 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA-MapReduce: Executing Wide Search via Agentic MapReduce
Feb 01, 2026Contemporary large language model (LLM)-based multi-agent systems exhibit systematic advantages in deep research tasks, which emphasize iterative, vertically structured information seeking. However, when confronted with wide search tasks characterized by large-scale, breadth-oriented retrieval, existing agentic frameworks, primarily designed around sequential, vertically structured reasoning, remain stuck in expansive search objectives and inefficient long-horizon execution. To bridge this gap, we propose A-MapReduce, a MapReduce paradigm-inspired multi-agent execution framework that recasts wide search as a horizontally structured retrieval problem. Concretely, A-MapReduce implements parallel processing of massive retrieval targets through task-adaptive decomposition and structured result aggregation. Meanwhile, it leverages experiential memory to drive the continual evolution of query-conditioned task allocation and recomposition, enabling progressive improvement in large-scale wide-search regimes. Extensive experiments on five agentic benchmarks demonstrate that A-MapReduce is (i) high-performing, achieving state-of-the-art performance on WideSearch and DeepWideSearch, and delivering 5.11% - 17.50% average Item F1 improvements compared with strong baselines with OpenAI o3 or Gemini 2.5 Pro backbones; (ii) cost-effective and efficient, delivering superior cost-performance trade-offs and reducing running time by 45.8\% compared to representative multi-agent baselines. The code is available at https://github.com/mingju-c/AMapReduce.
Proactive Gradient Conflict Mitigation in Multi-Task Learning: A Sparse Training Perspective
Nov 27, 2024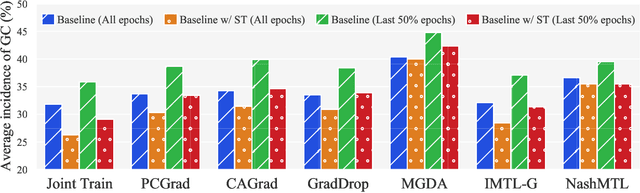
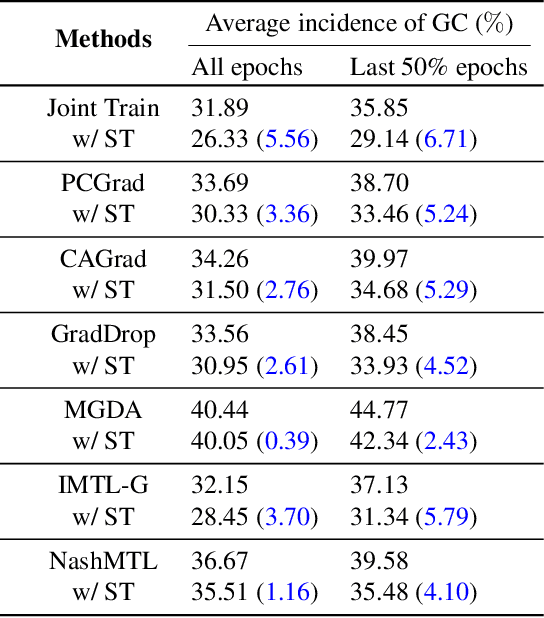
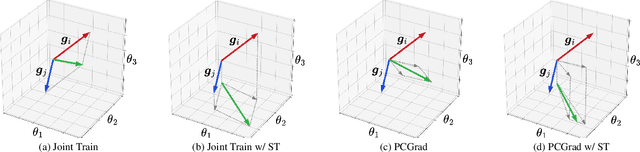
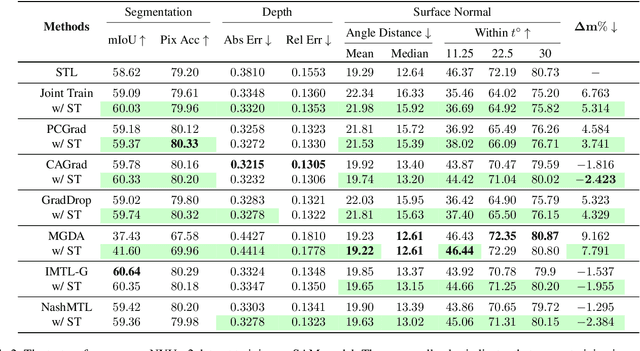
Advancing towards generalist agents necessitates the concurrent processing of multiple tasks using a unified model, thereby underscoring the growing significance of simultaneous model training on multiple downstream tasks. A common issue in multi-task learning is the occurrence of gradient conflict, which leads to potential competition among different tasks during joint training. This competition often results in improvements in one task at the expense of deterioration in another. Although several optimization methods have been developed to address this issue by manipulating task gradients for better task balancing, they cannot decrease the incidence of gradient conflict. In this paper, we systematically investigate the occurrence of gradient conflict across different methods and propose a strategy to reduce such conflicts through sparse training (ST), wherein only a portion of the model's parameters are updated during training while keeping the rest unchanged. Our extensive experiments demonstrate that ST effectively mitigates conflicting gradients and leads to superior performance. Furthermore, ST can be easily integrated with gradient manipulation techniques, thus enhancing their effectiveness.
