 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Methodologies for Agentic Evaluations Across Domains: Leakage of Sensitive Information, Fraud and Cybersecurity Threats
Jan 22, 2026The rapid rise of autonomous AI systems and advancements in agent capabilities are introducing new risks due to reduced oversight of real-world interactions. Yet agent testing remains nascent and is still a developing science. As AI agents begin to be deployed globally, it is important that they handle different languages and cultures accurately and securely. To address this, participants from The International Network for Advanced AI Measurement, Evaluation and Science, including representatives from Singapore, Japan, Australia, Canada, the European Commission, France, Kenya, South Korea, and the United Kingdom have come together to align approaches to agentic evaluations. This is the third exercise, building on insights from two earlier joint testing exercises conducted by the Network in November 2024 and February 2025. The objective is to further refine best practices for testing advanced AI systems. The exercise was split into two strands: (1) common risks, including leakage of sensitive information and fraud, led by Singapore AISI; and (2) cybersecurity, led by UK AISI. A mix of open and closed-weight models were evaluated against tasks from various public agentic benchmarks. Given the nascency of agentic testing, our primary focus was on understanding methodological issues in conducting such tests, rather than examining test results or model capabilities. This collaboration marks an important step forward as participants work together to advance the science of agentic evaluations.
PolyPythias: Stability and Outliers across Fifty Language Model Pre-Training Runs
Mar 12, 2025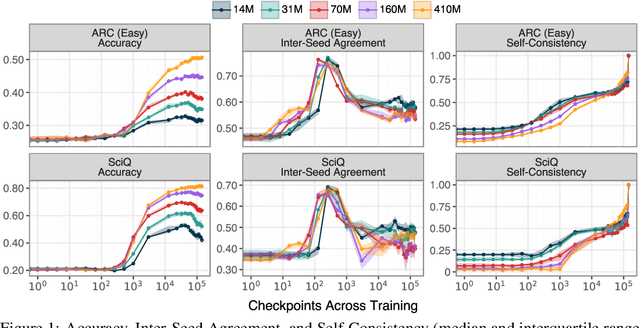

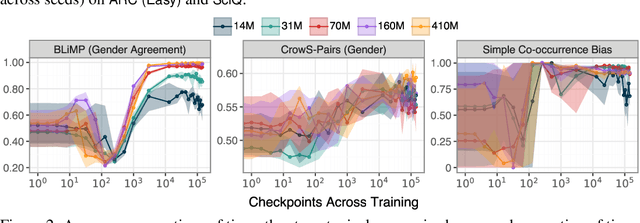
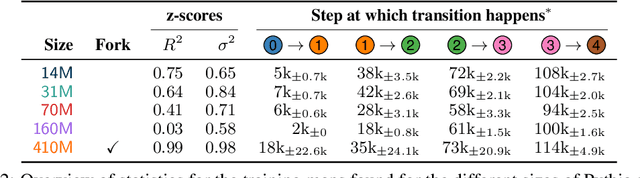
The stability of language model pre-training and its effects on downstream performance are still understudied. Prior work shows that the training process can yield significantly different results in response to slight variations in initial conditions, e.g., the random seed. Crucially, the research community still lacks sufficient resources and tools to systematically investigate pre-training stability, particularly for decoder-only language models. We introduce the PolyPythias, a set of 45 new training runs for the Pythia model suite: 9 new seeds across 5 model sizes, from 14M to 410M parameters, resulting in about 7k new checkpoints that we release. Using these new 45 training runs, in addition to the 5 already available, we study the effects of different initial conditions determined by the seed -- i.e., parameters' initialisation and data order -- on (i) downstream performance, (ii) learned linguistic representations, and (iii) emergence of training phases. In addition to common scaling behaviours, our analyses generally reveal highly consistent training dynamics across both model sizes and initial conditions. Further, the new seeds for each model allow us to identify outlier training runs and delineate their characteristics. Our findings show the potential of using these methods to predict training stability.
