 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMiniCPM-V: A GPT-4V Level MLLM on Your Phone
Aug 03, 2024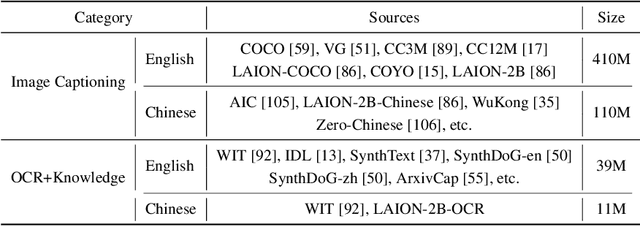

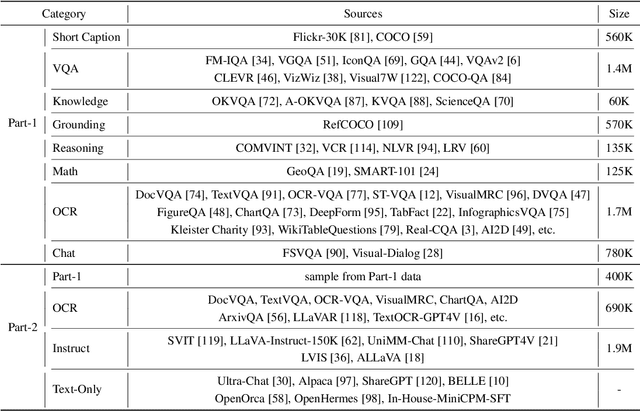
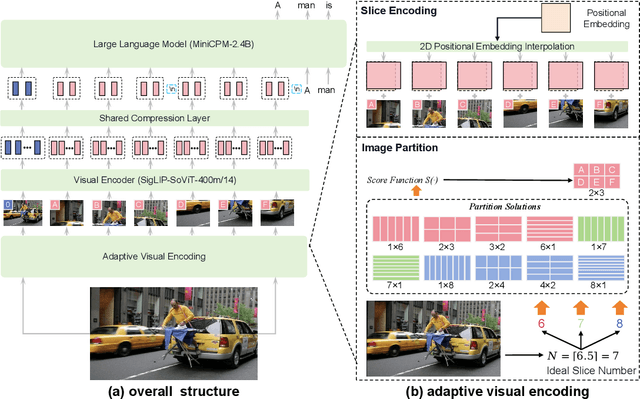
The recent surge of Multimodal Large Language Models (MLLMs) has fundamentally reshaped the landscape of AI research and industry, shedding light on a promising path toward the next AI milestone. However, significant challenges remain preventing MLLMs from being practical in real-world applications. The most notable challenge comes from the huge cost of running an MLLM with a massive number of parameters and extensive computation. As a result, most MLLMs need to be deployed on high-performing cloud servers, which greatly limits their application scopes such as mobile, offline, energy-sensitive, and privacy-protective scenarios. In this work, we present MiniCPM-V, a series of efficient MLLMs deployable on end-side devices. By integrating the latest MLLM techniques in architecture, pretraining and alignment, the latest MiniCPM-Llama3-V 2.5 has several notable features: (1) Strong performance, outperforming GPT-4V-1106, Gemini Pro and Claude 3 on OpenCompass, a comprehensive evaluation over 11 popular benchmarks, (2) strong OCR capability and 1.8M pixel high-resolution image perception at any aspect ratio, (3) trustworthy behavior with low hallucination rates, (4) multilingual support for 30+ languages, and (5) efficient deployment on mobile phones. More importantly, MiniCPM-V can be viewed as a representative example of a promising trend: The model sizes for achieving usable (e.g., GPT-4V) level performance are rapidly decreasing, along with the fast growth of end-side computation capacity. This jointly shows that GPT-4V level MLLMs deployed on end devices are becoming increasingly possible, unlocking a wider spectrum of real-world AI applications in the near future.
