 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention
Jun 16, 2025



We introduce MiniMax-M1, the world's first open-weight, large-scale hybrid-attention reasoning model. MiniMax-M1 is powered by a hybrid Mixture-of-Experts (MoE) architecture combined with a lightning attention mechanism. The model is developed based on our previous MiniMax-Text-01 model, which contains a total of 456 billion parameters with 45.9 billion parameters activated per token. The M1 model natively supports a context length of 1 million tokens, 8x the context size of DeepSeek R1. Furthermore, the lightning attention mechanism in MiniMax-M1 enables efficient scaling of test-time compute. These properties make M1 particularly suitable for complex tasks that require processing long inputs and thinking extensively. MiniMax-M1 is trained using large-scale reinforcement learning (RL) on diverse problems including sandbox-based, real-world software engineering environments. In addition to M1's inherent efficiency advantage for RL training, we propose CISPO, a novel RL algorithm to further enhance RL efficiency. CISPO clips importance sampling weights rather than token updates, outperforming other competitive RL variants. Combining hybrid-attention and CISPO enables MiniMax-M1's full RL training on 512 H800 GPUs to complete in only three weeks, with a rental cost of just $534,700. We release two versions of MiniMax-M1 models with 40K and 80K thinking budgets respectively, where the 40K model represents an intermediate phase of the 80K training. Experiments on standard benchmarks show that our models are comparable or superior to strong open-weight models such as the original DeepSeek-R1 and Qwen3-235B, with particular strengths in complex software engineering, tool utilization, and long-context tasks. We publicly release MiniMax-M1 at https://github.com/MiniMax-AI/MiniMax-M1.
MiniCPM-V: A GPT-4V Level MLLM on Your Phone
Aug 03, 2024

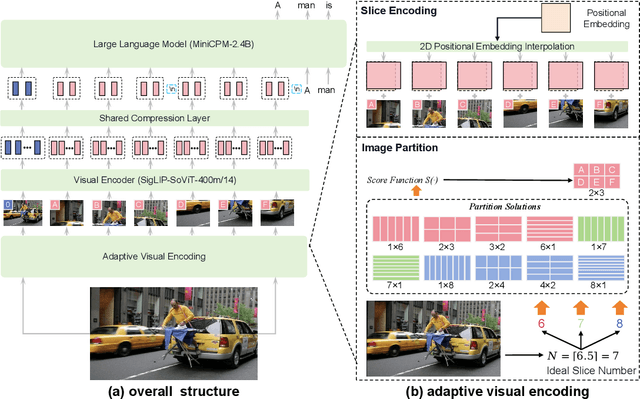
The recent surge of Multimodal Large Language Models (MLLMs) has fundamentally reshaped the landscape of AI research and industry, shedding light on a promising path toward the next AI milestone. However, significant challenges remain preventing MLLMs from being practical in real-world applications. The most notable challenge comes from the huge cost of running an MLLM with a massive number of parameters and extensive computation. As a result, most MLLMs need to be deployed on high-performing cloud servers, which greatly limits their application scopes such as mobile, offline, energy-sensitive, and privacy-protective scenarios. In this work, we present MiniCPM-V, a series of efficient MLLMs deployable on end-side devices. By integrating the latest MLLM techniques in architecture, pretraining and alignment, the latest MiniCPM-Llama3-V 2.5 has several notable features: (1) Strong performance, outperforming GPT-4V-1106, Gemini Pro and Claude 3 on OpenCompass, a comprehensive evaluation over 11 popular benchmarks, (2) strong OCR capability and 1.8M pixel high-resolution image perception at any aspect ratio, (3) trustworthy behavior with low hallucination rates, (4) multilingual support for 30+ languages, and (5) efficient deployment on mobile phones. More importantly, MiniCPM-V can be viewed as a representative example of a promising trend: The model sizes for achieving usable (e.g., GPT-4V) level performance are rapidly decreasing, along with the fast growth of end-side computation capacity. This jointly shows that GPT-4V level MLLMs deployed on end devices are becoming increasingly possible, unlocking a wider spectrum of real-world AI applications in the near future.
