 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA (More) Realistic Evaluation Setup for Generalisation of Community Models on Malicious Content Detection
Apr 02, 2024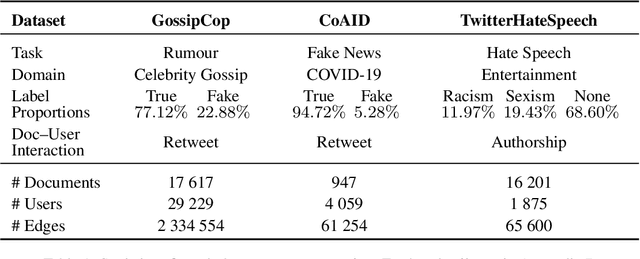
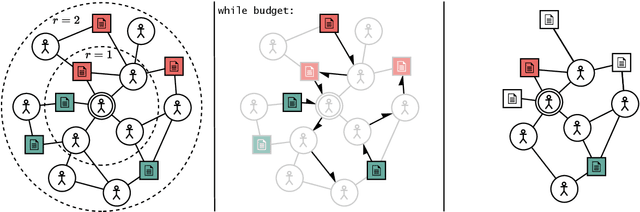
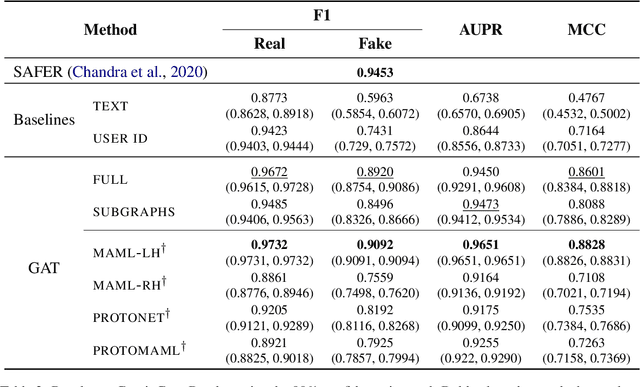
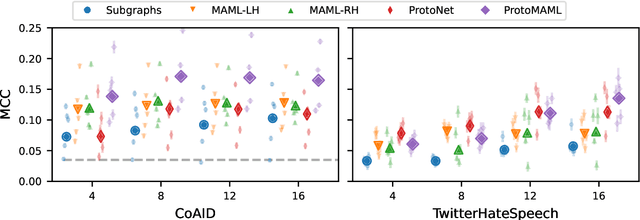
Community models for malicious content detection, which take into account the context from a social graph alongside the content itself, have shown remarkable performance on benchmark datasets. Yet, misinformation and hate speech continue to propagate on social media networks. This mismatch can be partially attributed to the limitations of current evaluation setups that neglect the rapid evolution of online content and the underlying social graph. In this paper, we propose a novel evaluation setup for model generalisation based on our few-shot subgraph sampling approach. This setup tests for generalisation through few labelled examples in local explorations of a larger graph, emulating more realistic application settings. We show this to be a challenging inductive setup, wherein strong performance on the training graph is not indicative of performance on unseen tasks, domains, or graph structures. Lastly, we show that graph meta-learners trained with our proposed few-shot subgraph sampling outperform standard community models in the inductive setup. We make our code publicly available.
Identifying and Adapting Transformer-Components Responsible for Gender Bias in an English Language Model
Oct 19, 2023



Language models (LMs) exhibit and amplify many types of undesirable biases learned from the training data, including gender bias. However, we lack tools for effectively and efficiently changing this behavior without hurting general language modeling performance. In this paper, we study three methods for identifying causal relations between LM components and particular output: causal mediation analysis, automated circuit discovery and our novel, efficient method called DiffMask+ based on differential masking. We apply the methods to GPT-2 small and the problem of gender bias, and use the discovered sets of components to perform parameter-efficient fine-tuning for bias mitigation. Our results show significant overlap in the identified components (despite huge differences in the computational requirements of the methods) as well as success in mitigating gender bias, with less damage to general language modeling compared to full model fine-tuning. However, our work also underscores the difficulty of defining and measuring bias, and the sensitivity of causal discovery procedures to dataset choice. We hope our work can contribute to more attention for dataset development, and lead to more effective mitigation strategies for other types of bias.