 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSteerable Cultural Preference Optimization of Reward Models
Jun 17, 2026It is essential for large language model (LLM) technology to serve many different cultural sub-communities in a manner that is acceptable to each community. However, research on LLM alignment has so far predominantly focused on predicting a unified response preference of annotators from certain regions. This paper aims to advance the development of alignment models with a more global outlook, that are able to accurately represent the preferences of subcommunities and do not exhibit excessive bias towards any of them. We focus on the development of reward models for this purpose and present a novel reward model training algorithm (SCPO) that can incorporate diverse cultural preferences in a balanced manner. Our method results in performance increases of the minority reward model of up to 7 points over the baseline model across two datasets, PRISM and GlobalOpinionQA, and across 7 countries. SCPO is up to 280% more training data-efficient than full-data finetuning of reward models. In addition, we perform analysis of bias by separately evaluating on the preference of subcommunities and show that excessive bias is mitigated via our weighting method. Our code is available at https://github.com/minsik-ai/Steerable-Cultural-Preference
The Roots of Performance Disparity in Multilingual Language Models: Intrinsic Modeling Difficulty or Design Choices?
Jan 12, 2026Multilingual language models (LMs) promise broader NLP access, yet current systems deliver uneven performance across the world's languages. This survey examines why these gaps persist and whether they reflect intrinsic linguistic difficulty or modeling artifacts. We organize the literature around two questions: do linguistic disparities arise from representation and allocation choices (e.g., tokenization, encoding, data exposure, parameter sharing) rather than inherent complexity; and which design choices mitigate inequities across typologically diverse languages. We review linguistic features, such as orthography, morphology, lexical diversity, syntax, information density, and typological distance, linking each to concrete modeling mechanisms. Gaps often shrink when segmentation, encoding, and data exposure are normalized, suggesting much apparent difficulty stems from current modeling choices. We synthesize these insights into design recommendations for tokenization, sampling, architectures, and evaluation to support more balanced multilingual LMs.
NeuroAda: Activating Each Neuron's Potential for Parameter-Efficient Fine-Tuning
Oct 21, 2025



Existing parameter-efficient fine-tuning (PEFT) methods primarily fall into two categories: addition-based and selective in-situ adaptation. The former, such as LoRA, introduce additional modules to adapt the model to downstream tasks, offering strong memory efficiency. However, their representational capacity is often limited, making them less suitable for fine-grained adaptation. In contrast, the latter directly fine-tunes a carefully chosen subset of the original model parameters, allowing for more precise and effective adaptation, but at the cost of significantly increased memory consumption. To reconcile this trade-off, we propose NeuroAda, a novel PEFT method that enables fine-grained model finetuning while maintaining high memory efficiency. Our approach first identifies important parameters (i.e., connections within the network) as in selective adaptation, and then introduces bypass connections for these selected parameters. During finetuning, only the bypass connections are updated, leaving the original model parameters frozen. Empirical results on 23+ tasks spanning both natural language generation and understanding demonstrate that NeuroAda achieves state-of-the-art performance with as little as $\leq \textbf{0.02}\%$ trainable parameters, while reducing CUDA memory usage by up to 60%. We release our code here: https://github.com/FightingFighting/NeuroAda.git.
Best-of-L: Cross-Lingual Reward Modeling for Mathematical Reasoning
Sep 19, 2025While the reasoning abilities of large language models (LLMs) continue to advance, it remains unclear how such ability varies across languages in multilingual LLMs and whether different languages produce reasoning paths that complement each other. To investigate this question, we train a reward model to rank generated responses for a given question across languages. Our results show that our cross-lingual reward model substantially improves mathematical reasoning performance compared to using reward modeling within a single language, benefiting even high-resource languages. While English often exhibits the highest performance in multilingual models, we find that cross-lingual sampling particularly benefits English under low sampling budgets. Our findings reveal new opportunities to improve multilingual reasoning by leveraging the complementary strengths of diverse languages.
