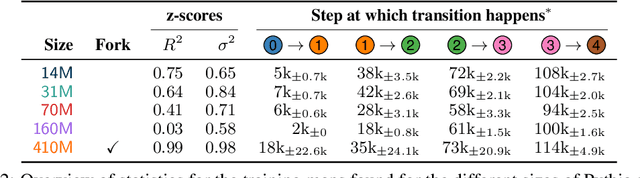
The stability of language model pre-training and its effects on downstream performance are still understudied. Prior work shows that the training process can yield significantly different results in response to slight variations in initial conditions, e.g., the random seed. Crucially, the research community still lacks sufficient resources and tools to systematically investigate pre-training stability, particularly for decoder-only language models. We introduce the PolyPythias, a set of 45 new training runs for the Pythia model suite: 9 new seeds across 5 model sizes, from 14M to 410M parameters, resulting in about 7k new checkpoints that we release. Using these new 45 training runs, in addition to the 5 already available, we study the effects of different initial conditions determined by the seed -- i.e., parameters' initialisation and data order -- on (i) downstream performance, (ii) learned linguistic representations, and (iii) emergence of training phases. In addition to common scaling behaviours, our analyses generally reveal highly consistent training dynamics across both model sizes and initial conditions. Further, the new seeds for each model allow us to identify outlier training runs and delineate their characteristics. Our findings show the potential of using these methods to predict training stability.
Distributional Scaling Laws for Emergent Capabilities
Feb 24, 2025In this paper, we explore the nature of sudden breakthroughs in language model performance at scale, which stands in contrast to smooth improvements governed by scaling laws. While advocates of "emergence" view abrupt performance gains as capabilities unlocking at specific scales, others have suggested that they are produced by thresholding effects and alleviated by continuous metrics. We propose that breakthroughs are instead driven by continuous changes in the probability distribution of training outcomes, particularly when performance is bimodally distributed across random seeds. In synthetic length generalization tasks, we show that different random seeds can produce either highly linear or emergent scaling trends. We reveal that sharp breakthroughs in metrics are produced by underlying continuous changes in their distribution across seeds. Furthermore, we provide a case study of inverse scaling and show that even as the probability of a successful run declines, the average performance of a successful run continues to increase monotonically. We validate our distributional scaling framework on realistic settings by measuring MMLU performance in LLM populations. These insights emphasize the role of random variation in the effect of scale on LLM capabilities.
Sometimes I am a Tree: Data Drives Unstable Hierarchical Generalization
Dec 05, 2024Neural networks often favor shortcut heuristics based on surface-level patterns. As one example, language models (LMs) behave like n-gram models early in training. However, to correctly apply grammatical rules, LMs must rely on hierarchical syntactic representations instead of n-grams. In this work, we use cases studies of English grammar to explore how latent structure in training data drives models toward improved out-of-distribution (OOD) generalization.We then investigate how data composition can lead to inconsistent OOD behavior across random seeds and to unstable training dynamics. Our results show that models stabilize in their OOD behavior only when they fully commit to either a surface-level linear rule or a hierarchical rule. The hierarchical rule, furthermore, is induced by grammatically complex sequences with deep embedding structures, whereas the linear rule is induced by simpler sequences. When the data contains a mix of simple and complex examples, potential rules compete; each independent training run either stabilizes by committing to a single rule or remains unstable in its OOD behavior. These conditions lead `stable seeds' to cluster around simple rules, forming bimodal performance distributions across seeds. We also identify an exception to the relationship between stability and generalization: models which memorize patterns from low-diversity training data can overfit stably, with different rules for memorized and unmemorized patterns. Our findings emphasize the critical role of training data in shaping generalization patterns and how competition between data subsets contributes to inconsistent generalization outcomes across random seeds. Code is available at https://github.com/sunnytqin/concept_comp.git.
Mechanistic?
Oct 07, 2024The rise of the term "mechanistic interpretability" has accompanied increasing interest in understanding neural models -- particularly language models. However, this jargon has also led to a fair amount of confusion. So, what does it mean to be "mechanistic"? We describe four uses of the term in interpretability research. The most narrow technical definition requires a claim of causality, while a broader technical definition allows for any exploration of a model's internals. However, the term also has a narrow cultural definition describing a cultural movement. To understand this semantic drift, we present a history of the NLP interpretability community and the formation of the separate, parallel "mechanistic" interpretability community. Finally, we discuss the broad cultural definition -- encompassing the entire field of interpretability -- and why the traditional NLP interpretability community has come to embrace it. We argue that the polysemy of "mechanistic" is the product of a critical divide within the interpretability community.
Fast Forwarding Low-Rank Training
Sep 06, 2024



Parameter efficient finetuning methods like low-rank adaptation (LoRA) aim to reduce the computational costs of finetuning pretrained Language Models (LMs). Enabled by these low-rank settings, we propose an even more efficient optimization strategy: Fast Forward, a simple and effective approach to accelerate large segments of training. In a Fast Forward stage, we repeat the most recent optimizer step until the loss stops improving on a tiny validation set. By alternating between regular optimization steps and Fast Forward stages, Fast Forward provides up to an 87\% reduction in FLOPs and up to an 81\% reduction in train time over standard SGD with Adam. We validate Fast Forward by finetuning various models on different tasks and demonstrate that it speeds up training without compromising model performance. Additionally, we analyze when and how to apply Fast Forward.