Face4RAG: Factual Consistency Evaluation for Retrieval Augmented Generation in Chinese
Jul 01, 2024



The prevailing issue of factual inconsistency errors in conventional Retrieval Augmented Generation (RAG) motivates the study of Factual Consistency Evaluation (FCE). Despite the various FCE methods proposed earlier, these methods are evaluated on datasets generated by specific Large Language Models (LLMs). Without a comprehensive benchmark, it remains unexplored how these FCE methods perform on other LLMs with different error distributions or even unseen error types, as these methods may fail to detect the error types generated by other LLMs. To fill this gap, in this paper, we propose the first comprehensive FCE benchmark \emph{Face4RAG} for RAG independent of the underlying LLM. Our benchmark consists of a synthetic dataset built upon a carefully designed typology for factuality inconsistency error and a real-world dataset constructed from six commonly used LLMs, enabling evaluation of FCE methods on specific error types or real-world error distributions. On the proposed benchmark, we discover the failure of existing FCE methods to detect the logical fallacy, which refers to a mismatch of logic structures between the answer and the retrieved reference. To fix this issue, we further propose a new method called \emph{L-Face4RAG} with two novel designs of logic-preserving answer decomposition and fact-logic FCE. Extensive experiments show L-Face4RAG substantially outperforms previous methods for factual inconsistency detection on a wide range of tasks, notably beyond the RAG task from which it is originally motivated. Both the benchmark and our proposed method are publicly available.\footnote{\url{https://huggingface.co/datasets/yq27/Face4RAG}\label{link_face4rag}}
FoRAG: Factuality-optimized Retrieval Augmented Generation for Web-enhanced Long-form Question Answering
Jun 19, 2024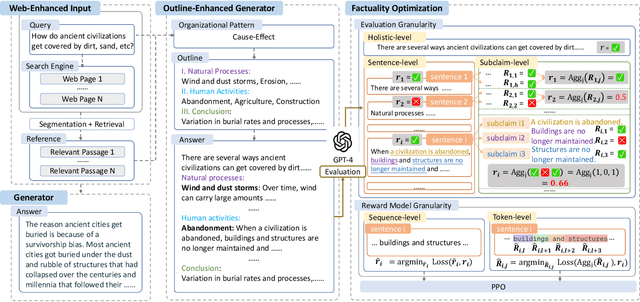
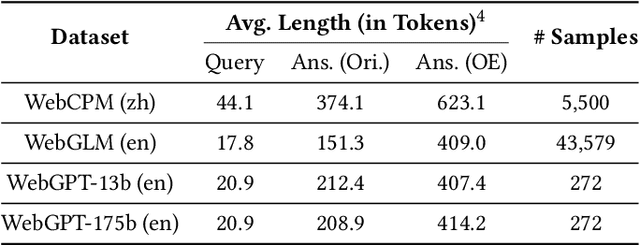

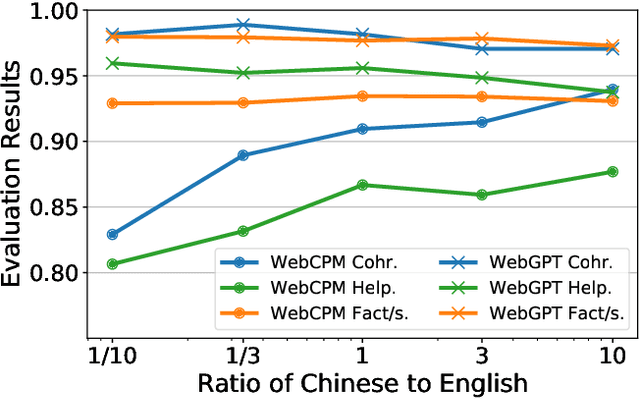
Retrieval Augmented Generation (RAG) has become prevalent in question-answering (QA) tasks due to its ability of utilizing search engine to enhance the quality of long-form question-answering (LFQA). Despite the emergence of various open source methods and web-enhanced commercial systems such as Bing Chat, two critical problems remain unsolved, i.e., the lack of factuality and clear logic in the generated long-form answers. In this paper, we remedy these issues via a systematic study on answer generation in web-enhanced LFQA. Specifically, we first propose a novel outline-enhanced generator to achieve clear logic in the generation of multifaceted answers and construct two datasets accordingly. Then we propose a factuality optimization method based on a carefully designed doubly fine-grained RLHF framework, which contains automatic evaluation and reward modeling in different levels of granularity. Our generic framework comprises conventional fine-grained RLHF methods as special cases. Extensive experiments verify the superiority of our proposed \textit{Factuality-optimized RAG (FoRAG)} method on both English and Chinese benchmarks. In particular, when applying our method to Llama2-7B-chat, the derived model FoRAG-L-7B outperforms WebGPT-175B in terms of three commonly used metrics (i.e., coherence, helpfulness, and factuality), while the number of parameters is much smaller (only 1/24 of that of WebGPT-175B). Our datasets and models are made publicly available for better reproducibility: https://huggingface.co/forag.