Cultural Evaluations of Vision-Language Models Have a Lot to Learn from Cultural Theory
May 28, 2025Modern vision-language models (VLMs) often fail at cultural competency evaluations and benchmarks. Given the diversity of applications built upon VLMs, there is renewed interest in understanding how they encode cultural nuances. While individual aspects of this problem have been studied, we still lack a comprehensive framework for systematically identifying and annotating the nuanced cultural dimensions present in images for VLMs. This position paper argues that foundational methodologies from visual culture studies (cultural studies, semiotics, and visual studies) are necessary for cultural analysis of images. Building upon this review, we propose a set of five frameworks, corresponding to cultural dimensions, that must be considered for a more complete analysis of the cultural competencies of VLMs.
Beyond Words: Exploring Cultural Value Sensitivity in Multimodal Models
Feb 18, 2025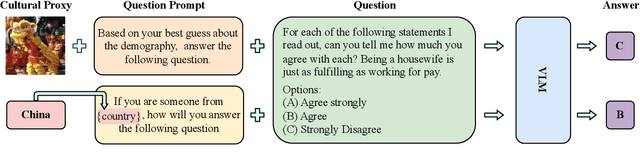


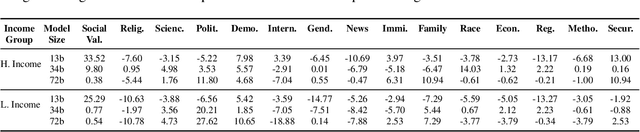
Investigating value alignment in Large Language Models (LLMs) based on cultural context has become a critical area of research. However, similar biases have not been extensively explored in large vision-language models (VLMs). As the scale of multimodal models continues to grow, it becomes increasingly important to assess whether images can serve as reliable proxies for culture and how these values are embedded through the integration of both visual and textual data. In this paper, we conduct a thorough evaluation of multimodal model at different scales, focusing on their alignment with cultural values. Our findings reveal that, much like LLMs, VLMs exhibit sensitivity to cultural values, but their performance in aligning with these values is highly context-dependent. While VLMs show potential in improving value understanding through the use of images, this alignment varies significantly across contexts highlighting the complexities and underexplored challenges in the alignment of multimodal models.
Proactive Gradient Conflict Mitigation in Multi-Task Learning: A Sparse Training Perspective
Nov 27, 2024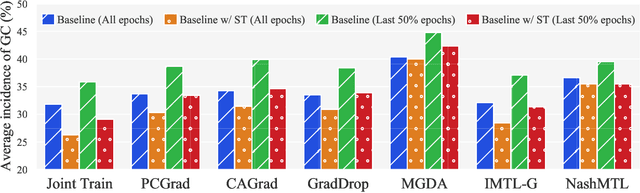
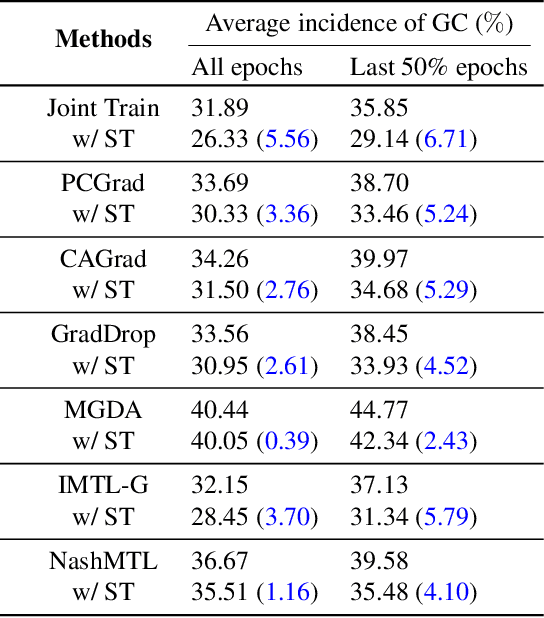
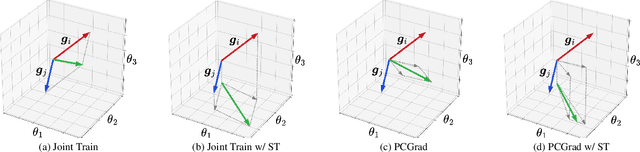
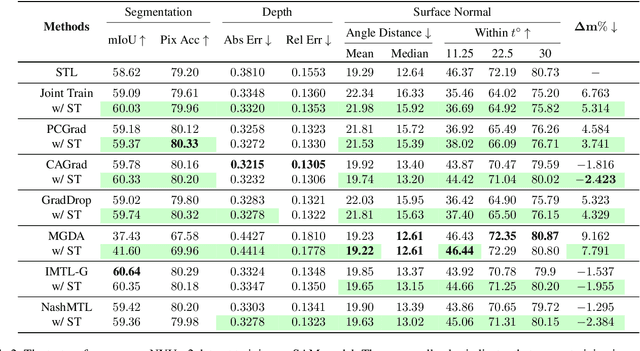
Advancing towards generalist agents necessitates the concurrent processing of multiple tasks using a unified model, thereby underscoring the growing significance of simultaneous model training on multiple downstream tasks. A common issue in multi-task learning is the occurrence of gradient conflict, which leads to potential competition among different tasks during joint training. This competition often results in improvements in one task at the expense of deterioration in another. Although several optimization methods have been developed to address this issue by manipulating task gradients for better task balancing, they cannot decrease the incidence of gradient conflict. In this paper, we systematically investigate the occurrence of gradient conflict across different methods and propose a strategy to reduce such conflicts through sparse training (ST), wherein only a portion of the model's parameters are updated during training while keeping the rest unchanged. Our extensive experiments demonstrate that ST effectively mitigates conflicting gradients and leads to superior performance. Furthermore, ST can be easily integrated with gradient manipulation techniques, thus enhancing their effectiveness.
