 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentiable Collision-Supervised Tooth Arrangement Network with a Decoupling Perspective
Sep 18, 2024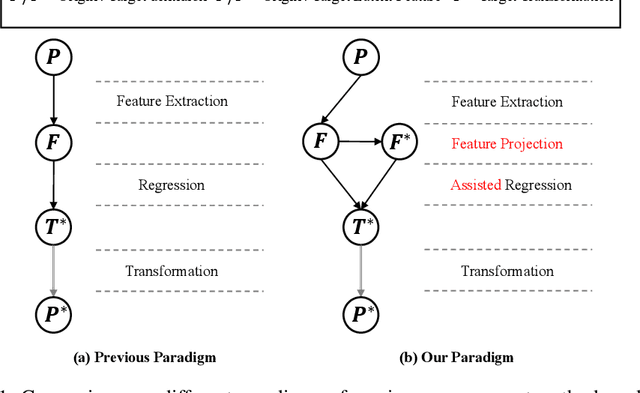

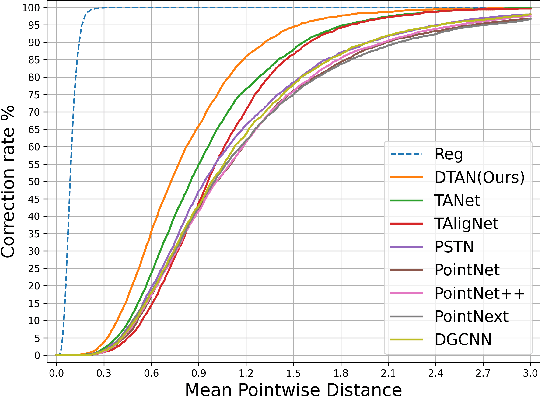

Tooth arrangement is an essential step in the digital orthodontic planning process. Existing learning-based methods use hidden teeth features to directly regress teeth motions, which couples target pose perception and motion regression. It could lead to poor perceptions of three-dimensional transformation. They also ignore the possible overlaps or gaps between teeth of predicted dentition, which is generally unacceptable. Therefore, we propose DTAN, a differentiable collision-supervised tooth arrangement network, decoupling predicting tasks and feature modeling. DTAN decouples the tooth arrangement task by first predicting the hidden features of the final teeth poses and then using them to assist in regressing the motions between the beginning and target teeth. To learn the hidden features better, DTAN also decouples the teeth-hidden features into geometric and positional features, which are further supervised by feature consistency constraints. Furthermore, we propose a novel differentiable collision loss function for point cloud data to constrain the related gestures between teeth, which can be easily extended to other 3D point cloud tasks. We propose an arch-width guided tooth arrangement network, named C-DTAN, to make the results controllable. We construct three different tooth arrangement datasets and achieve drastically improved performance on accuracy and speed compared with existing methods.
MiniCPM-V: A GPT-4V Level MLLM on Your Phone
Aug 03, 2024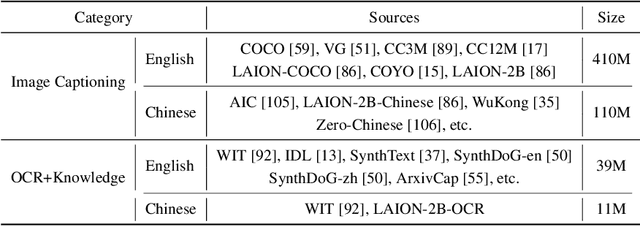

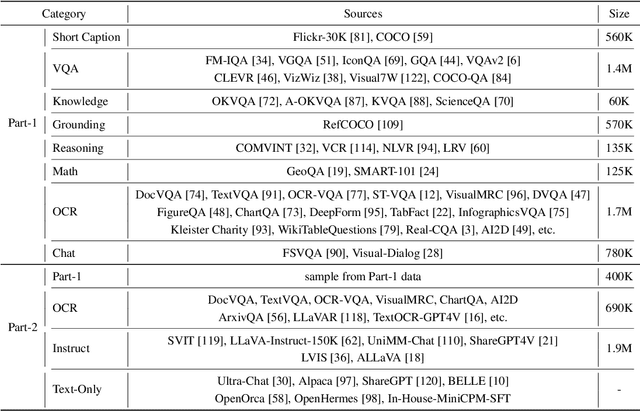
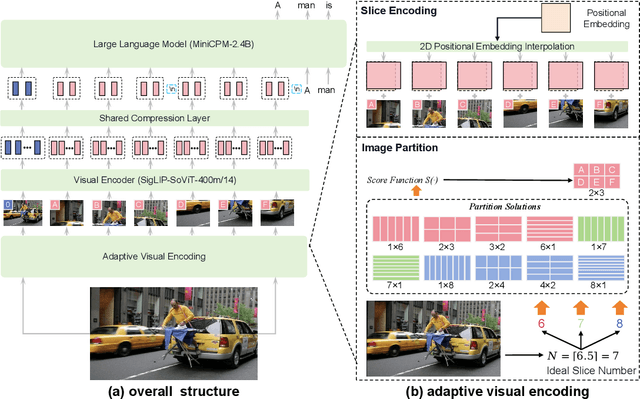
The recent surge of Multimodal Large Language Models (MLLMs) has fundamentally reshaped the landscape of AI research and industry, shedding light on a promising path toward the next AI milestone. However, significant challenges remain preventing MLLMs from being practical in real-world applications. The most notable challenge comes from the huge cost of running an MLLM with a massive number of parameters and extensive computation. As a result, most MLLMs need to be deployed on high-performing cloud servers, which greatly limits their application scopes such as mobile, offline, energy-sensitive, and privacy-protective scenarios. In this work, we present MiniCPM-V, a series of efficient MLLMs deployable on end-side devices. By integrating the latest MLLM techniques in architecture, pretraining and alignment, the latest MiniCPM-Llama3-V 2.5 has several notable features: (1) Strong performance, outperforming GPT-4V-1106, Gemini Pro and Claude 3 on OpenCompass, a comprehensive evaluation over 11 popular benchmarks, (2) strong OCR capability and 1.8M pixel high-resolution image perception at any aspect ratio, (3) trustworthy behavior with low hallucination rates, (4) multilingual support for 30+ languages, and (5) efficient deployment on mobile phones. More importantly, MiniCPM-V can be viewed as a representative example of a promising trend: The model sizes for achieving usable (e.g., GPT-4V) level performance are rapidly decreasing, along with the fast growth of end-side computation capacity. This jointly shows that GPT-4V level MLLMs deployed on end devices are becoming increasingly possible, unlocking a wider spectrum of real-world AI applications in the near future.