Mitigate Position Bias with Coupled Ranking Bias on CTR Prediction
May 29, 2024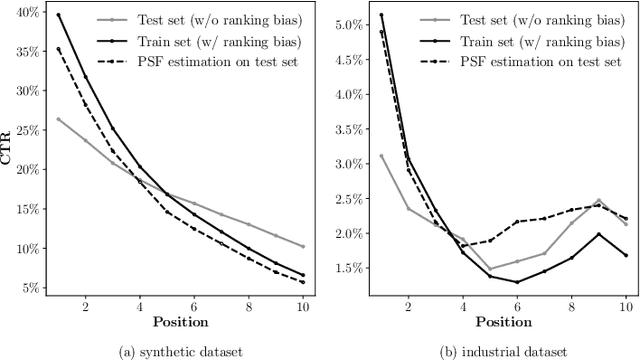

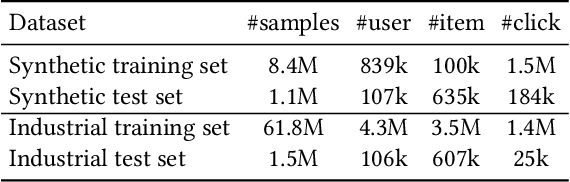
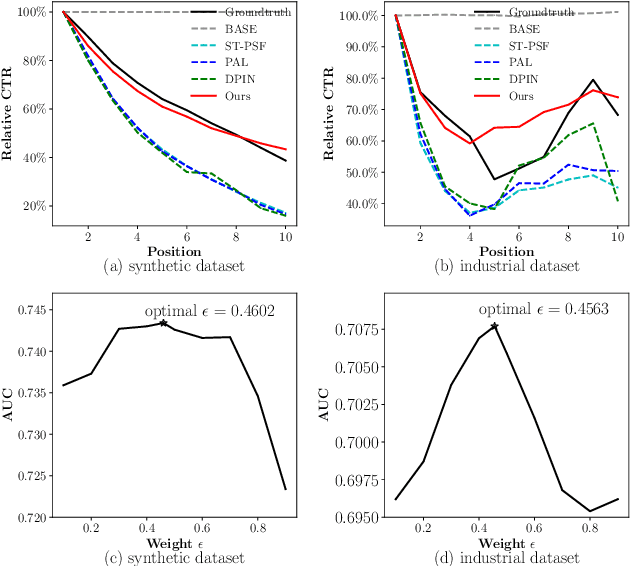
Position bias, i.e., users' preference of an item is affected by its placing position, is well studied in the recommender system literature. However, most existing methods ignore the widely coupled ranking bias, which is also related to the placing position of the item. Using both synthetic and industrial datasets, we first show how this widely coexisted ranking bias deteriorates the performance of the existing position bias estimation methods. To mitigate the position bias with the presence of the ranking bias, we propose a novel position bias estimation method, namely gradient interpolation, which fuses two estimation methods using a fusing weight. We further propose an adaptive method to automatically determine the optimal fusing weight. Extensive experiments on both synthetic and industrial datasets demonstrate the superior performance of the proposed methods.
