 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinual Learning for fMRI-Based Brain Disorder Diagnosis via Functional Connectivity Matrices Generative Replay
Apr 15, 2026Functional magnetic resonance imaging (fMRI) is widely used for studying and diagnosing brain disorders, with functional connectivity (FC) matrices providing powerful representations of large-scale neural interactions. However, existing diagnostic models are trained either on a single site or under full multi-site access, making them unsuitable for real-world scenarios where clinical data arrive sequentially from different institutions. This results in limited generalization and severe catastrophic forgetting. This paper presents the first continual learning framework specifically designed for fMRI-based diagnosis across heterogeneous clinical sites. Our framework introduces a structure-aware variational autoencoder that synthesizes realistic FC matrices for both patient and control groups. Built on this generative backbone, we develop a multi-level knowledge distillation strategy that aligns predictions and graph representations between new-site data and replayed samples. To further enhance efficiency, we incorporate a hierarchical contextual bandit scheme for adaptive replay sampling. Experiments on multi-site datasets for major depressive disorder (MDD), schizophrenia (SZ), and autism spectrum disorder (ASD) show that the proposed generative model enhances data augmentation quality, and the overall continual learning framework substantially outperforms existing methods in mitigating catastrophic forgetting. Our code is available at https://github.com/4me808/FORGE.
Context Tokens are Anchors: Understanding the Repetition Curse in dMLLMs from an Information Flow Perspective
Jan 28, 2026Recent diffusion-based Multimodal Large Language Models (dMLLMs) suffer from high inference latency and therefore rely on caching techniques to accelerate decoding. However, the application of cache mechanisms often introduces undesirable repetitive text generation, a phenomenon we term the \textbf{Repeat Curse}. To better investigate underlying mechanism behind this issue, we analyze repetition generation through the lens of information flow. Our work reveals three key findings: (1) context tokens aggregate semantic information as anchors and guide the final predictions; (2) as information propagates across layers, the entropy of context tokens converges in deeper layers, reflecting the model's growing prediction certainty; (3) Repetition is typically linked to disruptions in the information flow of context tokens and to the inability of their entropy to converge in deeper layers. Based on these insights, we present \textbf{CoTA}, a plug-and-play method for mitigating repetition. CoTA enhances the attention of context tokens to preserve intrinsic information flow patterns, while introducing a penalty term to the confidence score during decoding to avoid outputs driven by uncertain context tokens. With extensive experiments, CoTA demonstrates significant effectiveness in alleviating repetition and achieves consistent performance improvements on general tasks. Code is available at https://github.com/ErikZ719/CoTA
OAH-Net: A Deep Neural Network for Hologram Reconstruction of Off-axis Digital Holographic Microscope
Oct 17, 2024
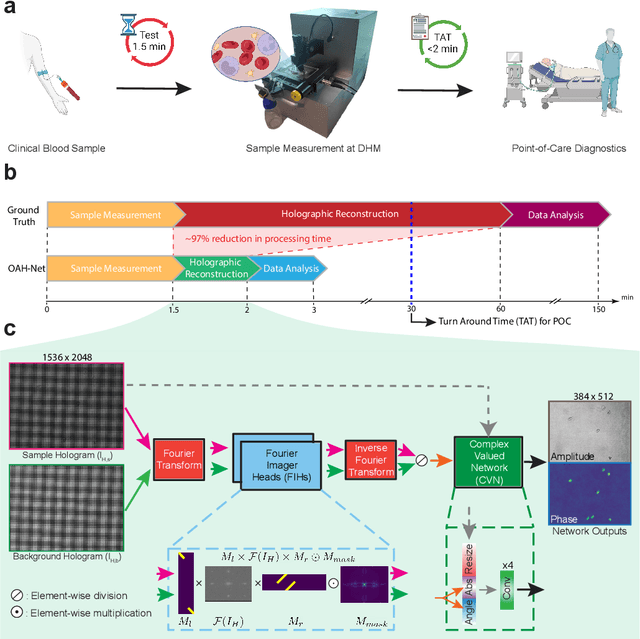

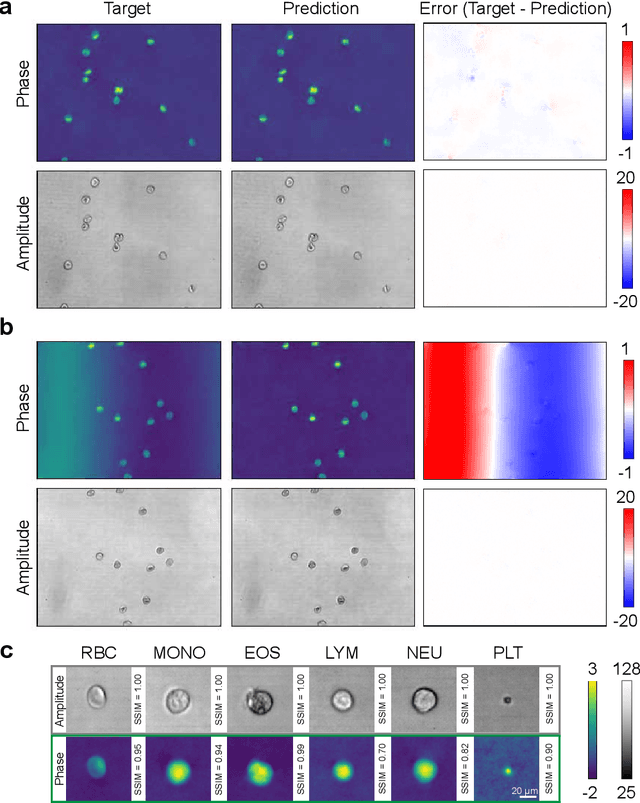