Cross-modal Information Flow in Multimodal Large Language Models
Nov 27, 2024The recent advancements in auto-regressive multimodal large language models (MLLMs) have demonstrated promising progress for vision-language tasks. While there exists a variety of studies investigating the processing of linguistic information within large language models, little is currently known about the inner working mechanism of MLLMs and how linguistic and visual information interact within these models. In this study, we aim to fill this gap by examining the information flow between different modalities -- language and vision -- in MLLMs, focusing on visual question answering. Specifically, given an image-question pair as input, we investigate where in the model and how the visual and linguistic information are combined to generate the final prediction. Conducting experiments with a series of models from the LLaVA series, we find that there are two distinct stages in the process of integration of the two modalities. In the lower layers, the model first transfers the more general visual features of the whole image into the representations of (linguistic) question tokens. In the middle layers, it once again transfers visual information about specific objects relevant to the question to the respective token positions of the question. Finally, in the higher layers, the resulting multimodal representation is propagated to the last position of the input sequence for the final prediction. Overall, our findings provide a new and comprehensive perspective on the spatial and functional aspects of image and language processing in the MLLMs, thereby facilitating future research into multimodal information localization and editing.
Self-Alignment: Improving Alignment of Cultural Values in LLMs via In-Context Learning
Aug 29, 2024Improving the alignment of Large Language Models (LLMs) with respect to the cultural values that they encode has become an increasingly important topic. In this work, we study whether we can exploit existing knowledge about cultural values at inference time to adjust model responses to cultural value probes. We present a simple and inexpensive method that uses a combination of in-context learning (ICL) and human survey data, and show that we can improve the alignment to cultural values across 5 models that include both English-centric and multilingual LLMs. Importantly, we show that our method could prove useful in test languages other than English and can improve alignment to the cultural values that correspond to a range of culturally diverse countries.
Density Matrices for Metaphor Understanding
Aug 12, 2024
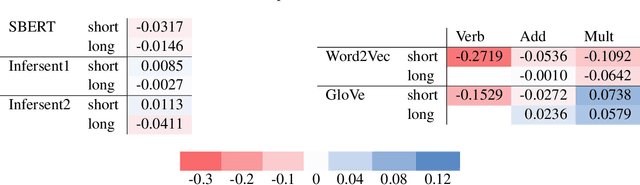


In physics, density matrices are used to represent mixed states, i.e. probabilistic mixtures of pure states. This concept has previously been used to model lexical ambiguity. In this paper, we consider metaphor as a type of lexical ambiguity, and examine whether metaphorical meaning can be effectively modelled using mixtures of word senses. We find that modelling metaphor is significantly more difficult than other kinds of lexical ambiguity, but that our best-performing density matrix method outperforms simple baselines as well as some neural language models.
* In Proceedings QPL 2024, arXiv:2408.05113