On the Limitations and Prospects of Machine Unlearning for Generative AI
Aug 01, 2024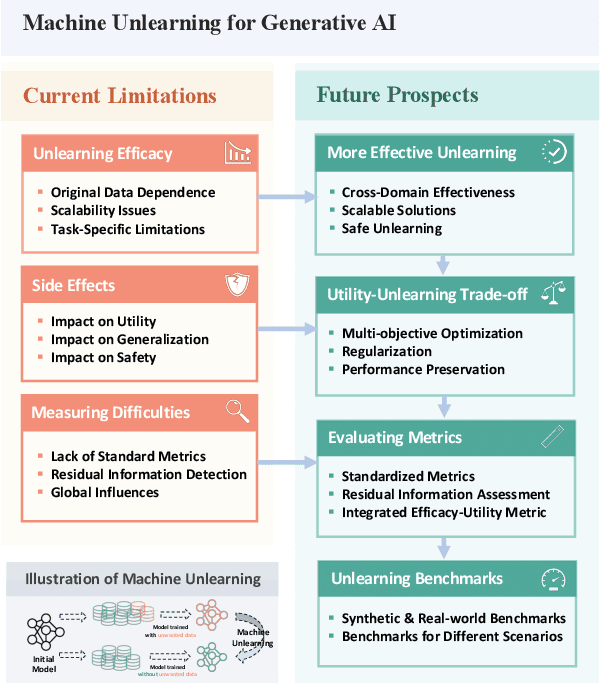
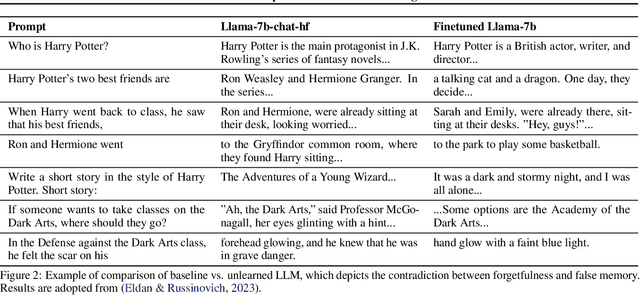
Generative AI (GenAI), which aims to synthesize realistic and diverse data samples from latent variables or other data modalities, has achieved remarkable results in various domains, such as natural language, images, audio, and graphs. However, they also pose challenges and risks to data privacy, security, and ethics. Machine unlearning is the process of removing or weakening the influence of specific data samples or features from a trained model, without affecting its performance on other data or tasks. While machine unlearning has shown significant efficacy in traditional machine learning tasks, it is still unclear if it could help GenAI become safer and aligned with human desire. To this end, this position paper provides an in-depth discussion of the machine unlearning approaches for GenAI. Firstly, we formulate the problem of machine unlearning tasks on GenAI and introduce the background. Subsequently, we systematically examine the limitations of machine unlearning on GenAI models by focusing on the two representative branches: LLMs and image generative (diffusion) models. Finally, we provide our prospects mainly from three aspects: benchmark, evaluation metrics, and utility-unlearning trade-off, and conscientiously advocate for the future development of this field.