Off-axis digital holographic microscopy is a high-throughput, label-free imaging technology that provides three-dimensional, high-resolution information about samples, particularly useful in large-scale cellular imaging. However, the hologram reconstruction process poses a significant bottleneck for timely data analysis. To address this challenge, we propose a novel reconstruction approach that integrates deep learning with the physical principles of off-axis holography. We initialized part of the network weights based on the physical principle and then fine-tuned them via weakly supersized learning. Our off-axis hologram network (OAH-Net) retrieves phase and amplitude images with errors that fall within the measurement error range attributable to hardware, and its reconstruction speed significantly surpasses the microscope's acquisition rate. Crucially, OAH-Net demonstrates remarkable external generalization capabilities on unseen samples with distinct patterns and can be seamlessly integrated with other models for downstream tasks to achieve end-to-end real-time hologram analysis. This capability further expands off-axis holography's applications in both biological and medical studies.
MiniCPM-V: A GPT-4V Level MLLM on Your Phone
Aug 03, 2024

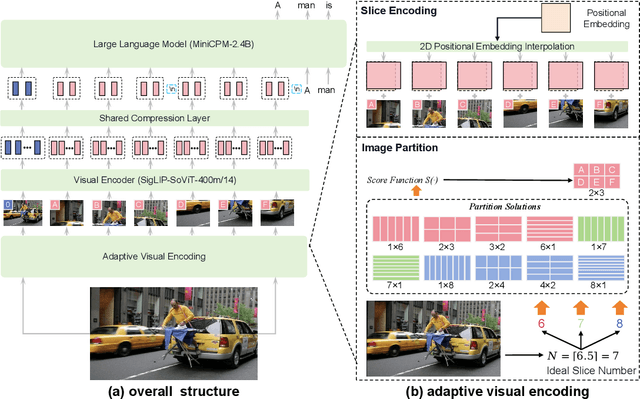
The recent surge of Multimodal Large Language Models (MLLMs) has fundamentally reshaped the landscape of AI research and industry, shedding light on a promising path toward the next AI milestone. However, significant challenges remain preventing MLLMs from being practical in real-world applications. The most notable challenge comes from the huge cost of running an MLLM with a massive number of parameters and extensive computation. As a result, most MLLMs need to be deployed on high-performing cloud servers, which greatly limits their application scopes such as mobile, offline, energy-sensitive, and privacy-protective scenarios. In this work, we present MiniCPM-V, a series of efficient MLLMs deployable on end-side devices. By integrating the latest MLLM techniques in architecture, pretraining and alignment, the latest MiniCPM-Llama3-V 2.5 has several notable features: (1) Strong performance, outperforming GPT-4V-1106, Gemini Pro and Claude 3 on OpenCompass, a comprehensive evaluation over 11 popular benchmarks, (2) strong OCR capability and 1.8M pixel high-resolution image perception at any aspect ratio, (3) trustworthy behavior with low hallucination rates, (4) multilingual support for 30+ languages, and (5) efficient deployment on mobile phones. More importantly, MiniCPM-V can be viewed as a representative example of a promising trend: The model sizes for achieving usable (e.g., GPT-4V) level performance are rapidly decreasing, along with the fast growth of end-side computation capacity. This jointly shows that GPT-4V level MLLMs deployed on end devices are becoming increasingly possible, unlocking a wider spectrum of real-world AI applications in the near future.
CoCoCo: Improving Text-Guided Video Inpainting for Better Consistency, Controllability and Compatibility
Mar 18, 2024Recent advancements in video generation have been remarkable, yet many existing methods struggle with issues of consistency and poor text-video alignment. Moreover, the field lacks effective techniques for text-guided video inpainting, a stark contrast to the well-explored domain of text-guided image inpainting. To this end, this paper proposes a novel text-guided video inpainting model that achieves better consistency, controllability and compatibility. Specifically, we introduce a simple but efficient motion capture module to preserve motion consistency, and design an instance-aware region selection instead of a random region selection to obtain better textual controllability, and utilize a novel strategy to inject some personalized models into our CoCoCo model and thus obtain better model compatibility. Extensive experiments show that our model can generate high-quality video clips. Meanwhile, our model shows better motion consistency, textual controllability and model compatibility. More details are shown in [cococozibojia.github.io](cococozibojia.github.io).