GUICourse: From General Vision Language Models to Versatile GUI Agents
Jun 17, 2024
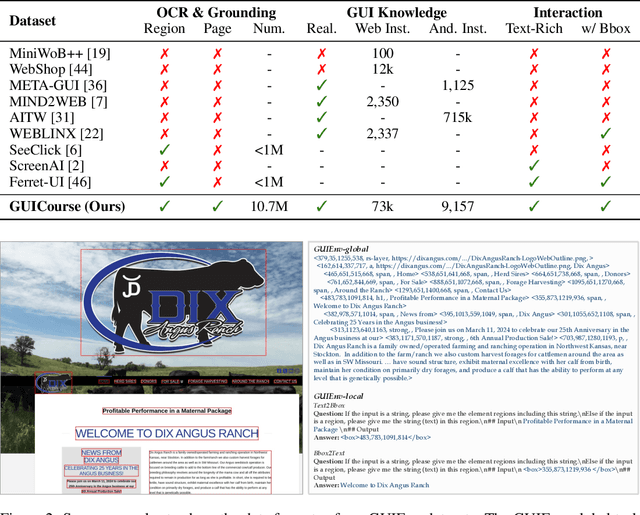
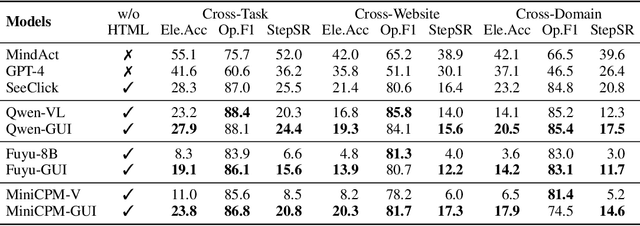
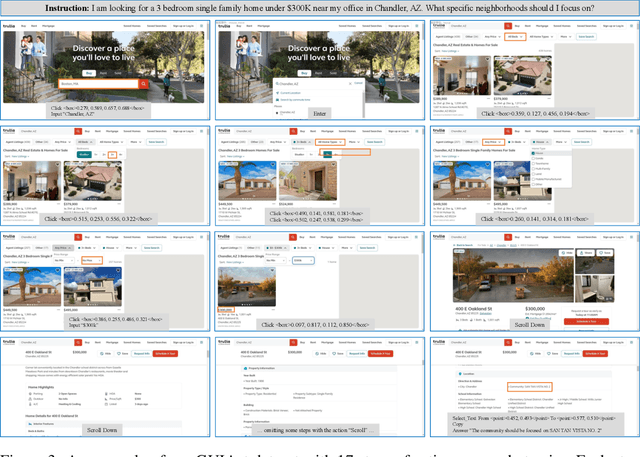
Utilizing Graphic User Interface (GUI) for human-computer interaction is essential for accessing a wide range of digital tools. Recent advancements in Vision Language Models (VLMs) highlight the compelling potential to develop versatile agents to help humans finish GUI navigation tasks. However, current VLMs are challenged in terms of fundamental abilities (OCR and grounding) and GUI knowledge (the functions and control methods of GUI elements), preventing them from becoming practical GUI agents. To solve these challenges, we contribute GUICourse, a suite of datasets to train visual-based GUI agents from general VLMs. First, we introduce the GUIEnv dataset to strengthen the OCR and grounding capabilities of VLMs. Then, we introduce the GUIAct and GUIChat datasets to enrich their knowledge of GUI components and interactions. Experiments demonstrate that our GUI agents have better performance on common GUI tasks than their baseline VLMs. Even the small-size GUI agent (with 3.1B parameters) can still work well on single-step and multi-step GUI tasks. Finally, we analyze the different varieties in the training stage of this agent by ablation study. Our source codes and datasets are released at https://github.com/yiye3/GUICourse.
MiniCPM: Unveiling the Potential of Small Language Models with Scalable Training Strategies
Apr 09, 2024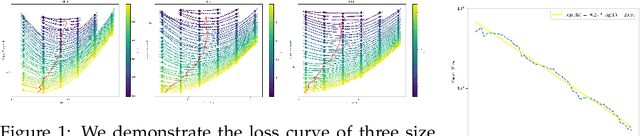


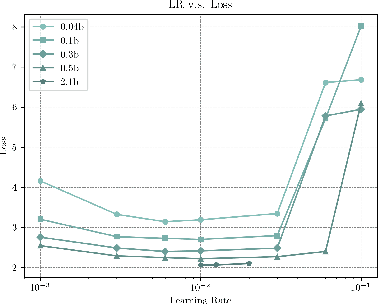
The burgeoning interest in developing Large Language Models (LLMs) with up to trillion parameters has been met with concerns regarding resource efficiency and practical expense, particularly given the immense cost of experimentation. This scenario underscores the importance of exploring the potential of Small Language Models (SLMs) as a resource-efficient alternative. In this context, we introduce MiniCPM, specifically the 1.2B and 2.4B non-embedding parameter variants, not only excel in their respective categories but also demonstrate capabilities on par with 7B-13B LLMs. While focusing on SLMs, our approach exhibits scalability in both model and data dimensions for future LLM research. Regarding model scaling, we employ extensive model wind tunnel experiments for stable and optimal scaling. For data scaling, we introduce a Warmup-Stable-Decay (WSD) learning rate scheduler (LRS), conducive to continuous training and domain adaptation. We present an in-depth analysis of the intriguing training dynamics that occurred in the WSD LRS. With WSD LRS, we are now able to efficiently study data-model scaling law without extensive retraining experiments on both axes of model and data, from which we derive the much higher compute optimal data-model ratio than Chinchilla Optimal. Additionally, we introduce MiniCPM family, including MiniCPM-DPO, MiniCPM-MoE and MiniCPM-128K, whose excellent performance further cementing MiniCPM's foundation in diverse SLM applications. MiniCPM models are available publicly at https://github.com/OpenBMB/MiniCPM .