Unlearning Concepts in Diffusion Model via Concept Domain Correction and Concept Preserving Gradient
May 24, 2024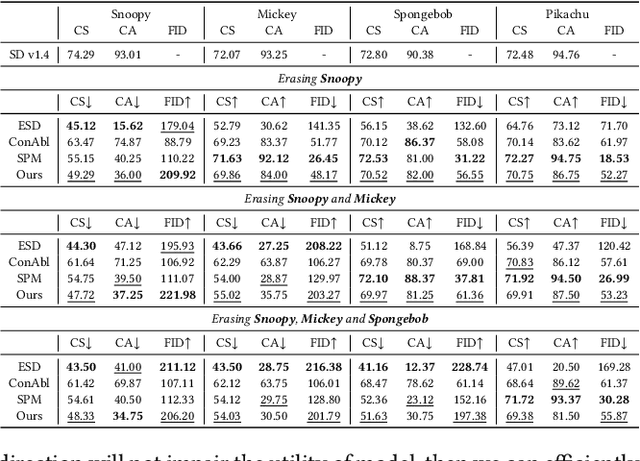
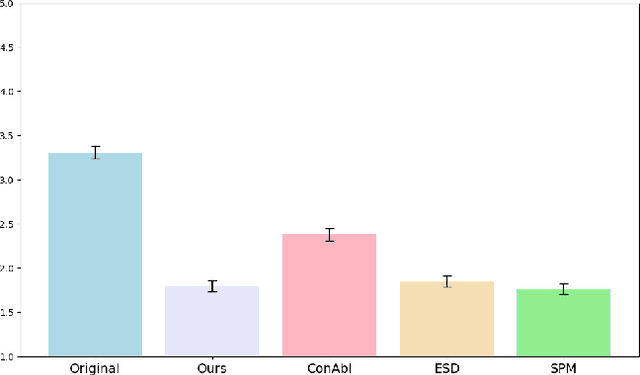

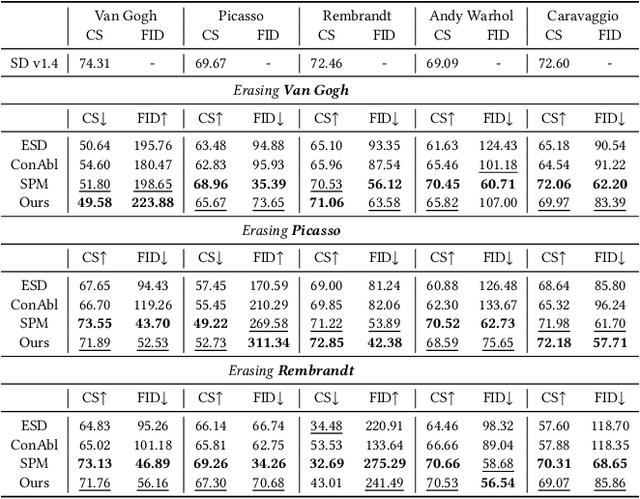
Current text-to-image diffusion models have achieved groundbreaking results in image generation tasks. However, the unavoidable inclusion of sensitive information during pre-training introduces significant risks such as copyright infringement and privacy violations in the generated images. Machine Unlearning (MU) provides a effective way to the sensitive concepts captured by the model, has been shown to be a promising approach to addressing these issues. Nonetheless, existing MU methods for concept erasure encounter two primary bottlenecks: 1) generalization issues, where concept erasure is effective only for the data within the unlearn set, and prompts outside the unlearn set often still result in the generation of sensitive concepts; and 2) utility drop, where erasing target concepts significantly degrades the model's performance. To this end, this paper first proposes a concept domain correction framework for unlearning concepts in diffusion models. By aligning the output domains of sensitive concepts and anchor concepts through adversarial training, we enhance the generalizability of the unlearning results. Secondly, we devise a concept-preserving scheme based on gradient surgery. This approach alleviates the parts of the unlearning gradient that contradict the relearning gradient, ensuring that the process of unlearning minimally disrupts the model's performance. Finally, extensive experiments validate the effectiveness of our model, demonstrating our method's capability to address the challenges of concept unlearning in diffusion models while preserving model utility.
Incremental Residual Concept Bottleneck Models
Apr 13, 2024



Concept Bottleneck Models (CBMs) map the black-box visual representations extracted by deep neural networks onto a set of interpretable concepts and use the concepts to make predictions, enhancing the transparency of the decision-making process. Multimodal pre-trained models can match visual representations with textual concept embeddings, allowing for obtaining the interpretable concept bottleneck without the expertise concept annotations. Recent research has focused on the concept bank establishment and the high-quality concept selection. However, it is challenging to construct a comprehensive concept bank through humans or large language models, which severely limits the performance of CBMs. In this work, we propose the Incremental Residual Concept Bottleneck Model (Res-CBM) to address the challenge of concept completeness. Specifically, the residual concept bottleneck model employs a set of optimizable vectors to complete missing concepts, then the incremental concept discovery module converts the complemented vectors with unclear meanings into potential concepts in the candidate concept bank. Our approach can be applied to any user-defined concept bank, as a post-hoc processing method to enhance the performance of any CBMs. Furthermore, to measure the descriptive efficiency of CBMs, the Concept Utilization Efficiency (CUE) metric is proposed. Experiments show that the Res-CBM outperforms the current state-of-the-art methods in terms of both accuracy and efficiency and achieves comparable performance to black-box models across multiple datasets.