Identifying and Adapting Transformer-Components Responsible for Gender Bias in an English Language Model
Oct 19, 2023



Language models (LMs) exhibit and amplify many types of undesirable biases learned from the training data, including gender bias. However, we lack tools for effectively and efficiently changing this behavior without hurting general language modeling performance. In this paper, we study three methods for identifying causal relations between LM components and particular output: causal mediation analysis, automated circuit discovery and our novel, efficient method called DiffMask+ based on differential masking. We apply the methods to GPT-2 small and the problem of gender bias, and use the discovered sets of components to perform parameter-efficient fine-tuning for bias mitigation. Our results show significant overlap in the identified components (despite huge differences in the computational requirements of the methods) as well as success in mitigating gender bias, with less damage to general language modeling compared to full model fine-tuning. However, our work also underscores the difficulty of defining and measuring bias, and the sensitivity of causal discovery procedures to dataset choice. We hope our work can contribute to more attention for dataset development, and lead to more effective mitigation strategies for other types of bias.
ChapGTP, ILLC's Attempt at Raising a BabyLM: Improving Data Efficiency by Automatic Task Formation
Oct 17, 2023We present the submission of the ILLC at the University of Amsterdam to the BabyLM challenge (Warstadt et al., 2023), in the strict-small track. Our final model, ChapGTP, is a masked language model that was trained for 200 epochs, aided by a novel data augmentation technique called Automatic Task Formation. We discuss in detail the performance of this model on the three evaluation suites: BLiMP, (Super)GLUE, and MSGS. Furthermore, we present a wide range of methods that were ultimately not included in the model, but may serve as inspiration for training LMs in low-resource settings.
Pythia: A Suite for Analyzing Large Language Models Across Training and Scaling
Apr 03, 2023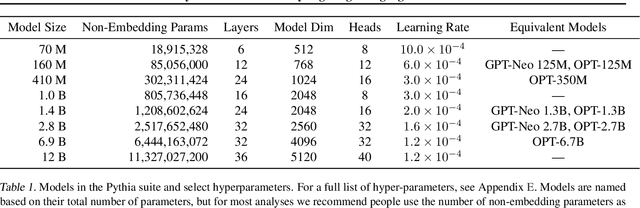
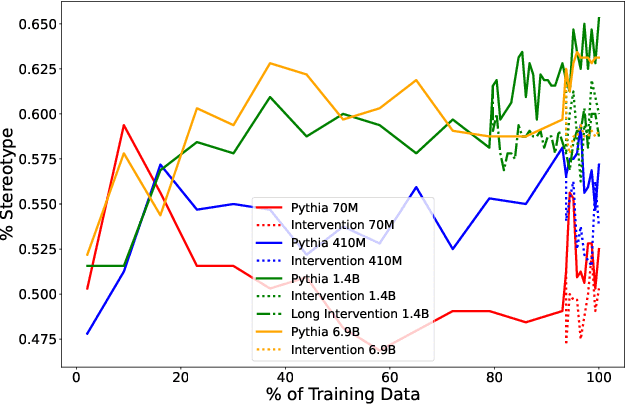

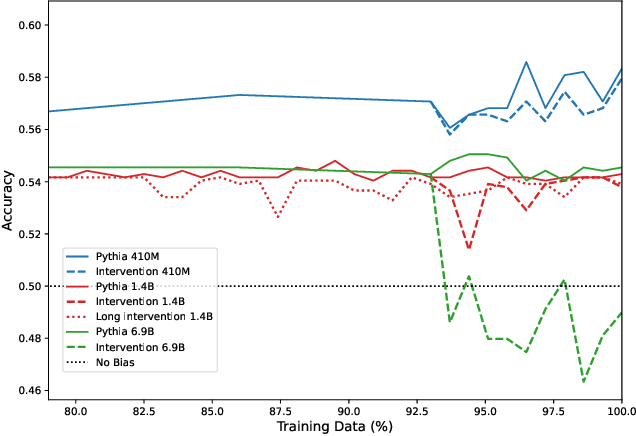
How do large language models (LLMs) develop and evolve over the course of training? How do these patterns change as models scale? To answer these questions, we introduce \textit{Pythia}, a suite of 16 LLMs all trained on public data seen in the exact same order and ranging in size from 70M to 12B parameters. We provide public access to 154 checkpoints for each one of the 16 models, alongside tools to download and reconstruct their exact training dataloaders for further study. We intend \textit{Pythia} to facilitate research in many areas, and we present several case studies including novel results in memorization, term frequency effects on few-shot performance, and reducing gender bias. We demonstrate that this highly controlled setup can be used to yield novel insights toward LLMs and their training dynamics. Trained models, analysis code, training code, and training data can be found at https://github.com/EleutherAI/pythia.