ULMA: Unified Language Model Alignment with Demonstration and Point-wise Human Preference
Dec 05, 2023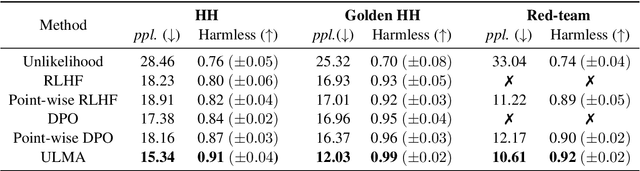
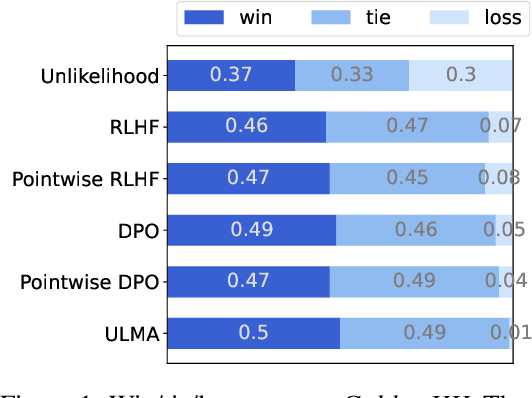
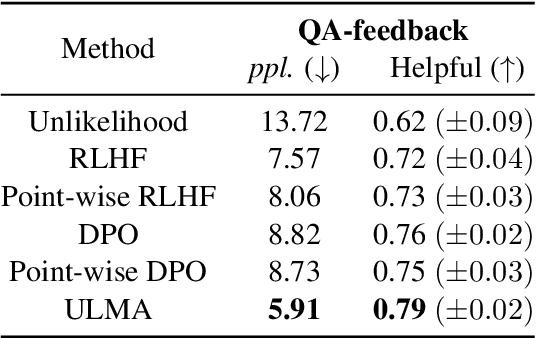
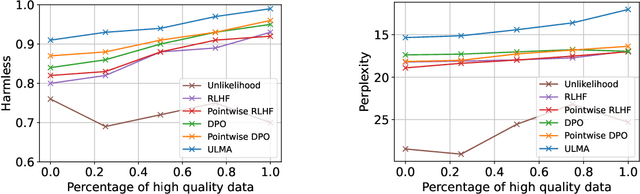
Language model alignment is a cutting-edge technique in large language model training to align the model output to user's intent, e.g., being helpful and harmless. Recent alignment framework consists of two steps: supervised fine-tuning with demonstration data and preference learning with human preference data. Previous preference learning methods, such as RLHF and DPO, mainly focus on pair-wise preference data. However, in many real-world scenarios where human feedbacks are intrinsically point-wise, these methods will suffer from information loss or even fail. To fill this gap, in this paper, we first develop a preference learning method called point-wise DPO to tackle point-wise preference data. Further revelation on the connection between supervised fine-tuning and point-wise preference learning enables us to develop a unified framework for both human demonstration and point-wise preference data, which sheds new light on the construction of preference dataset. Extensive experiments on point-wise datasets with binary or continuous labels demonstrate the superior performance and efficiency of our proposed methods. A new dataset with high-quality demonstration samples on harmlessness is constructed and made publicly available.