Reformulating Vision-Language Foundation Models and Datasets Towards Universal Multimodal Assistants
Oct 01, 2023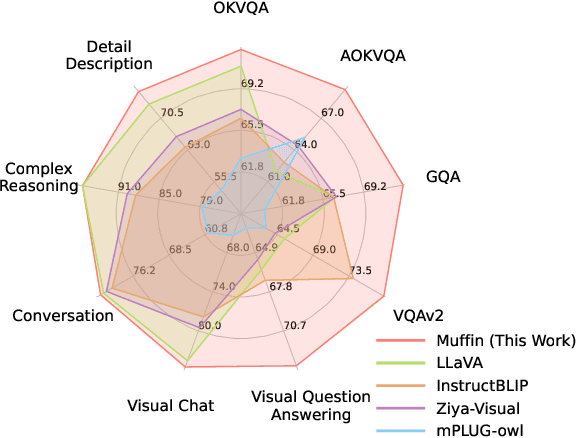
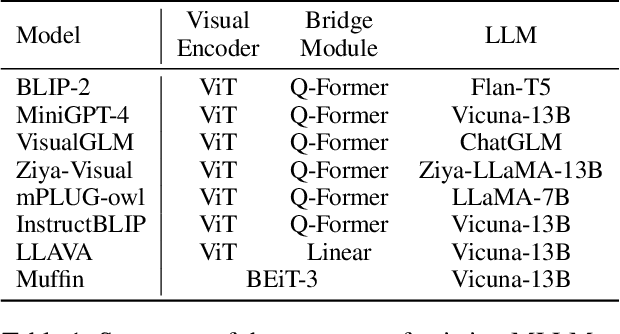
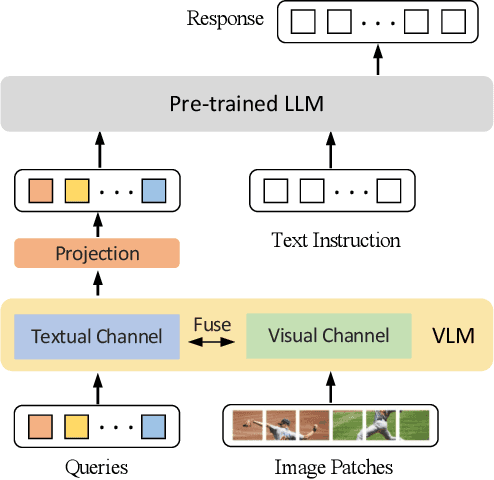
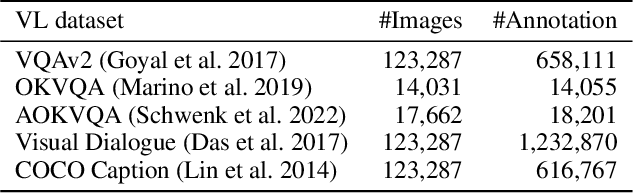
Recent Multimodal Large Language Models (MLLMs) exhibit impressive abilities to perceive images and follow open-ended instructions. The capabilities of MLLMs depend on two crucial factors: the model architecture to facilitate the feature alignment of visual modules and large language models; the multimodal instruction tuning datasets for human instruction following. (i) For the model architecture, most existing models introduce an external bridge module to connect vision encoders with language models, which needs an additional feature-alignment pre-training. In this work, we discover that compact pre-trained vision language models can inherently serve as ``out-of-the-box'' bridges between vision and language. Based on this, we propose Muffin framework, which directly employs pre-trained vision-language models to act as providers of visual signals. (ii) For the multimodal instruction tuning datasets, existing methods omit the complementary relationship between different datasets and simply mix datasets from different tasks. Instead, we propose UniMM-Chat dataset which explores the complementarities of datasets to generate 1.1M high-quality and diverse multimodal instructions. We merge information describing the same image from diverse datasets and transforms it into more knowledge-intensive conversation data. Experimental results demonstrate the effectiveness of the Muffin framework and UniMM-Chat dataset. Muffin achieves state-of-the-art performance on a wide range of vision-language tasks, significantly surpassing state-of-the-art models like LLaVA and InstructBLIP. Our model and dataset are all accessible at https://github.com/thunlp/muffin.
Large Multilingual Models Pivot Zero-Shot Multimodal Learning across Languages
Aug 23, 2023



Recently there has been a significant surge in multimodal learning in terms of both image-to-text and text-to-image generation. However, the success is typically limited to English, leaving other languages largely behind. Building a competitive counterpart in other languages is highly challenging due to the low-resource nature of non-English multimodal data (i.e., lack of large-scale, high-quality image-text data). In this work, we propose MPM, an effective training paradigm for training large multimodal models in low-resource languages. MPM demonstrates that Multilingual language models can Pivot zero-shot Multimodal learning across languages. Specifically, based on a strong multilingual large language model, multimodal models pretrained on English-only image-text data can well generalize to other languages in a zero-shot manner for both image-to-text and text-to-image generation, even surpassing models trained on image-text data in native languages. Taking Chinese as a practice of MPM, we build large multimodal models VisCPM in image-to-text and text-to-image generation, which achieve state-of-the-art (open-source) performance in Chinese. To facilitate future research, we open-source codes and model weights at https://github.com/OpenBMB/VisCPM.git.