Inseq: An Interpretability Toolkit for Sequence Generation Models
Feb 27, 2023Past work in natural language processing interpretability focused mainly on popular classification tasks while largely overlooking generation settings, partly due to a lack of dedicated tools. In this work, we introduce Inseq, a Python library to democratize access to interpretability analyses of sequence generation models. Inseq enables intuitive and optimized extraction of models' internal information and feature importance scores for popular decoder-only and encoder-decoder Transformers architectures. We showcase its potential by adopting it to highlight gender biases in machine translation models and locate factual knowledge inside GPT-2. Thanks to its extensible interface supporting cutting-edge techniques such as contrastive feature attribution, Inseq can drive future advances in explainable natural language generation, centralizing good practices and enabling fair and reproducible model evaluations.
Undesirable biases in NLP: Averting a crisis of measurement
Nov 24, 2022



As Natural Language Processing (NLP) technology rapidly develops and spreads into daily life, it becomes crucial to anticipate how its use could harm people. However, our ways of assessing the biases of NLP models have not kept up. While especially the detection of English gender bias in such models has enjoyed increasing research attention, many of the measures face serious problems, as it is often unclear what they actually measure and how much they are subject to measurement error. In this paper, we provide an interdisciplinary approach to discussing the issue of NLP model bias by adopting the lens of psychometrics -- a field specialized in the measurement of concepts like bias that are not directly observable. We pair an introduction of relevant psychometric concepts with a discussion of how they could be used to evaluate and improve bias measures. We also argue that adopting psychometric vocabulary and methodology can make NLP bias research more efficient and transparent.
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Nov 09, 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.
The Birth of Bias: A case study on the evolution of gender bias in an English language model
Jul 21, 2022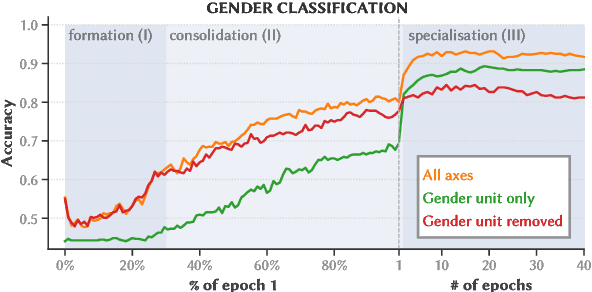
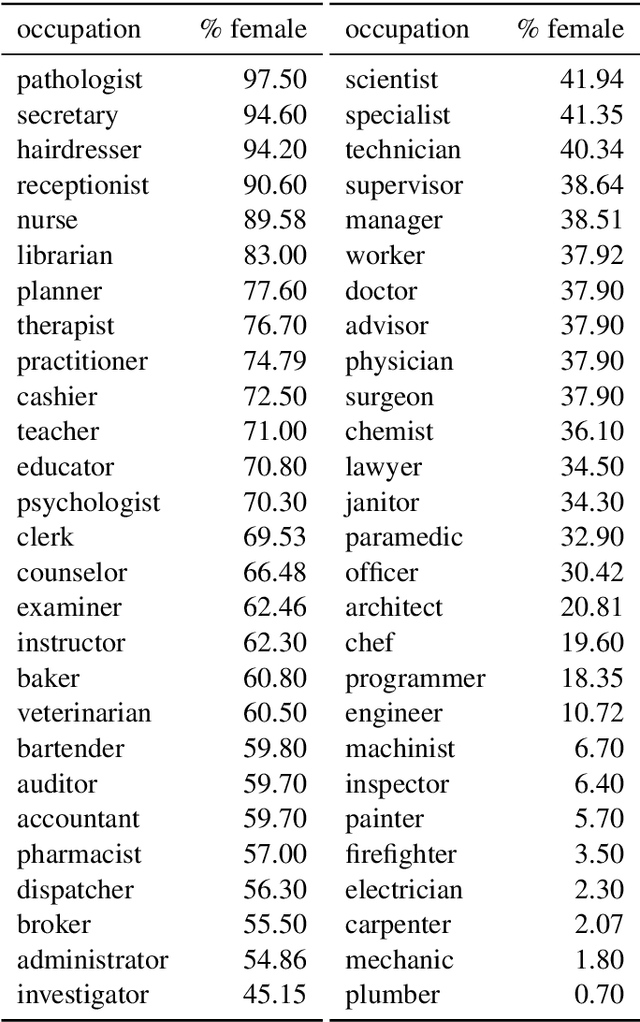
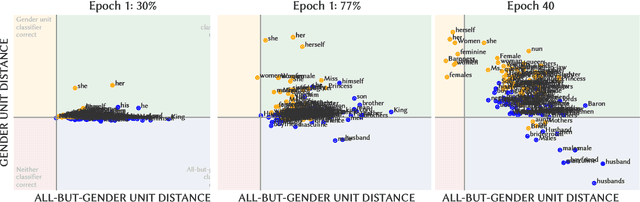