Marketing Budget Allocation with Offline Constrained Deep Reinforcement Learning
Sep 06, 2023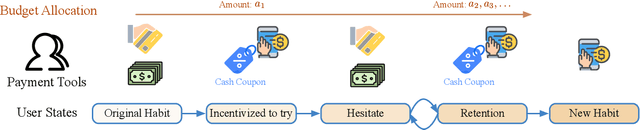
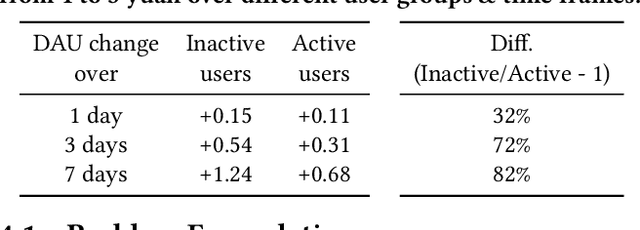
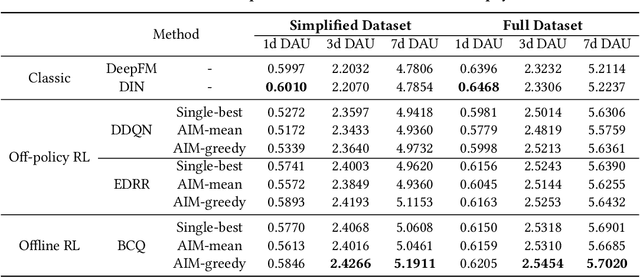
We study the budget allocation problem in online marketing campaigns that utilize previously collected offline data. We first discuss the long-term effect of optimizing marketing budget allocation decisions in the offline setting. To overcome the challenge, we propose a novel game-theoretic offline value-based reinforcement learning method using mixed policies. The proposed method reduces the need to store infinitely many policies in previous methods to only constantly many policies, which achieves nearly optimal policy efficiency, making it practical and favorable for industrial usage. We further show that this method is guaranteed to converge to the optimal policy, which cannot be achieved by previous value-based reinforcement learning methods for marketing budget allocation. Our experiments on a large-scale marketing campaign with tens-of-millions users and more than one billion budget verify the theoretical results and show that the proposed method outperforms various baseline methods. The proposed method has been successfully deployed to serve all the traffic of this marketing campaign.
Model-free Reinforcement Learning with Stochastic Reward Stabilization for Recommender Systems
Aug 25, 2023Model-free RL-based recommender systems have recently received increasing research attention due to their capability to handle partial feedback and long-term rewards. However, most existing research has ignored a critical feature in recommender systems: one user's feedback on the same item at different times is random. The stochastic rewards property essentially differs from that in classic RL scenarios with deterministic rewards, which makes RL-based recommender systems much more challenging. In this paper, we first demonstrate in a simulator environment where using direct stochastic feedback results in a significant drop in performance. Then to handle the stochastic feedback more efficiently, we design two stochastic reward stabilization frameworks that replace the direct stochastic feedback with that learned by a supervised model. Both frameworks are model-agnostic, i.e., they can effectively utilize various supervised models. We demonstrate the superiority of the proposed frameworks over different RL-based recommendation baselines with extensive experiments on a recommendation simulator as well as an industrial-level recommender system.
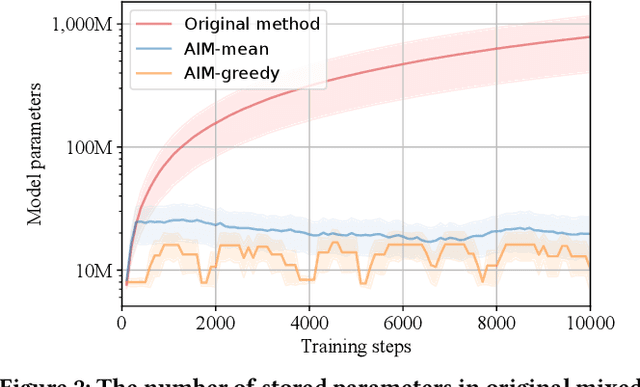