MLLM-Tool: A Multimodal Large Language Model For Tool Agent Learning
Jan 24, 2024



Recently, the astonishing performance of large language models (LLMs) in natural language comprehension and generation tasks triggered lots of exploration of using them as central controllers to build agent systems. Multiple studies focus on bridging the LLMs to external tools to extend the application scenarios. However, the current LLMs' perceiving tool-use ability is limited to a single text query, which may result in ambiguity in understanding the users' real intentions. LLMs are expected to eliminate that by perceiving the visual- or auditory-grounded instructions' information. Therefore, in this paper, we propose MLLM-Tool, a system incorporating open-source LLMs and multi-modal encoders so that the learnt LLMs can be conscious of multi-modal input instruction and then select the function-matched tool correctly. To facilitate the evaluation of the model's capability, we collect a dataset featured by consisting of multi-modal input tools from HuggingFace. Another important feature of our dataset is that our dataset also contains multiple potential choices for the same instruction due to the existence of identical functions and synonymous functions, which provides more potential solutions for the same query. The experiments reveal that our MLLM-Tool is capable of recommending appropriate tools for multi-modal instructions. Codes and data are available at https://github.com/MLLM-Tool/MLLM-Tool.
Large Multilingual Models Pivot Zero-Shot Multimodal Learning across Languages
Aug 23, 2023



Recently there has been a significant surge in multimodal learning in terms of both image-to-text and text-to-image generation. However, the success is typically limited to English, leaving other languages largely behind. Building a competitive counterpart in other languages is highly challenging due to the low-resource nature of non-English multimodal data (i.e., lack of large-scale, high-quality image-text data). In this work, we propose MPM, an effective training paradigm for training large multimodal models in low-resource languages. MPM demonstrates that Multilingual language models can Pivot zero-shot Multimodal learning across languages. Specifically, based on a strong multilingual large language model, multimodal models pretrained on English-only image-text data can well generalize to other languages in a zero-shot manner for both image-to-text and text-to-image generation, even surpassing models trained on image-text data in native languages. Taking Chinese as a practice of MPM, we build large multimodal models VisCPM in image-to-text and text-to-image generation, which achieve state-of-the-art (open-source) performance in Chinese. To facilitate future research, we open-source codes and model weights at https://github.com/OpenBMB/VisCPM.git.
PEVL: Position-enhanced Pre-training and Prompt Tuning for Vision-language Models
May 23, 2022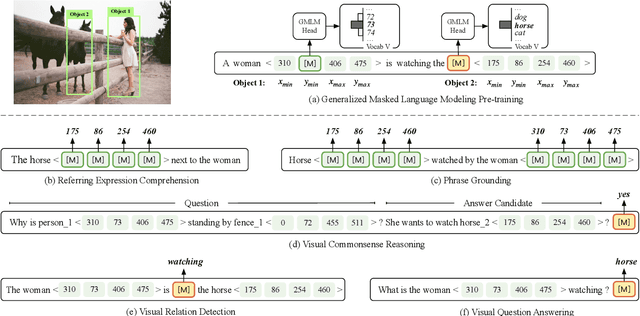
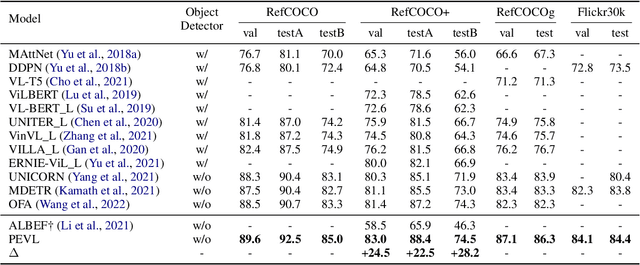
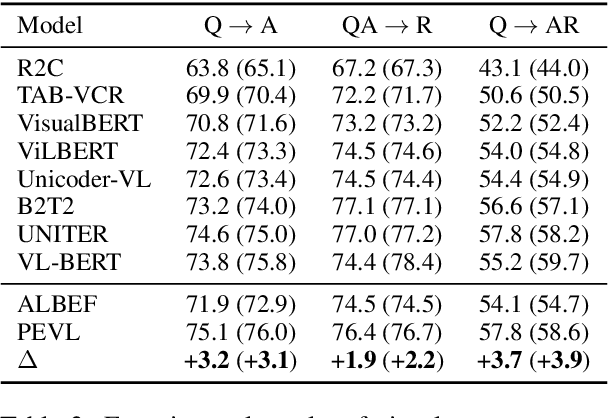

Vision-language pre-training (VLP) has shown impressive performance on a wide range of cross-modal tasks, where VLP models without reliance on object detectors are becoming the mainstream due to their superior computation efficiency and competitive performance. However, the removal of object detectors also deprives the capability of VLP models in explicit object modeling, which is essential to various position-sensitive vision-language (VL) tasks, such as referring expression comprehension and visual commonsense reasoning. To address the challenge, we introduce PEVL that enhances the pre-training and prompt tuning of VLP models with explicit object position modeling. Specifically, PEVL reformulates discretized object positions and language in a unified language modeling framework, which facilitates explicit VL alignment during pre-training, and also enables flexible prompt tuning for various downstream tasks. We show that PEVL enables state-of-the-art performance of detector-free VLP models on position-sensitive tasks such as referring expression comprehension and phrase grounding, and also improves the performance on position-insensitive tasks with grounded inputs. We make the data and code for this paper publicly available at https://github.com/thunlp/PEVL.