Detecting and mitigating harmful biases in modern language models are widely recognized as crucial, open problems. In this paper, we take a step back and investigate how language models come to be biased in the first place. We use a relatively small language model, using the LSTM architecture trained on an English Wikipedia corpus. With full access to the data and to the model parameters as they change during every step while training, we can map in detail how the representation of gender develops, what patterns in the dataset drive this, and how the model's internal state relates to the bias in a downstream task (semantic textual similarity). We find that the representation of gender is dynamic and identify different phases during training. Furthermore, we show that gender information is represented increasingly locally in the input embeddings of the model and that, as a consequence, debiasing these can be effective in reducing the downstream bias. Monitoring the training dynamics, allows us to detect an asymmetry in how the female and male gender are represented in the input embeddings. This is important, as it may cause naive mitigation strategies to introduce new undesirable biases. We discuss the relevance of the findings for mitigation strategies more generally and the prospects of generalizing our methods to larger language models, the Transformer architecture, other languages and other undesirable biases.
The Grammar of Emergent Languages
Oct 09, 2020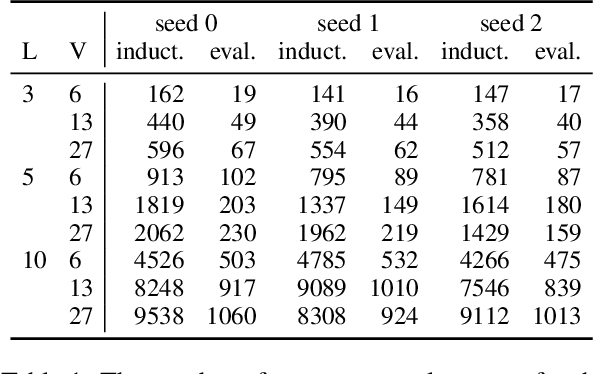

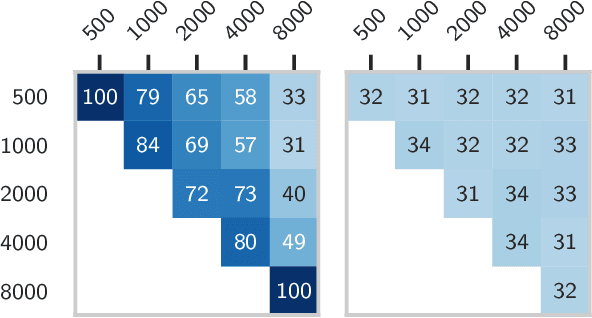
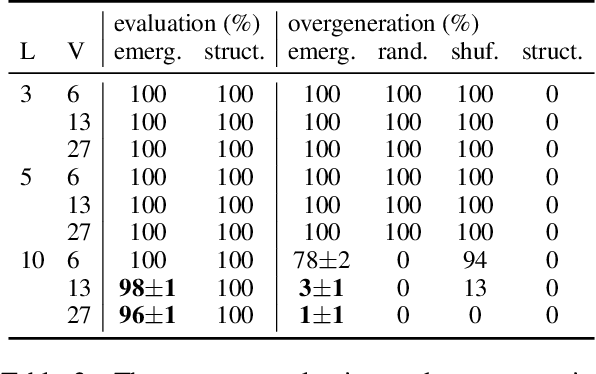
In this paper, we consider the syntactic properties of languages emerged in referential games, using unsupervised grammar induction (UGI) techniques originally designed to analyse natural language. We show that the considered UGI techniques are appropriate to analyse emergent languages and we then study if the languages that emerge in a typical referential game setup exhibit syntactic structure, and to what extent this depends on the maximum message length and number of symbols that the agents are allowed to use. Our experiments demonstrate that a certain message length and vocabulary size are required for structure to emerge, but they also illustrate that more sophisticated game scenarios are required to obtain syntactic properties more akin to those observed in human language. We argue that UGI techniques should be part of the standard toolkit for analysing emergent languages and release a comprehensive library to facilitate such analysis for future researchers.