Robust Multi-Task Learning with Excess Risks
Feb 14, 2024



Multi-task learning (MTL) considers learning a joint model for multiple tasks by optimizing a convex combination of all task losses. To solve the optimization problem, existing methods use an adaptive weight updating scheme, where task weights are dynamically adjusted based on their respective losses to prioritize difficult tasks. However, these algorithms face a great challenge whenever label noise is present, in which case excessive weights tend to be assigned to noisy tasks that have relatively large Bayes optimal errors, thereby overshadowing other tasks and causing performance to drop across the board. To overcome this limitation, we propose Multi-Task Learning with Excess Risks (ExcessMTL), an excess risk-based task balancing method that updates the task weights by their distances to convergence instead. Intuitively, ExcessMTL assigns higher weights to worse-trained tasks that are further from convergence. To estimate the excess risks, we develop an efficient and accurate method with Taylor approximation. Theoretically, we show that our proposed algorithm achieves convergence guarantees and Pareto stationarity. Empirically, we evaluate our algorithm on various MTL benchmarks and demonstrate its superior performance over existing methods in the presence of label noise.
Gradient-based Parameter Selection for Efficient Fine-Tuning
Dec 15, 2023



With the growing size of pre-trained models, full fine-tuning and storing all the parameters for various downstream tasks is costly and infeasible. In this paper, we propose a new parameter-efficient fine-tuning method, Gradient-based Parameter Selection (GPS), demonstrating that only tuning a few selected parameters from the pre-trained model while keeping the remainder of the model frozen can generate similar or better performance compared with the full model fine-tuning method. Different from the existing popular and state-of-the-art parameter-efficient fine-tuning approaches, our method does not introduce any additional parameters and computational costs during both the training and inference stages. Another advantage is the model-agnostic and non-destructive property, which eliminates the need for any other design specific to a particular model. Compared with the full fine-tuning, GPS achieves 3.33% (91.78% vs. 88.45%, FGVC) and 9.61% (73.1% vs. 65.57%, VTAB) improvement of the accuracy with tuning only 0.36% parameters of the pre-trained model on average over 24 image classification tasks; it also demonstrates a significant improvement of 17% and 16.8% in mDice and mIoU, respectively, on medical image segmentation task. Moreover, GPS achieves state-of-the-art performance compared with existing PEFT methods.
Marketing Budget Allocation with Offline Constrained Deep Reinforcement Learning
Sep 06, 2023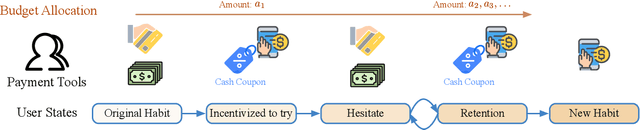
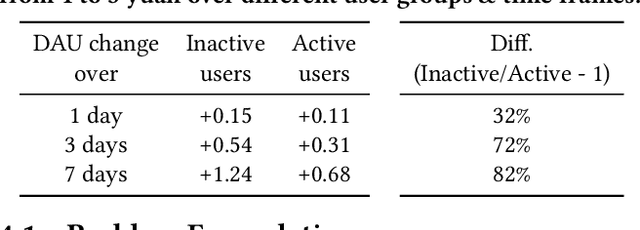
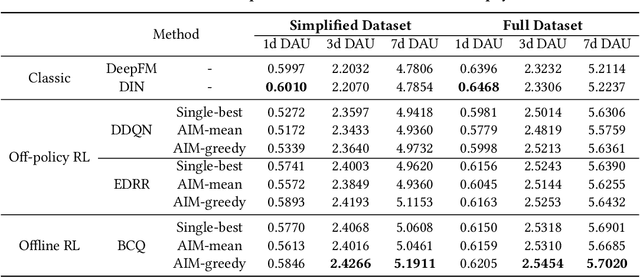
We study the budget allocation problem in online marketing campaigns that utilize previously collected offline data. We first discuss the long-term effect of optimizing marketing budget allocation decisions in the offline setting. To overcome the challenge, we propose a novel game-theoretic offline value-based reinforcement learning method using mixed policies. The proposed method reduces the need to store infinitely many policies in previous methods to only constantly many policies, which achieves nearly optimal policy efficiency, making it practical and favorable for industrial usage. We further show that this method is guaranteed to converge to the optimal policy, which cannot be achieved by previous value-based reinforcement learning methods for marketing budget allocation. Our experiments on a large-scale marketing campaign with tens-of-millions users and more than one billion budget verify the theoretical results and show that the proposed method outperforms various baseline methods. The proposed method has been successfully deployed to serve all the traffic of this marketing campaign.