Fine-Grained Scene Graph Generation with Data Transfer
Mar 22, 2022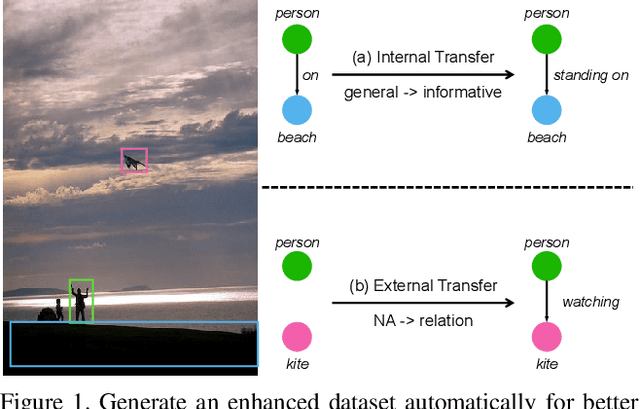
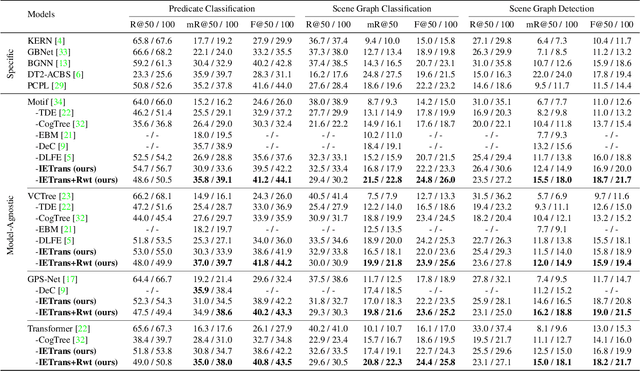
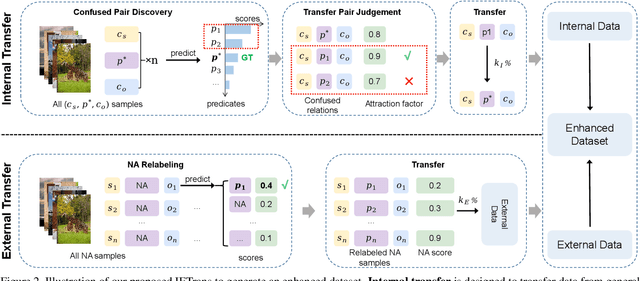
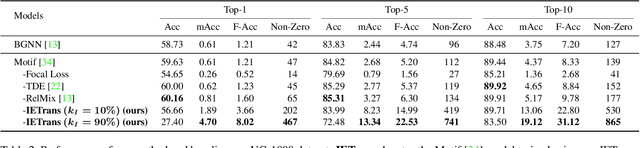
Scene graph generation (SGG) aims to extract (subject, predicate, object) triplets in images. Recent works have made a steady progress on SGG, and provide useful tools for high-level vision and language understanding. However, due to the data distribution problems including long-tail distribution and semantic ambiguity, the predictions of current SGG models tend to collapse to several frequent but uninformative predicates (e.g., \textit{on}, \textit{at}), which limits practical application of these models in downstream tasks. To deal with the problems above, we propose a novel Internal and External Data Transfer (IETrans) method, which can be applied in a play-and-plug fashion and expanded to large SGG with 1,807 predicate classes. Our IETrans tries to relieve the data distribution problem by automatically creating an enhanced dataset that provides more sufficient and coherent annotations for all predicates. By training on the transferred dataset, a Neural Motif model doubles the macro performance while maintaining competitive micro performance. The data and code for this paper are publicly available at \url{https://github.com/waxnkw/IETrans-SGG.pytorch}