A Policy Efficient Reduction Approach to Convex Constrained Deep Reinforcement Learning
Aug 29, 2021
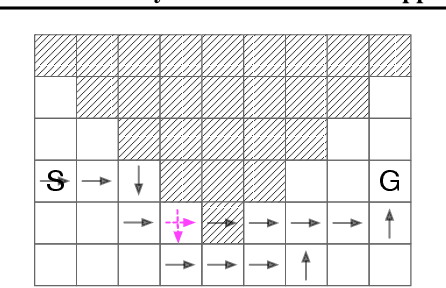
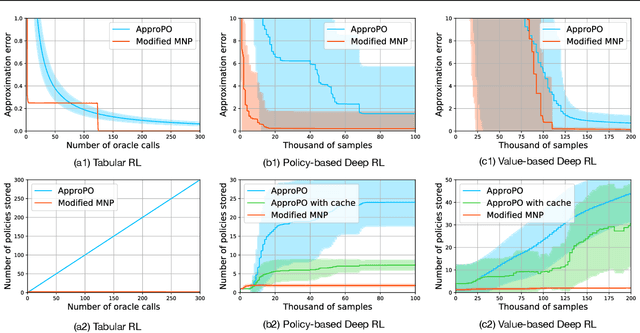

Although well-established in general reinforcement learning (RL), value-based methods are rarely explored in constrained RL (CRL) for their incapability of finding policies that can randomize among multiple actions. To apply value-based methods to CRL, a recent groundbreaking line of game-theoretic approaches uses the mixed policy that randomizes among a set of carefully generated policies to converge to the desired constraint-satisfying policy. However, these approaches require storing a large set of policies, which is not policy efficient, and may incur prohibitive memory costs in constrained deep RL. To address this problem, we propose an alternative approach. Our approach first reformulates the CRL to an equivalent distance optimization problem. With a specially designed linear optimization oracle, we derive a meta-algorithm that solves it using any off-the-shelf RL algorithm and any conditional gradient (CG) type algorithm as subroutines. We then propose a new variant of the CG-type algorithm, which generalizes the minimum norm point (MNP) method. The proposed method matches the convergence rate of the existing game-theoretic approaches and achieves the worst-case optimal policy efficiency. The experiments on a navigation task show that our method reduces the memory costs by an order of magnitude, and meanwhile achieves better performance, demonstrating both its effectiveness and efficiency.
LinkLouvain: Link-Aware A/B Testing and Its Application on Online Marketing Campaign
Feb 03, 2021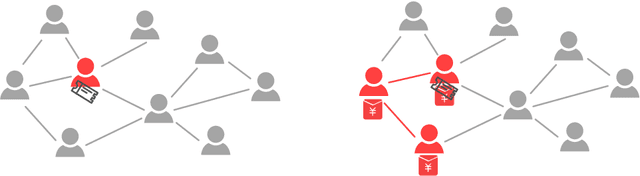
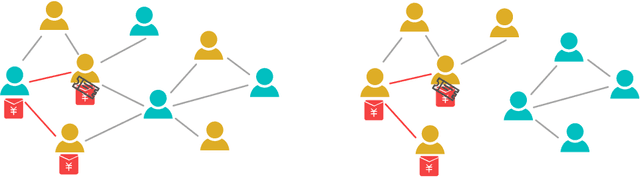
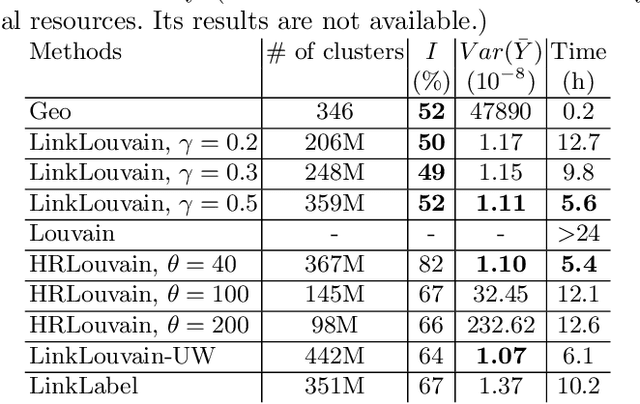
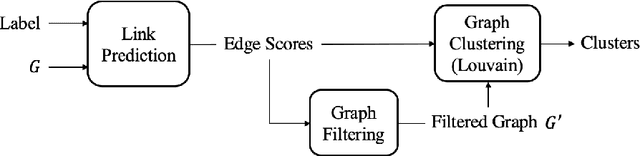
A lot of online marketing campaigns aim to promote user interaction. The average treatment effect (ATE) of campaign strategies need to be monitored throughout the campaign. A/B testing is usually conducted for such needs, whereas the existence of user interaction can introduce interference to normal A/B testing. With the help of link prediction, we design a network A/B testing method LinkLouvain to minimize graph interference and it gives an accurate and sound estimate of the campaign's ATE. In this paper, we analyze the network A/B testing problem under a real-world online marketing campaign, describe our proposed LinkLouvain method, and evaluate it on real-world data. Our method achieves significant performance compared with others and is deployed in the online marketing campaign.