Model-free Reinforcement Learning with Stochastic Reward Stabilization for Recommender Systems
Aug 25, 2023Model-free RL-based recommender systems have recently received increasing research attention due to their capability to handle partial feedback and long-term rewards. However, most existing research has ignored a critical feature in recommender systems: one user's feedback on the same item at different times is random. The stochastic rewards property essentially differs from that in classic RL scenarios with deterministic rewards, which makes RL-based recommender systems much more challenging. In this paper, we first demonstrate in a simulator environment where using direct stochastic feedback results in a significant drop in performance. Then to handle the stochastic feedback more efficiently, we design two stochastic reward stabilization frameworks that replace the direct stochastic feedback with that learned by a supervised model. Both frameworks are model-agnostic, i.e., they can effectively utilize various supervised models. We demonstrate the superiority of the proposed frameworks over different RL-based recommendation baselines with extensive experiments on a recommendation simulator as well as an industrial-level recommender system.
Revisiting Adversarial Attacks on Graph Neural Networks for Graph Classification
Aug 13, 2022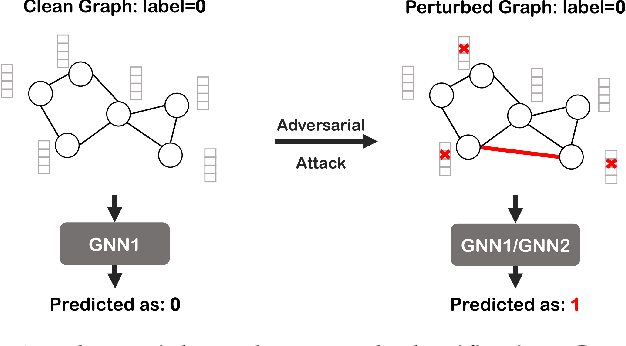
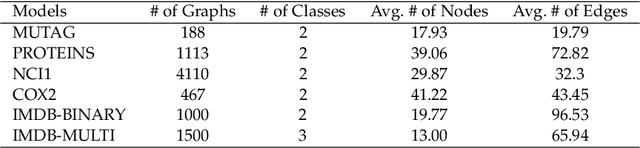
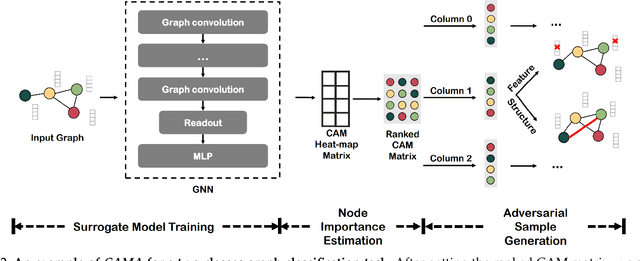
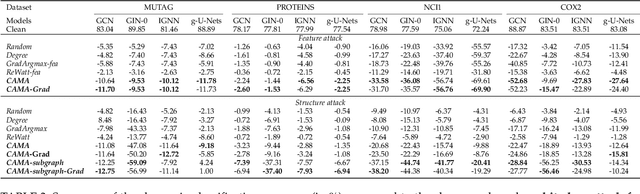
Graph neural networks (GNNs) have achieved tremendous success in the task of graph classification and diverse downstream real-world applications. Despite their success, existing approaches are either limited to structure attacks or restricted to local information. This calls for a more general attack framework on graph classification, which faces significant challenges due to the complexity of generating local-node-level adversarial examples using the global-graph-level information. To address this "global-to-local" problem, we present a general framework CAMA to generate adversarial examples by manipulating graph structure and node features in a hierarchical style. Specifically, we make use of Graph Class Activation Mapping and its variant to produce node-level importance corresponding to the graph classification task. Then through a heuristic design of algorithms, we can perform both feature and structure attacks under unnoticeable perturbation budgets with the help of both node-level and subgraph-level importance. Experiments towards attacking four state-of-the-art graph classification models on six real-world benchmarks verify the flexibility and effectiveness of our framework.